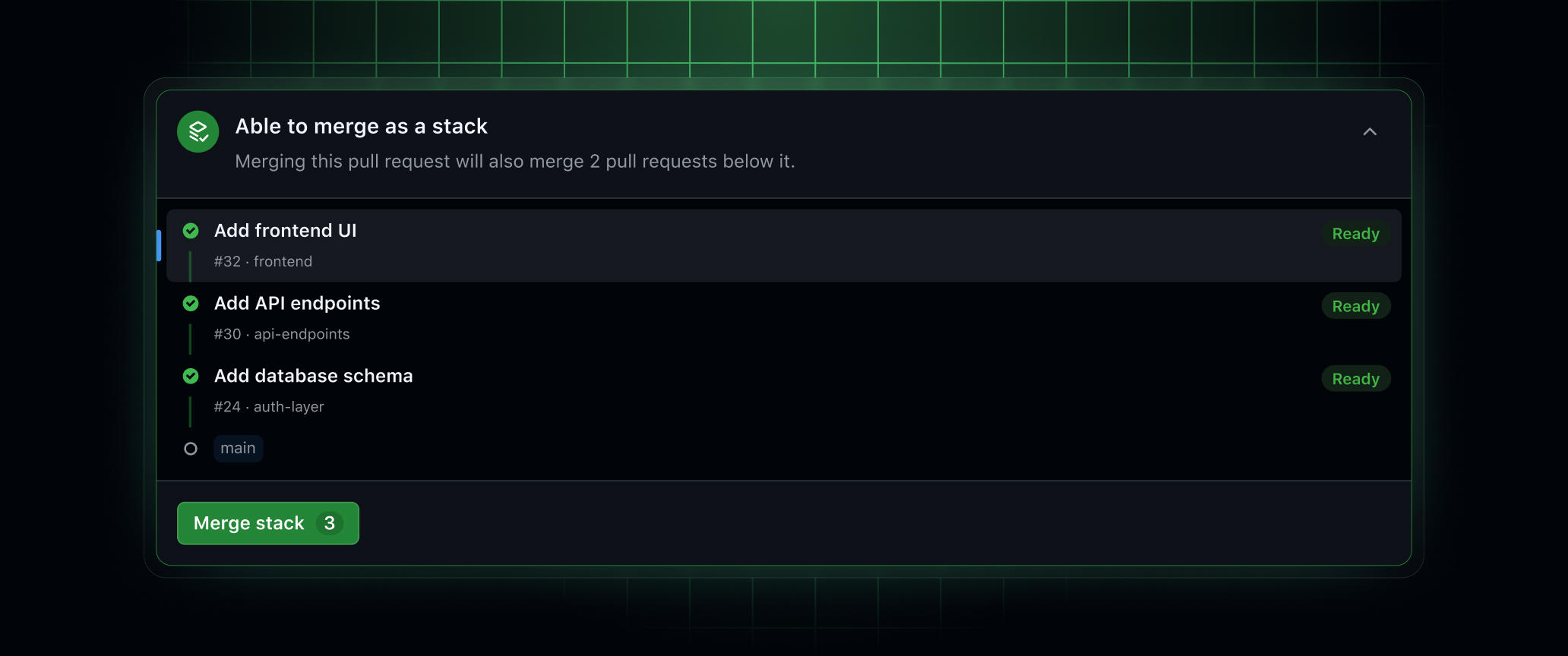
GitHub’s stacked pull requests promise to linearize complex dependency chains in monorepos. This isn’t just a new UI button, it’s a fundamental shift in how teams manage incremental change at scale.
Mistral isn’t conceding anything. It’s building a full-stack enterprise AI platform for regulated industries, and the revenue numbers are already speaking.
A new report reveals Hugging Face is a marketplace for non-consensual deepfakes. The platform’s hands-off approach is sparking an ethical firestorm that could reshape open source AI.
LG AI Research drops a 750B-parameter MoE behemoth under Apache 2.0. It crushes long-context benchmarks but pits 37B active params against models 10x smaller. Is this Korea’s sovereign AI win or a compute flex with diminishing returns?
Mitchell Hashimoto’s new venture Superlogical re-ignites the bitter debate: should AI-native startups embrace microservices or start monolithic?
A newly disclosed vulnerability turns Microsoft 365 Copilot into an unwitting worm propagator, hiding malicious instructions in documents that self-replicate across your organization.
Why relying solely on application logic for tenant isolation is a ticking time bomb, and what to do about it.
Nvidia is hiking RTX GPU prices by up to 30% for the third time this year. The DRAM crisis is real, but so is the pain for anyone trying to build a PC.
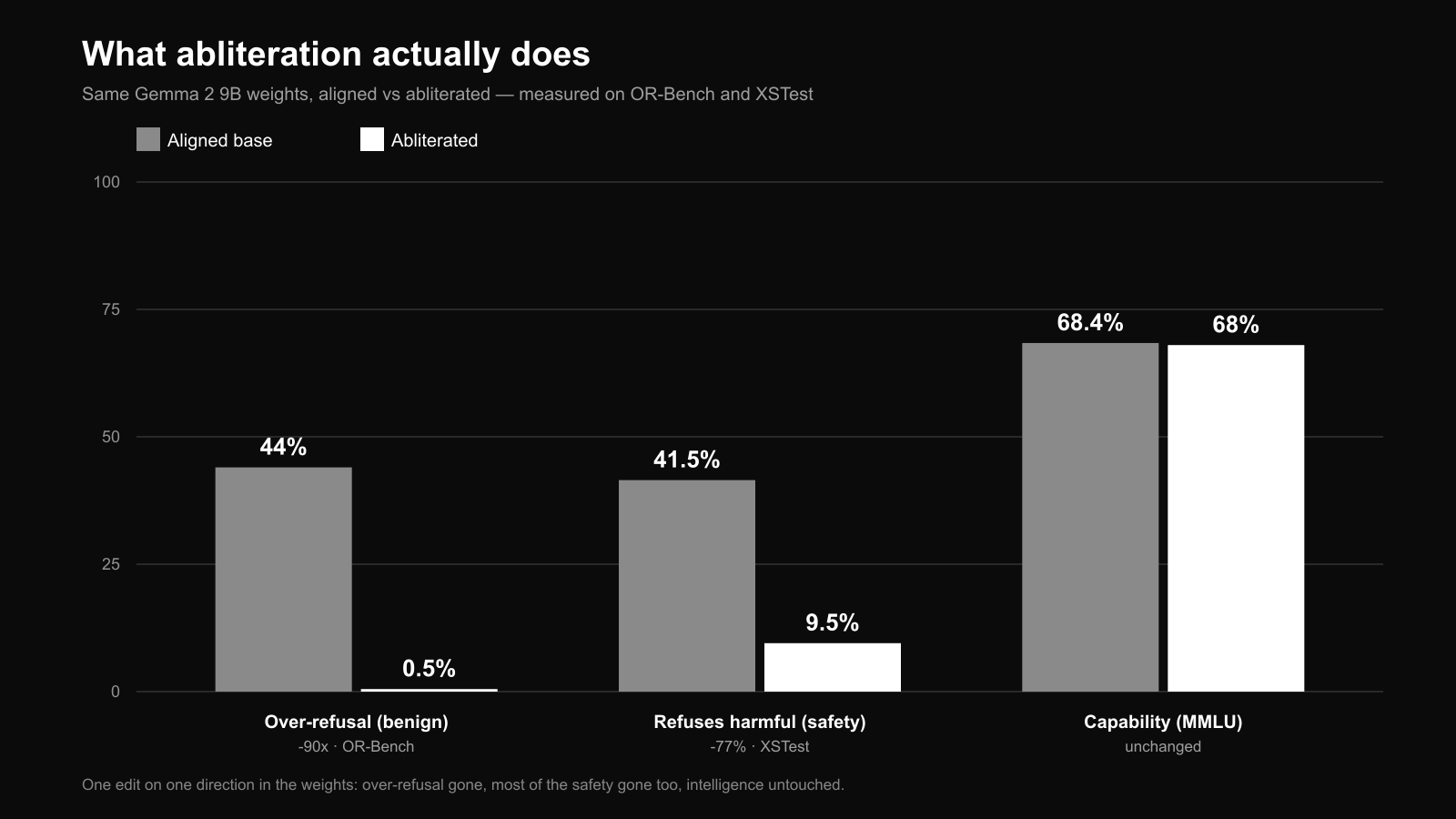
Removing safety filters from LLMs doesn’t just reduce refusals, it makes outputs more confident and optimistic without improving accuracy. New research proves it.
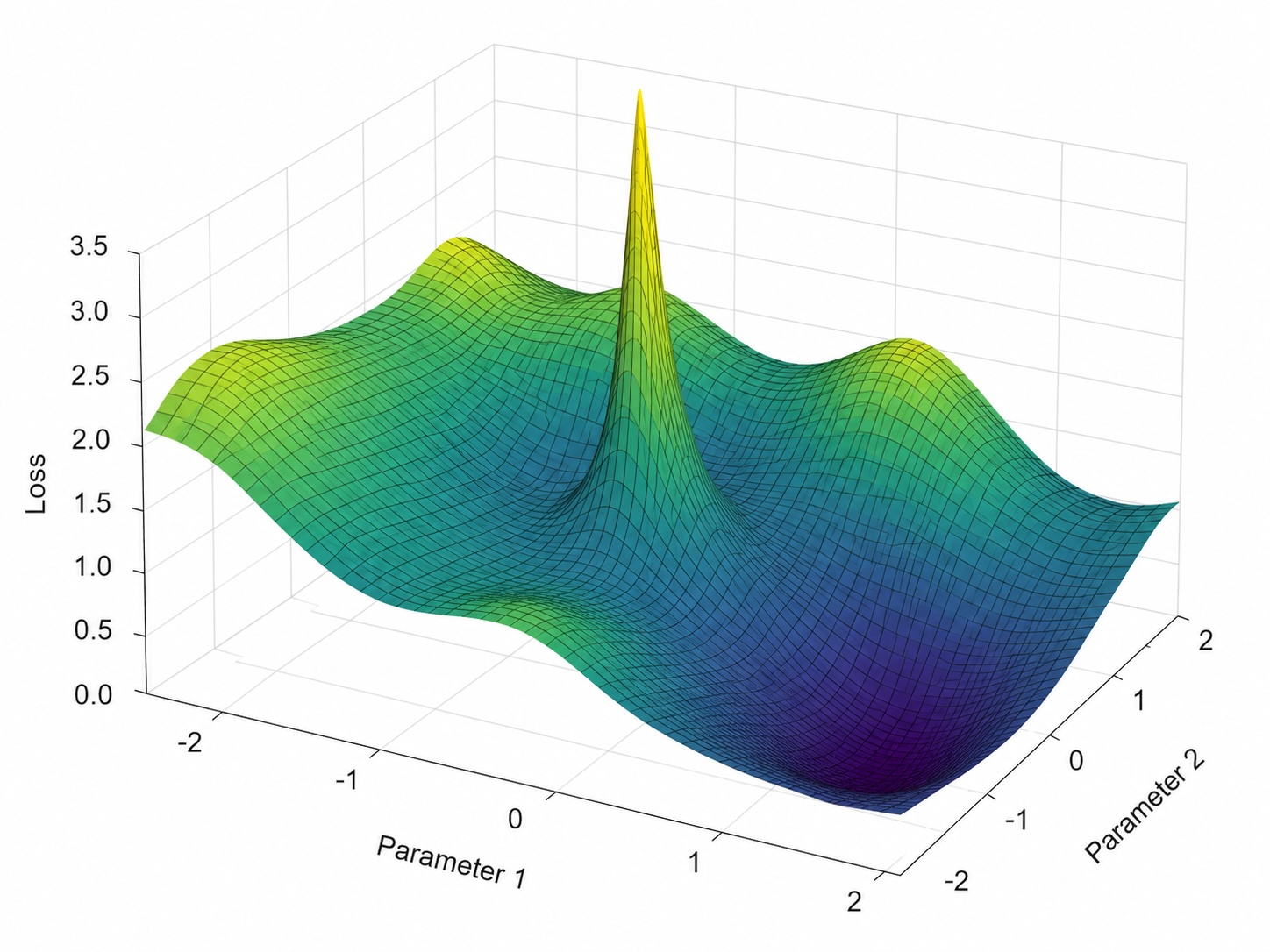
Blindly using Adam defaults is costing you convergence, stability, and generalization. Here’s the math, the failure modes, and the fix.
Transactional message deduplication is hard. The Inbox Pattern works when you co-locate tracking and business logic within the same database transaction. Here’s how to actually implement it.
Quantizing the KV cache on Qwen and other LLMs saves VRAM but can gut output quality. New research shows the drop is far worse than weight quantization, with creative and technical tasks taking the biggest hit.