Google’s EmbeddingGemma isn’t just another model release, it’s a direct assault on the cloud-first AI paradigm that’s dominated for years. At 300M parameters, this open embedding model achieves what previously required server farms: state-of-the-art multilingual understanding that fits in your pocket.
The On-Device Revolution Nobody Saw Coming
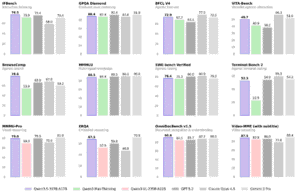
While everyone was chasing trillion-parameter cloud models, Google quietly built a 300M parameter embedding model that outperforms competitors nearly twice its size on the Massive Text Embedding Benchmark. The implications are staggering: EmbeddingGemma delivers 68.36 mean score on English tasks and 61.15 on multilingual benchmarks while consuming less than 200MB of RAM when quantized.
The real kicker? It processes 256 tokens in under 15ms on EdgeTPU hardware. That’s real-time semantic search without internet connectivity, something that was pure science fiction just two years ago.
Why Cloud Providers Should Be Nervous
EmbeddingGemma’s architecture reveals Google’s endgame: 100M model parameters paired with 200M embedding parameters, all optimized through Matryoshka Representation Learning. This lets developers truncate output dimensions from 768 down to 128 based on their precision needs, trading minimal accuracy loss for massive speed gains.

The model’s training data tells the real story: 320 billion tokens spanning 100+ languages, with rigorous filtering for CSAM and sensitive information. Unlike cloud alternatives, EmbeddingGemma processes everything locally, your personal emails, documents, and search queries never leave the device.
This creates an ironic twist: Google, the company that built its empire on cloud data collection, is now providing the tools to keep that data completely private.
The Developer Landscape Shifts Overnight

EmbeddingGemma launched with immediate support across the entire development stack: Hugging Face, Ollama, sentence-transformers, llama.cpp, MLX, and even transformers.js for browser deployment. The message is clear: Google wants this everywhere, immediately.
The integration strategy is brutally efficient. By using the same tokenizer as Gemma 3n, they’ve created a seamless on-device RAG pipeline that eliminates cloud dependencies entirely. Developers can now build:
- Offline semantic search across personal files and messages
- Privacy-preserving chatbots that never phone home
- Real-time multilingual translation without data leaving the device
- Classification systems that work in airgap environments
The Benchmark That Changes Everything
EmbeddingGemma’s MTEB results aren’t just good, they’re disruptive. With scores that rival models twice its size, it demonstrates that parameter count isn’t everything. The secret sauce appears to be the T5Gemma initialization and Gemini research transfer, proving that architectural efficiency beats brute force scaling.
The quantization story is equally impressive: Q8_0 quantization maintains 68.13 on English benchmarks while cutting memory requirements by 60%. For mobile developers, this means enterprise-grade AI on hardware that’s already in billions of pockets worldwide.
The Coming Privacy Revolution
Google’s timing is impeccable. As regulators worldwide crack down on data transfers and cloud surveillance, EmbeddingGemma offers a clean alternative: all processing occurs on-device, with embeddings that never touch external servers.
This creates a fascinating tension: the same company that monetizes cloud data is providing the tools to make that model obsolete. Either Google sees the regulatory writing on the wall, or they’re playing a much longer game around device-based AI services.
The model’s immediate availability suggests they’re serious, this isn’t a research project. It’s a production-ready tool that’s already integrated into Android’s AI stack, signaling where Google believes the next decade of AI innovation will occur: not in massive data centers, but in the devices we carry every day.
The era of cloud-dependent AI is ending faster than anyone predicted. With EmbeddingGemma, Google didn’t just release another model, they fired the starting gun on the next AI revolution, and it’s happening right in your pocket.