Showing page 1 of 55
Hugging Face’s new open-source speech-to-speech pipeline challenges OpenAI’s Realtime API with a modular, local-first approach using Gemma 4 and Cerebras.
Kimi K2.7 Code is the first open-weight model in GitHub Copilot. A look at what it means for pricing, competition, and the future of AI coding assistants.
A practical guide to benchmarking open-source models for agentic tasks, with real data on how Kimi, GLM-5.2, and Ornith-1.0 are closing the gap to proprietary systems.
Review proposed code changes.
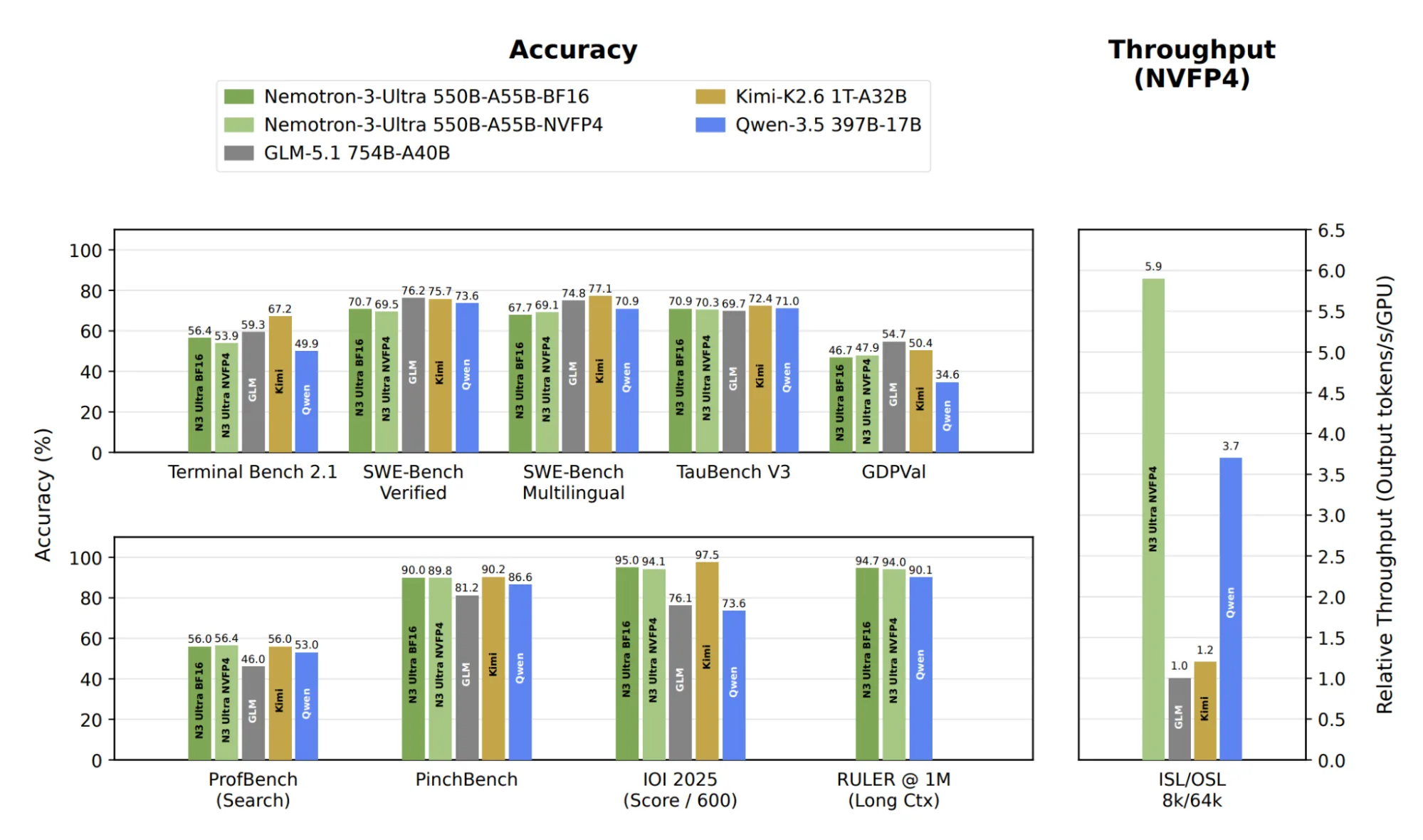
NVIDIA’s Qwen3.6-27B-NVFP4 squeezes a 27B model into 22GB while matching, and sometimes beating, FP8 accuracy. Here’s how the quantization magic works and why it matters for local LLM deployment.
The US government just asked OpenAI to vet GPT-5.6 users ‘customer by customer.’ This isn’t safety, it’s a power grab that could hand the AI ecosystem to China.
Apple skips M6 Pro and Max chips to fast-track the AI-focused M7. What this means for local inference, memory bandwidth, and the future of Mac.
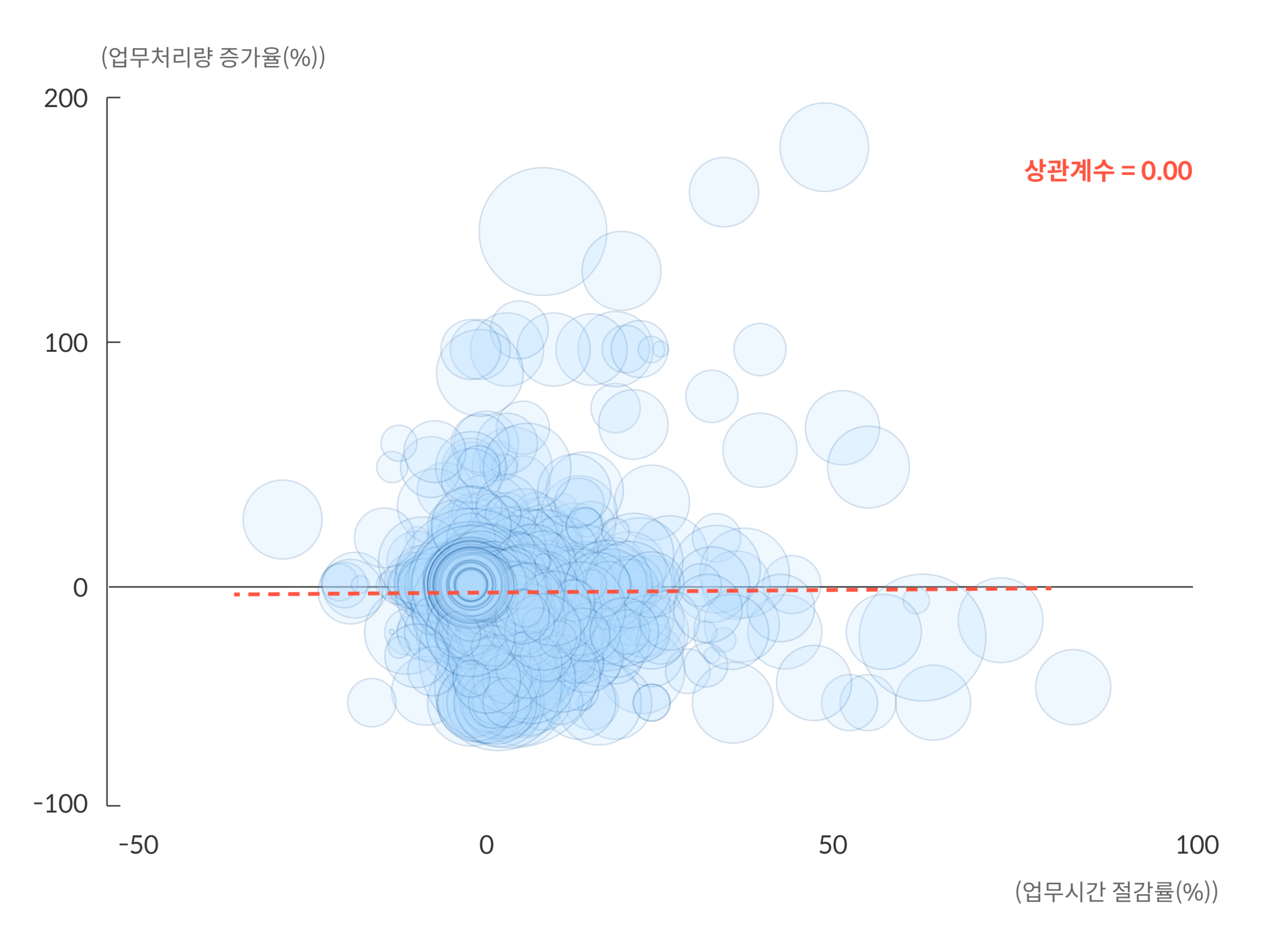
The Bank of Korea reports that AI saves workers only about one hour per week and finds zero correlation with increased output, challenging the productivity narrative pushed by US tech giants.
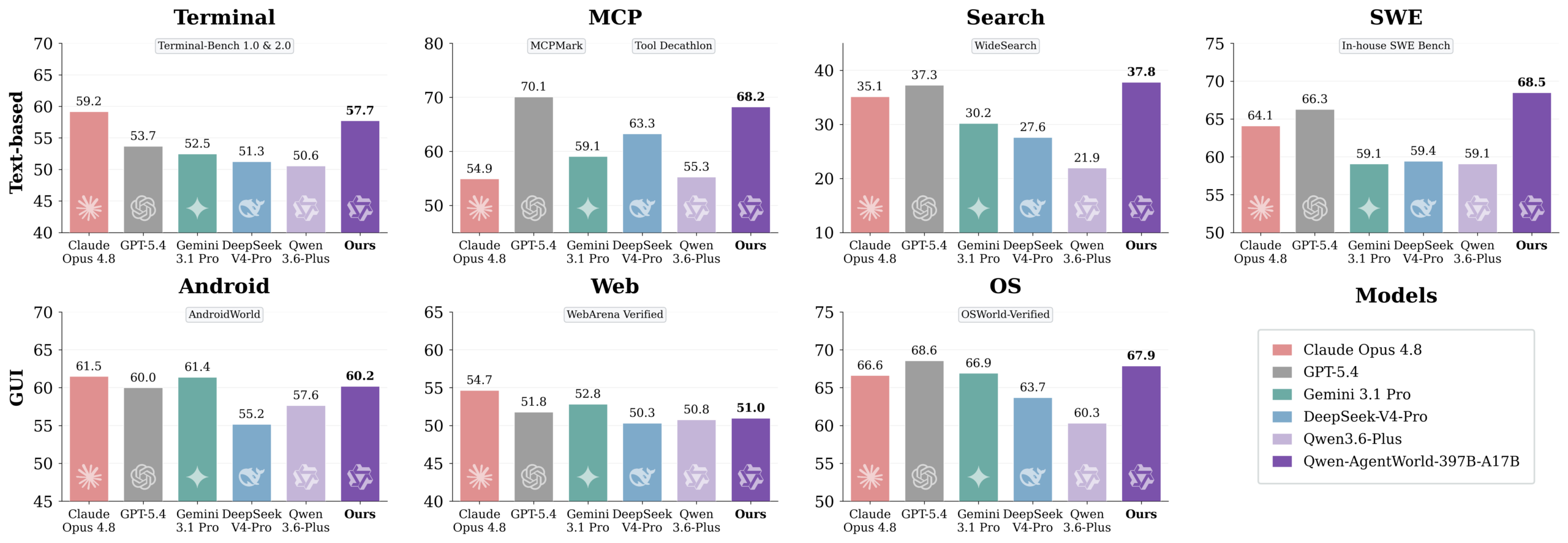
Alibaba’s new 35B MoE model (3B active) can simulate seven different agent environments, MCP, terminal, web, Android, and more, without running the real tools.
Baidu’s new MIT-licensed 3.3B model parses entire books in one shot with a constant memory footprint, demolishing the page-by-page for-loop paradigm. Here’s the architectural magic that makes it work.
Deep dive into the R-SWA attention mechanism behind Unlimited OCR, which makes KV cache growth a non-issue and enables one-shot parsing of entire books.
A Chinese hacker team spent a year decoding 2,963 pinouts to build a custom V100 PCB with full NVLink. It costs $220. Here’s how they did it and why it matters.