The two-engine era is over.
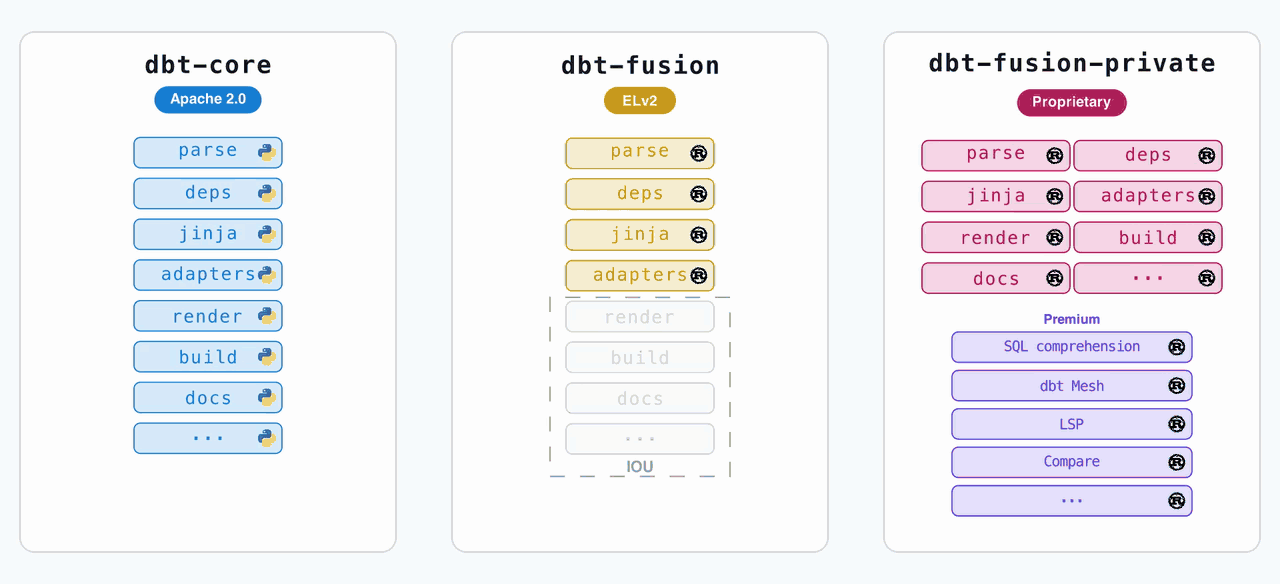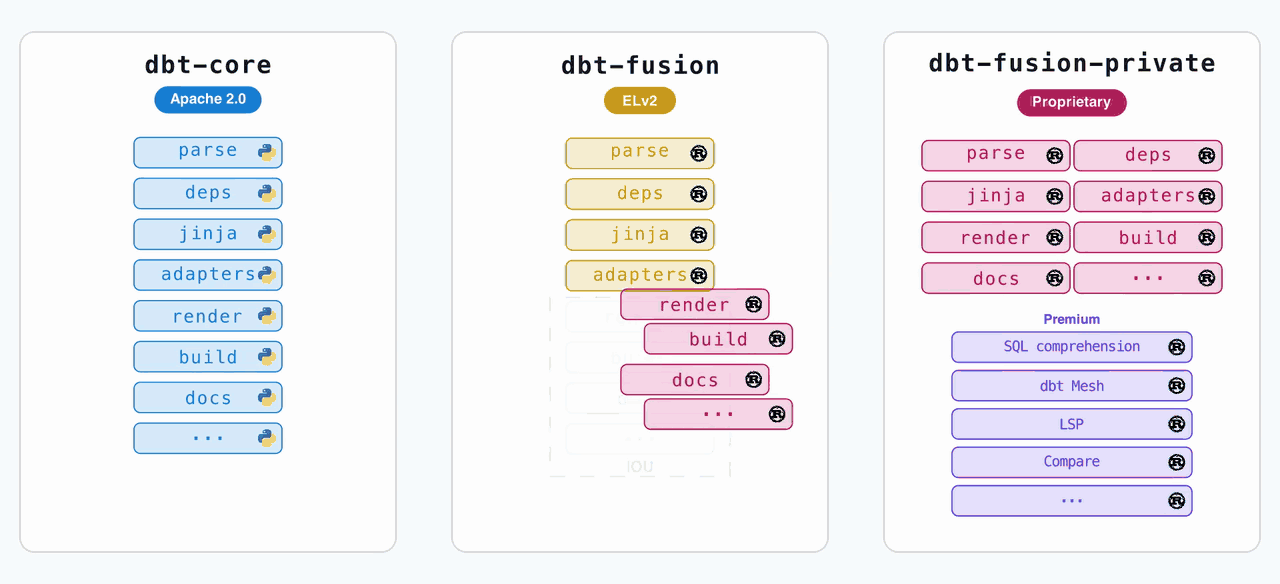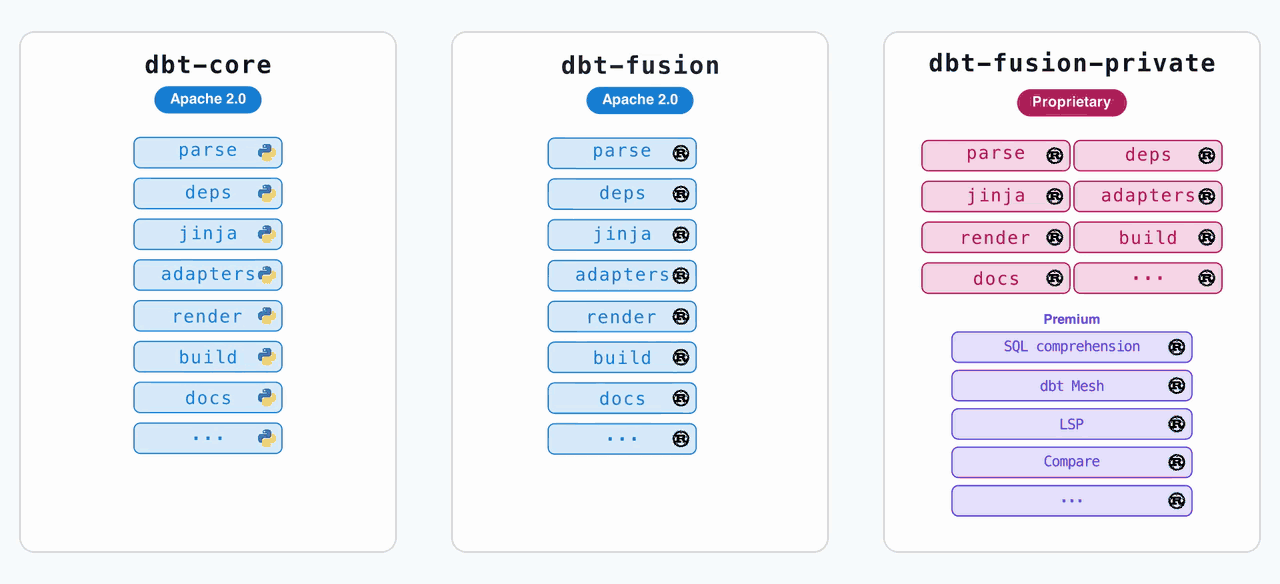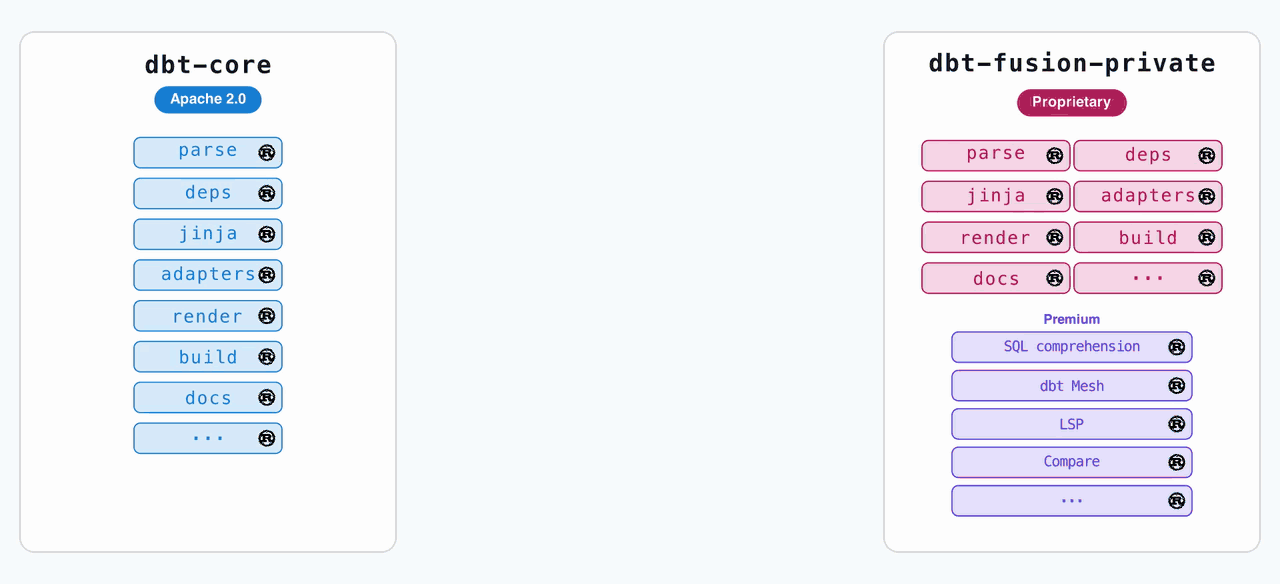
On June 1st, dbt Labs dropped the first alpha of dbt Core v2.0, and it’s not just a version bump. It’s a nuclear reversal of the company’s own licensing strategy. The code that was previously locked behind the ELv2 license in the dbt-fusion repository, the high-performance Rust runtime, is now open source under Apache 2.0 in the dbt-core repo. The dbt-fusion repo? Archived.
This is the biggest strategic shift in dbt since the v0 to v1 migration in 2021. And it’s raising eyebrows across the data engineering community.
The Original Plan That Didn’t Stick
When dbt Labs announced the Fusion engine last year, the pitch was clear: Core (Python, Apache 2.0) would remain the free, open-source baseline. Fusion (Rust, ELv2) would be the commercial-grade engine with faster parsing, column-level lineage, and a built-in SQL linter. The plan was to keep them on separate tracks, with occasional feature backports from Fusion to Core.
That plan lasted about a year.
The problem was structural. The Python code for Core had to be entirely open source because Python distribution requires source disclosure. But Rust binaries don’t. This meant dbt Labs could ship a free, precompiled Fusion binary that included proprietary code without ever revealing its internals. The bifurcation wasn’t just annoying for users, it was expensive for dbt Labs. Every time Fusion got a major feature, the team had to build an equivalent Python implementation for Core.
“This worked well enough during Fusion’s development period: new language features like Iceberg catalog support,
--sample, and UDF definitions got equivalent OSS implementations in dbt Core v1.10 and v1.11.”
, Joel Labes, Staff Developer Experience Advocate, dbt Labs
But as Fusion’s GA approached, the maintenance burden became unsustainable. The two-engine strategy was a tax on innovation.
What dbt Core v2 Actually Changes
Let’s be specific. The alpha release of dbt Core v2.0 ships the following:
| Feature | Impact |
|---|---|
| Rust-based runtime | Orders-of-magnitude faster parsing and execution, especially on large projects |
| Tightly-defined language spec | Impossible to accidentally configure a typo like desciptin instead of description |
| Parquet artifacts | High-performance alternative to large JSON files, directly queryable via DuckDB |
| Revamped local docs experience | Scales to projects of arbitrary size, powered by new artifacts |
| ADBC-powered adapters | Streamlined way to build new connectors using the Arrow ecosystem |
| Simplified installation | No more fighting Python virtual environments |
The old pip install dbt-core now gets you a Rust binary, not a Python script. The old pip install dbt gets you the enhanced Fusion distribution, which includes proprietary features like column-level lineage and a high-performance SQL linter.
The critical distinction: your project logic is portable between both distributions. The language spec is identical.
The Trust Question That Won’t Go Away
The community reaction has been… mixed. Under the Reddit thread about the announcement, skepticism runs deep:
“Seems like the original plan to cripple dbt core to push dbt fusion didn’t go how they planned. So instead they’re open sourcing parts of fusion to replace dbt core and hoping they can switch the license in the future and screw folks over.”
This isn’t paranoia. It’s pattern recognition. dbt Labs previously acquired Transform’s semantic layer and closed the source. They did the same with the SDF Labs acquisition before eventually opening it back up. The Fivetran merger only amplified concerns about long-term community trust in the open-source future of dbt.
But there’s a counterargument, and it’s worth considering seriously:
“Figure out where customer pain points are then build solutions people will pay for. Then when competitors release stuff for cheaper/free that threaten your moat, open source part of what you paywalled and move on to next non-commodified feature. This is the best version of open source.”
That’s the Databricks playbook, applied to data transformation. And it’s not wrong.
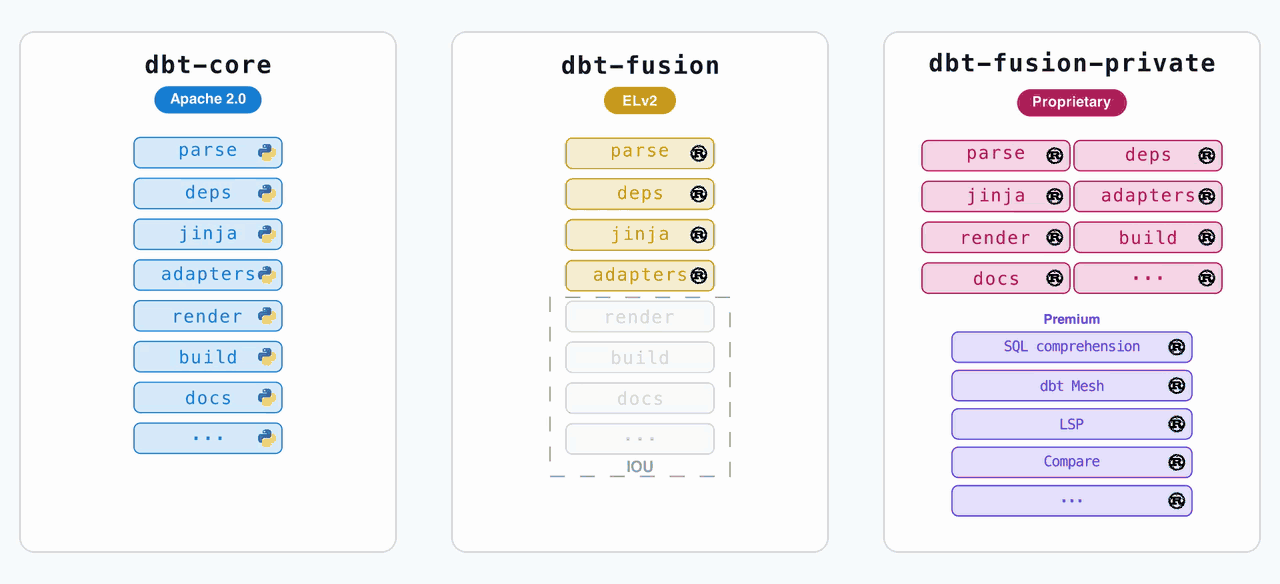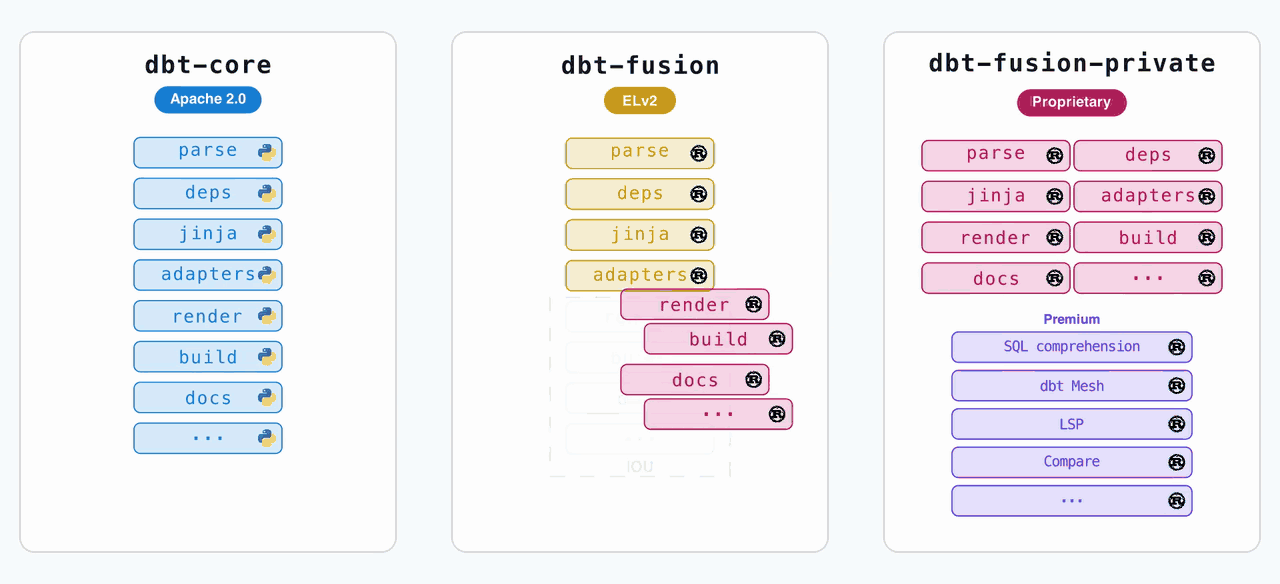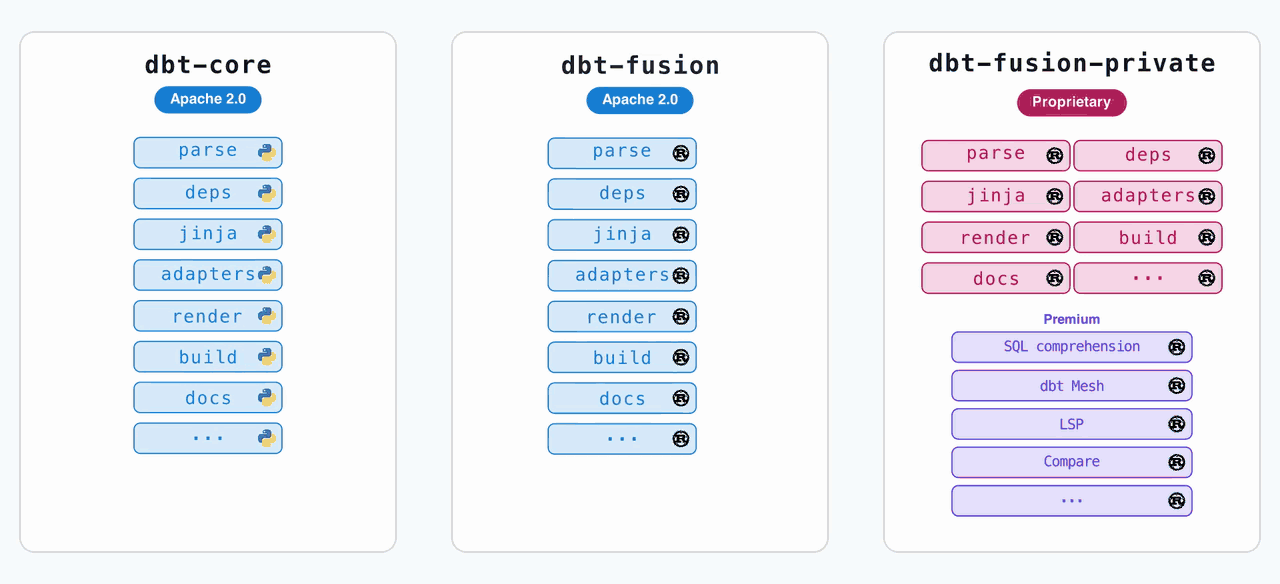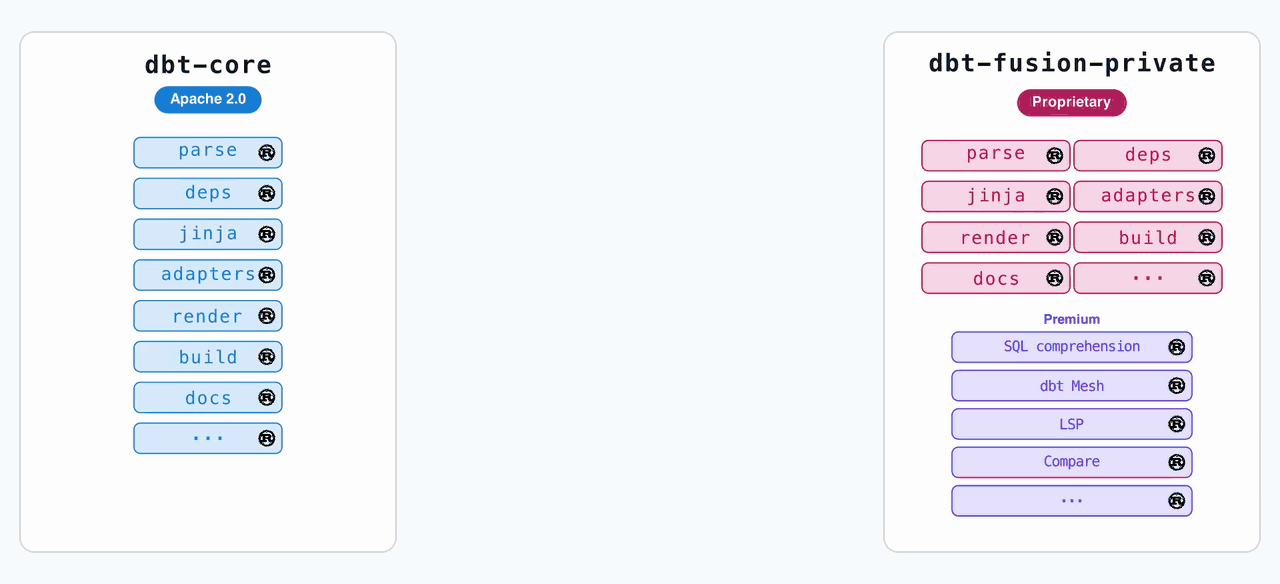
The Licensing Table That Explains Everything
dbt Labs published a side-by-side comparison of their 2025 vs. 2026 licensing decisions. It’s worth staring at:
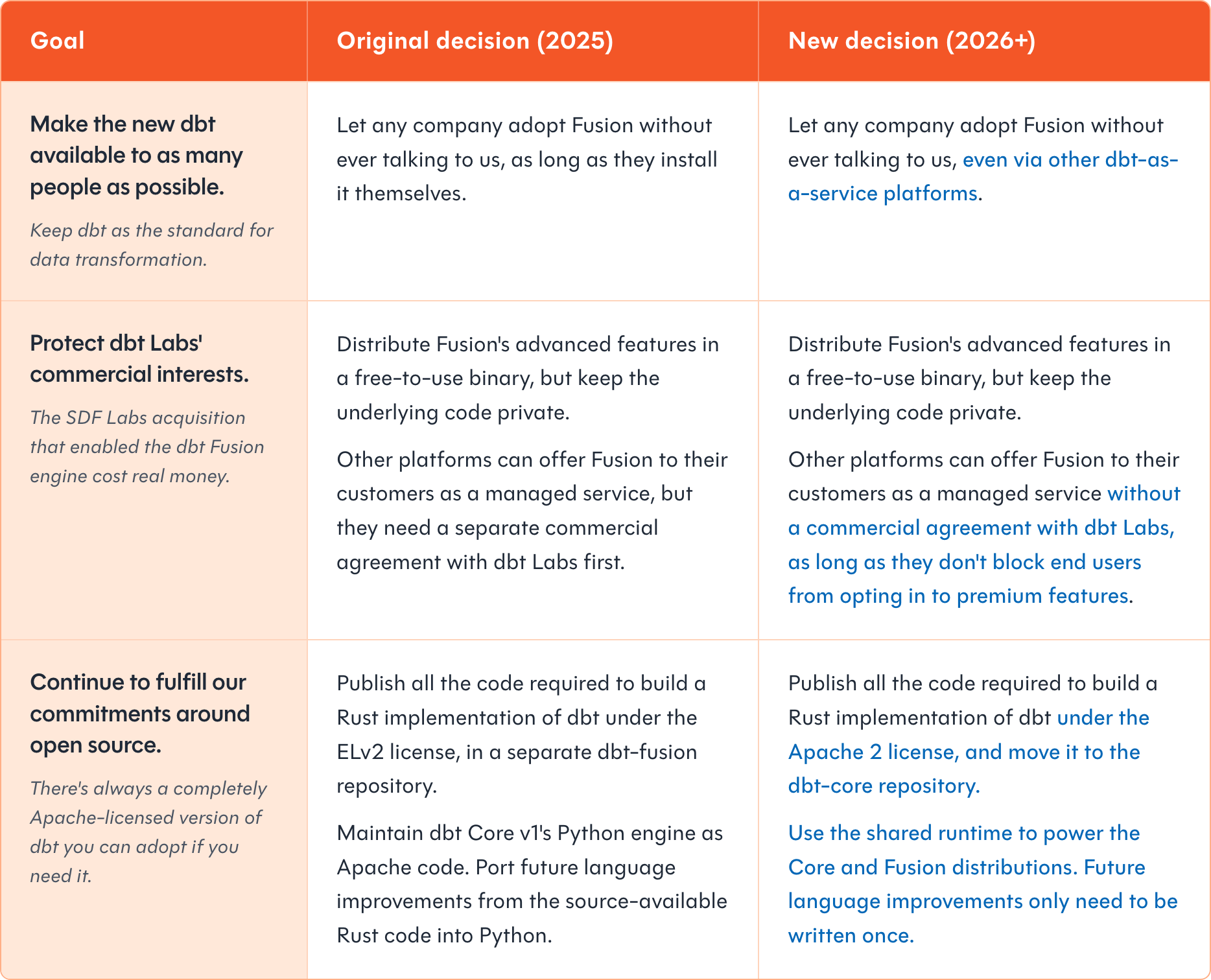
The key shift: dbt Core is now the shared runtime code from the dbt Fusion engine, released under Apache 2.0. The enhanced Fusion binary is relicensed to be more permissive than ELv2, meaning competitors can now offer Fusion as a managed service, as long as they allow end users to enable premium features.
This is a direct concession to competitive pressure from challengers like SQLMesh. SQLMesh’s dbt-compatibility layer was getting serious traction, and local column-level lineage was one of its killer features. By open-sourcing the Fusion runtime, dbt Labs removes that advantage entirely.
Who Actually Benefits?
The official post lists four beneficiaries, and it’s worth evaluating each:
- The open-source community: “We are open-sourcing a huge amount of IP, for anyone to use however they see fit.” True. The Rust runtime is genuinely valuable code.
- Competing platforms: “The enhanced Fusion binary is now available for use everywhere (including to power products competing with Fivetran + dbt Labs).” Also true. This is a massive olive branch.
- Integrators: “Setting a clear roadmap encourages widespread adoption of v2 of the dbt framework.” This depends on how many people actually migrate.
- Open-source users: “A shared runtime ensures that OSS users benefit directly from our ongoing investment in dbt.” This is the most important claim. Previously, OSS users had to trust that features would be ported from Rust to Python. Now there’s nothing to port.
The skeptic’s take: the real beneficiary is dbt Labs. By consolidating on one engine, they reduce development costs while expanding the pool of potential customers for premium Fusion features. The platform ambitions get easier to execute when everyone is running the same foundation.
The Migration Path
If you’re sitting on dbt Core v1.x, here’s what you need to know:
The recommended upgrade path is to install Fusion, not Core. Joel Labes is explicit: “For the best free dbt CLI you can use locally and in production environments, install Fusion.” Fusion can do more out of the box and lets you enable premium features seamlessly.
For the small subset of teams that require pure Apache 2.0 code (you’ll know who you are), Core v2.0 is available via pip install dbt-core==2.0.0-alpha.1.
The migration is assisted by:
– dbt-autofix package for automated fixes
– An agent skill for version upgrades
– dbt parse --use-v2-parser to validate your project before switching
First step: upgrade to v1.12. It enforces the behavior changes that are fully removed in v2.0 and ships the Fusion-powered project parser.
dbt Core v2 is a genuine architectural leap. The Rust runtime, the Parquet artifacts, the language spec, these are real improvements that solve real pain points (looking at you, 15-minute parse times on a 3,000-model project).
But it’s also a strategic retreat disguised as an advancement. The original plan to gatekeep the Fusion engine behind ELv2 didn’t work. SQLMesh was eating their lunch on local column-level lineage. The community was distrustful. The Fivetran merger made everything more complicated. Open-sourcing the runtime was the only move that simultaneously reduced costs, defused competition, and rebuilt trust.
The real test will come in 12-18 months, when dbt Labs inevitably tries to monetize some new capability exclusively through the Fusion binary. If they handle that transition with the same transparency they’ve shown here, the trust argument gains credibility. If they don’t, the cynics will have been right all along.
For now, if you’re a data engineer, the upgrade is worth it. The performance improvements alone justify the migration. Just keep one eye on the licensing page.