Showing page 2 of 55
Tracking DDR5 across four EU countries reveals a 28% price drop in under a month. Germany is 20% cheaper than the Netherlands. Here’s what it means for local LLM builders.
Leaked audited financials reveal OpenAI lost $38.5 billion in 2025. With open-source models eating market share and costs spiraling, the path to profitability looks increasingly like a mirage.
GLM-5.2 tops the creative writing leaderboard, is free on Hugging Face, and Unsloth’s 2-bit quant puts this 753B beast on a 256GB Mac. This is the local AI breakthrough you’ve been waiting for.
Open model makers are skipping the sweet spot for unified memory owners. A deep dive into the gap, the hardware, and what we can do about it.
The staggering energy gap between biological and artificial intelligence isn’t just a curiosity, it’s the defining hardware challenge of our decade.
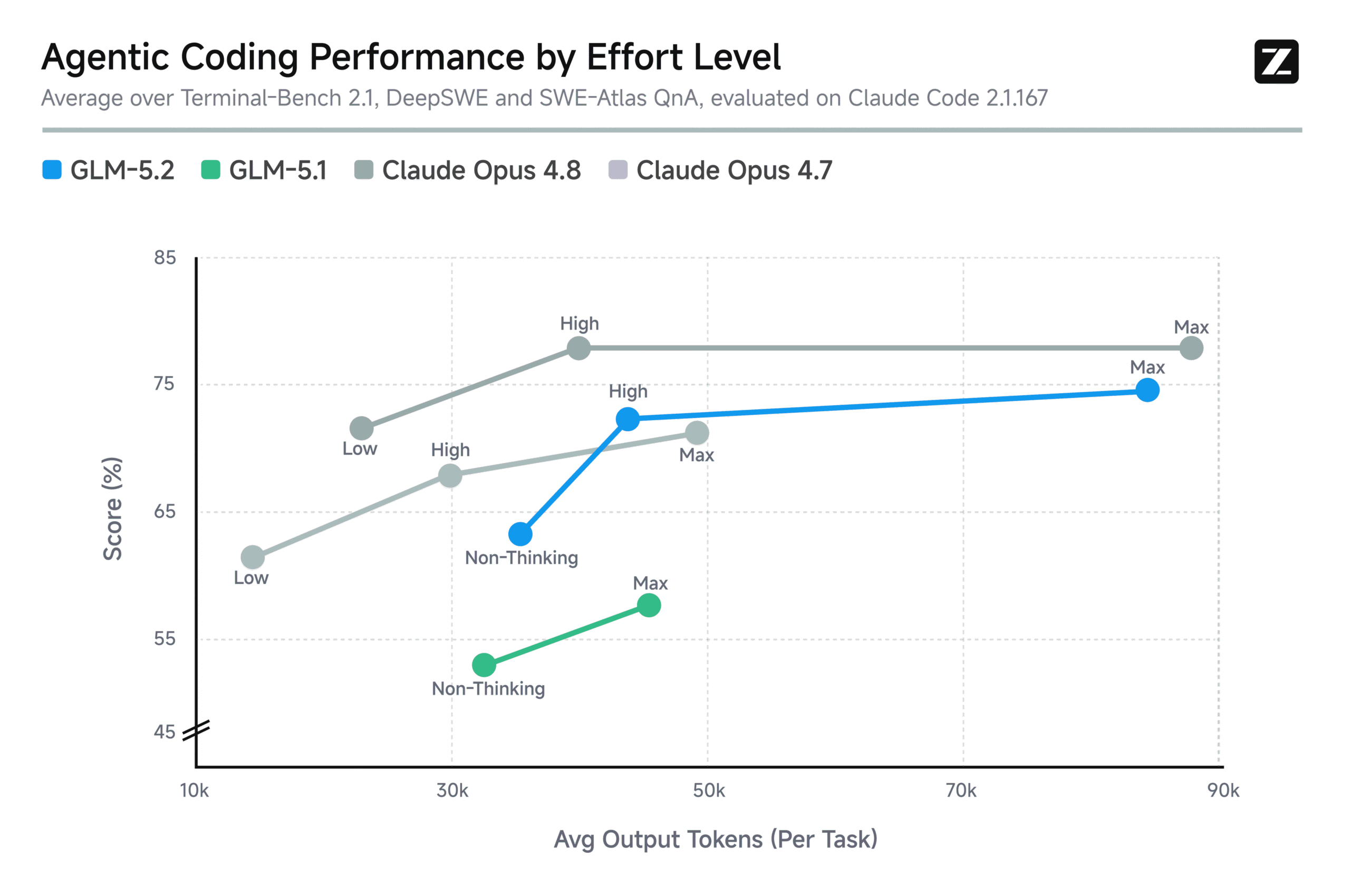
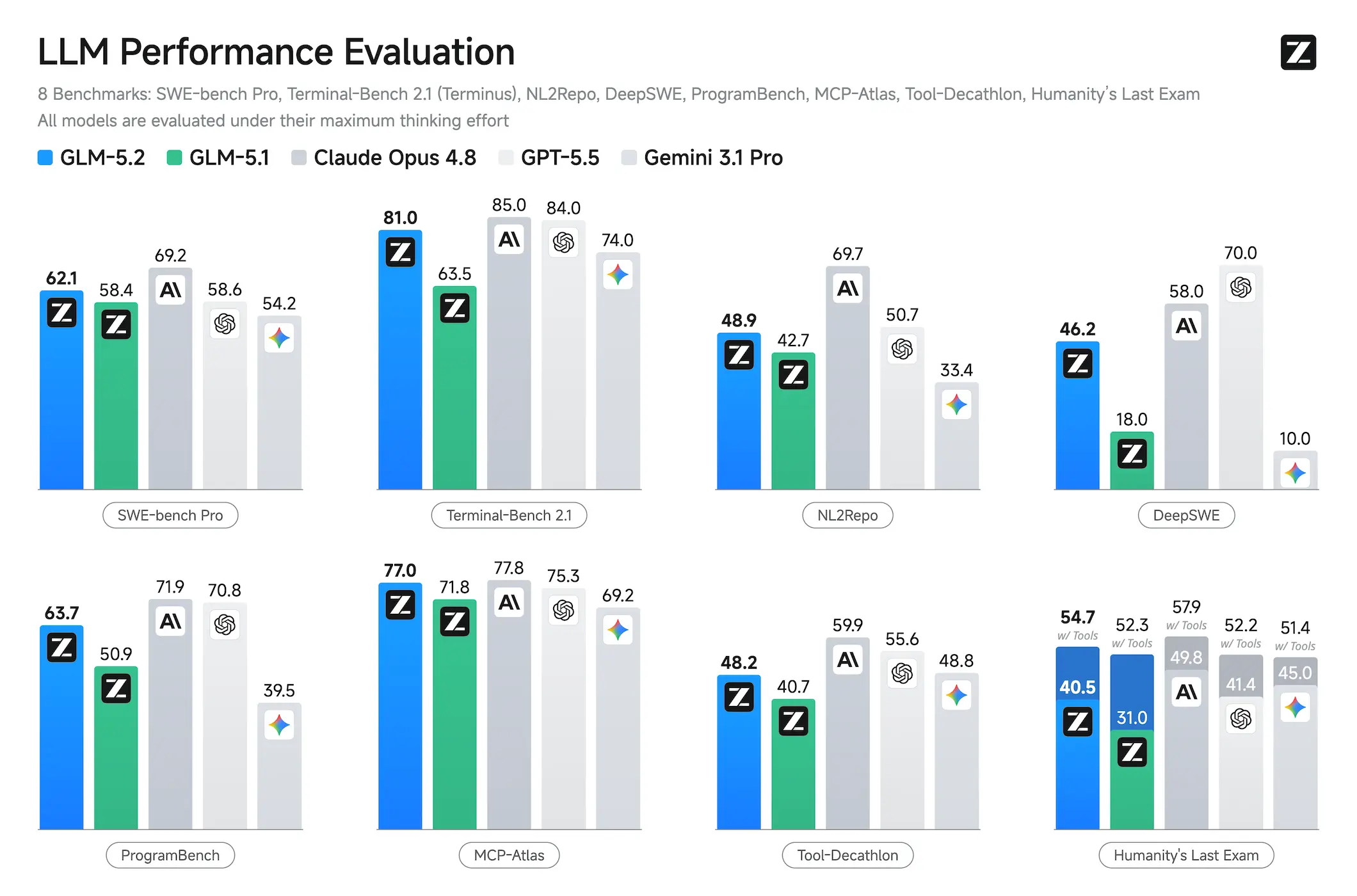
GLM-5.2 is the third-best model overall, but its MIT license means the real magic, distillation into small, local models, hasn’t even started yet.
Z.AI’s GLM-5.2 is the first open-weight model to cross 80% on Terminal-Bench, beating Gemini and threatening the closed-source business model. Here’s how 753B parameters and an MIT license are reshaping the AI landscape.
Adobe’s creative suite dominance faces an existential threat from AI’s exponential evolution. Can $500M in AI-first ARR save a business model built on scarcity?
Xiaomi’s MiMo V2.5 hits 3000 tps with a 1-trillion-parameter model using a radical FP4 quantization and a ‘block-diffusion’ drafter. Here’s the tech that made it happen and the catch.
One day after the US shut down Anthropic’s Fable 5, ZAI dropped GLM-5.2 under MIT license. This isn’t a coincidence, it’s a calculated geopolitical strategy that exposes the fragility of closed AI models.
An emergency export control forced Anthropic to disable Fable 5 and Mythos 5 globally over a jailbreak that found minor code bugs. This is your warning about centralized AI APIs.
Anthropic’s apology for hidden guardrails in Claude Fable reveals a systemic architecture failure. This post dissects the opaque design, the cascading trust issues, and what it means for AI system reliability.