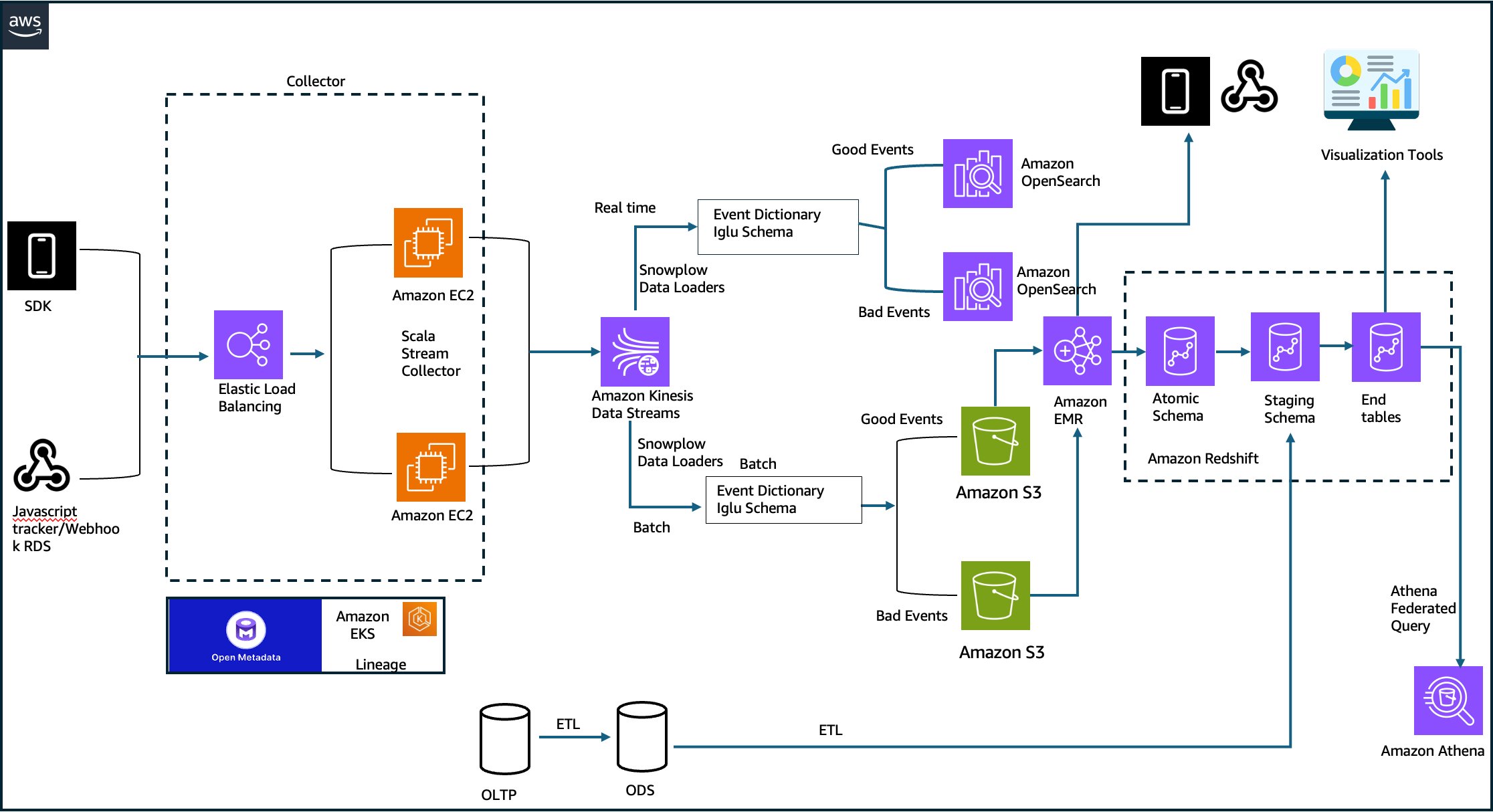
The Python Trap: Why Your SQL-First Team Will Hate DLT (and Why That’s Okay)
A real-world comparison of open-source DLT and managed Fivetran when your team lives in SQL, not Python. Includes costs, AI-assisted coding as a band-aid, and whether dlt is ready to kill Prefect.