Showing page 1 of 27
Podman v6.0.0 brings breaking changes, Quadlet improvements, and a daemonless future. But can it finally overcome Docker’s inertia?
Hugging Face’s new open-source speech-to-speech pipeline challenges OpenAI’s Realtime API with a modular, local-first approach using Gemma 4 and Cerebras.
Kimi K2.7 Code is the first open-weight model in GitHub Copilot. A look at what it means for pricing, competition, and the future of AI coding assistants.
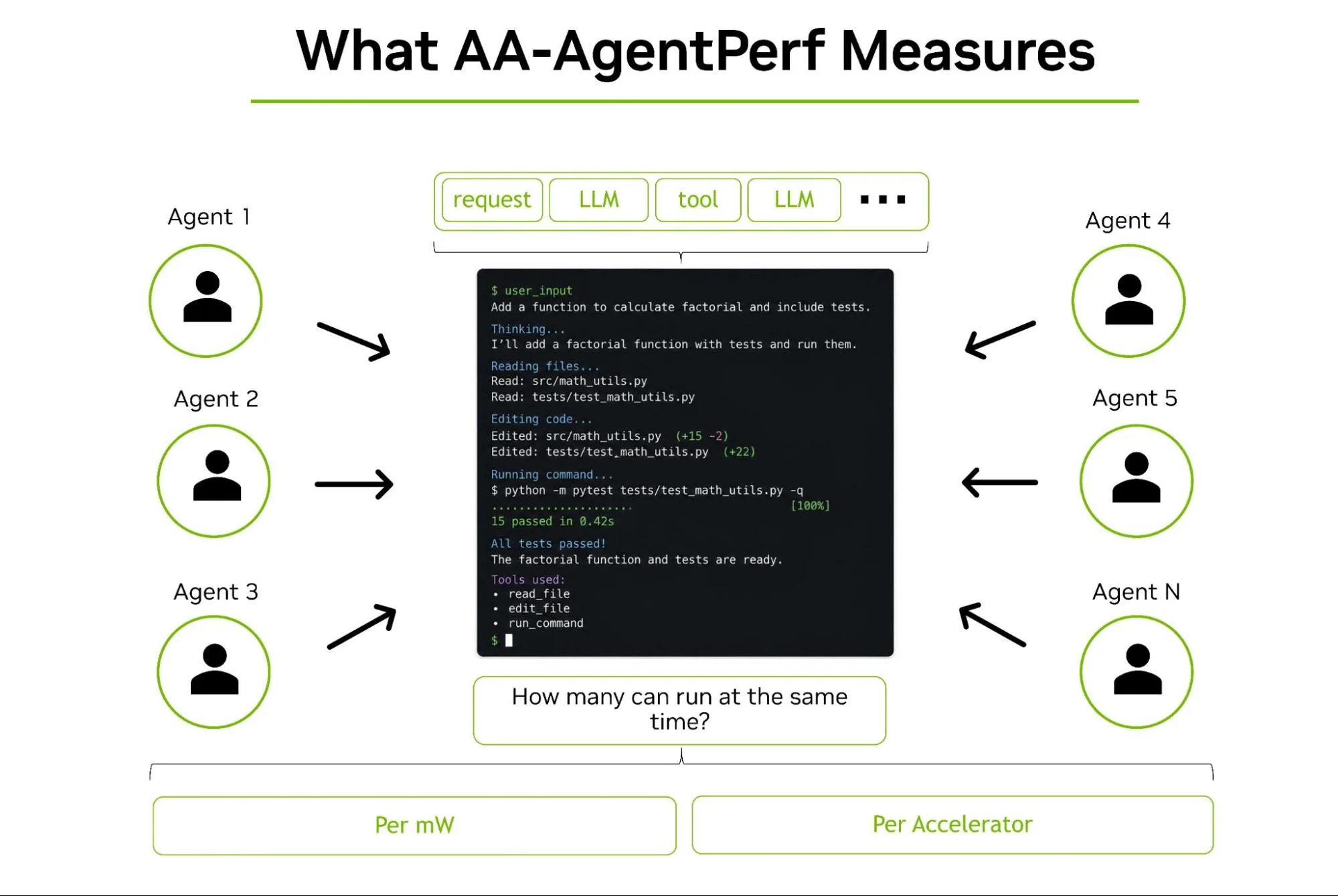
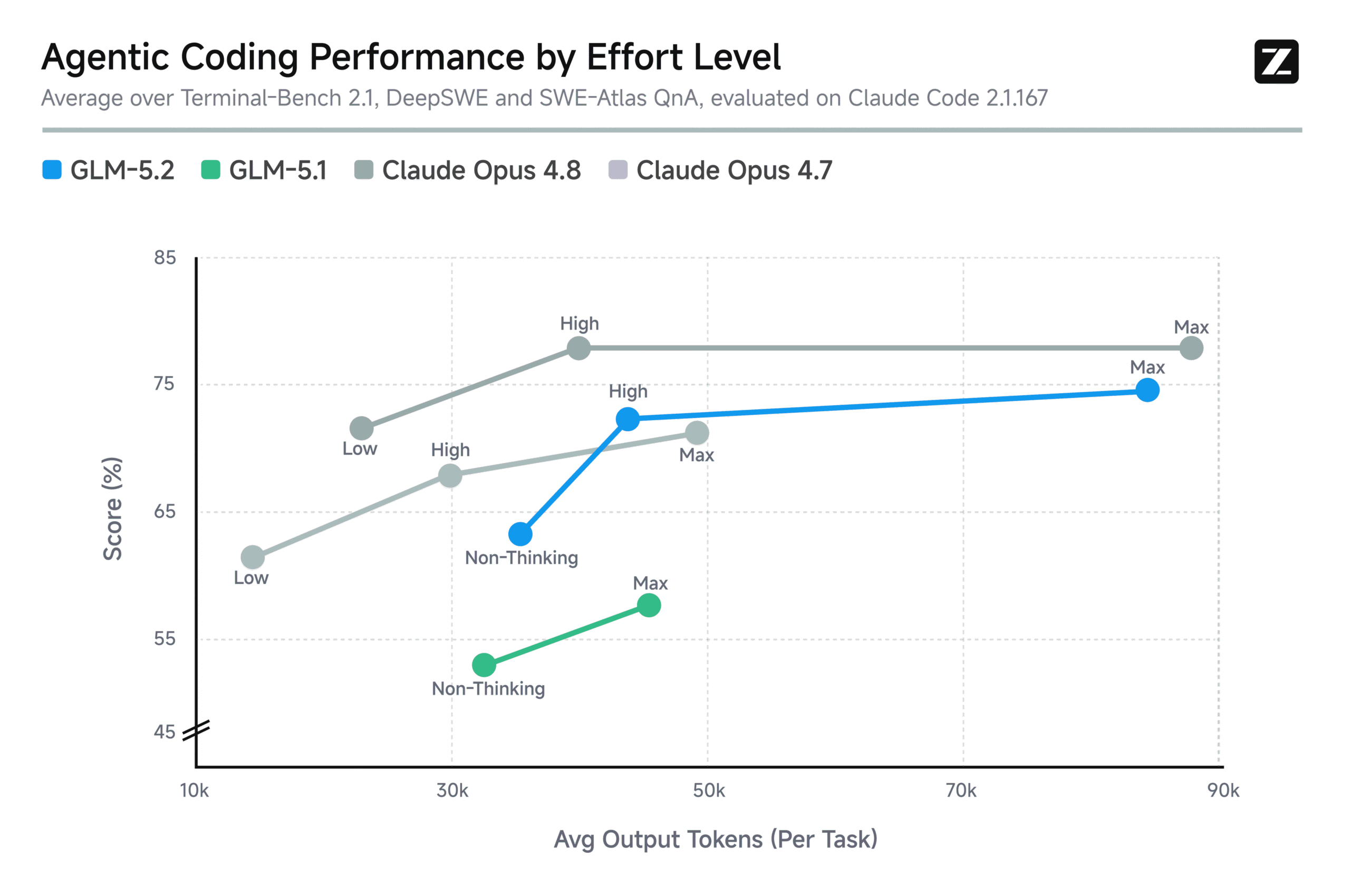
A practical guide to benchmarking open-source models for agentic tasks, with real data on how Kimi, GLM-5.2, and Ornith-1.0 are closing the gap to proprietary systems.
Review proposed code changes.
A no-BS comparison of Temporal, Hatchet, and Prefect for microservices task orchestration, with real-world insights on LLM pipelines, event-driven architecture, and the hidden costs of each choice.
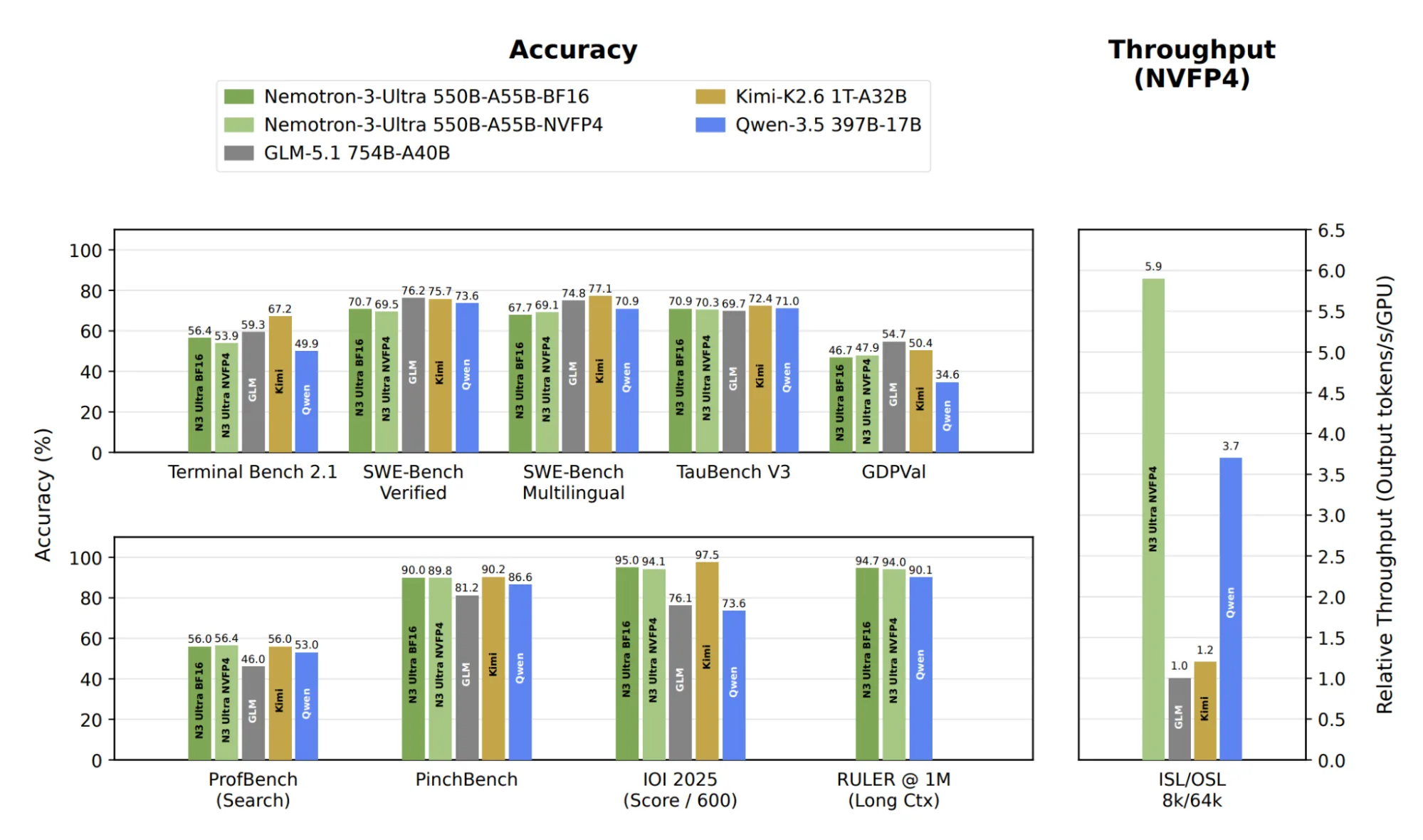
NVIDIA’s Qwen3.6-27B-NVFP4 squeezes a 27B model into 22GB while matching, and sometimes beating, FP8 accuracy. Here’s how the quantization magic works and why it matters for local LLM deployment.
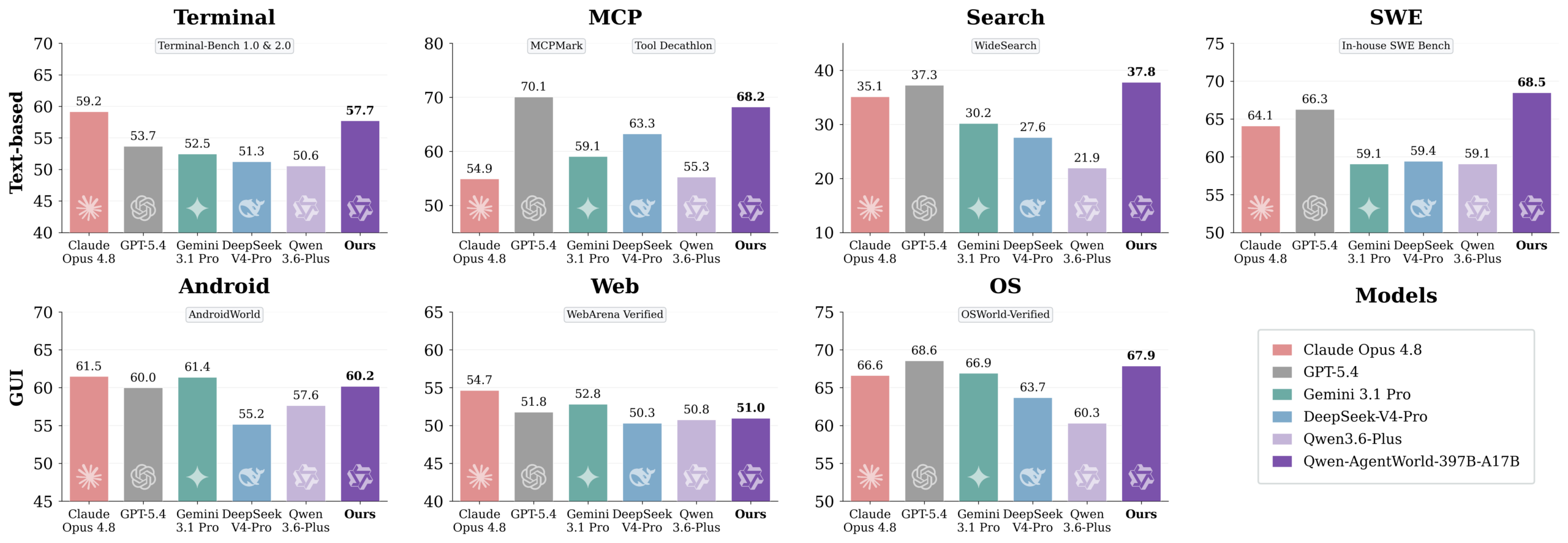
Alibaba’s new 35B MoE model (3B active) can simulate seven different agent environments, MCP, terminal, web, Android, and more, without running the real tools.
Analysis of whether event-driven architecture is being overused similarly to microservices a decade ago, discussing genuine justifications versus unnecessary complexity.
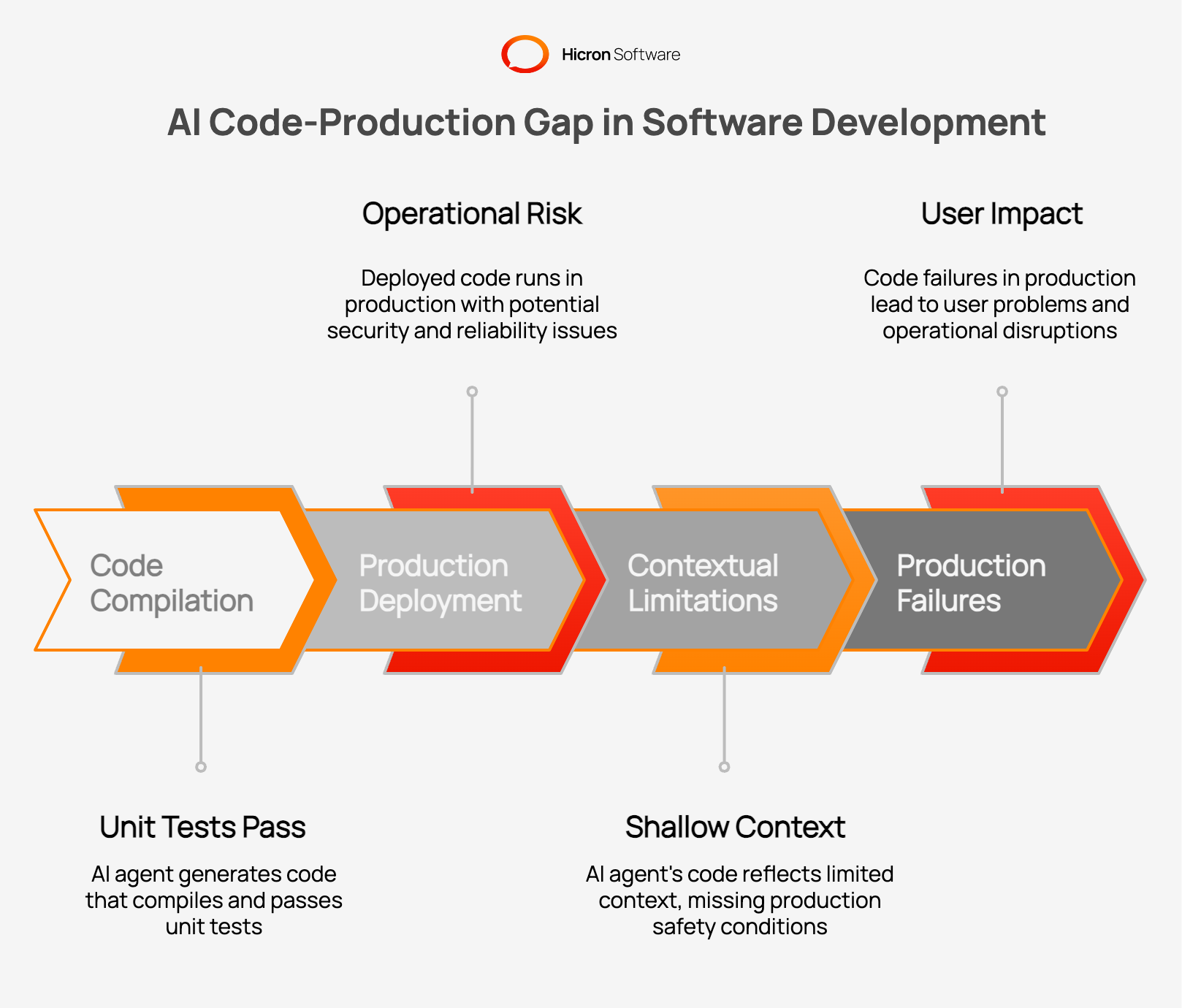
An NBER study reveals AI coding tools produce 7x more code but only 30% more releases. The bottleneck isn’t writing code, it’s everything that happens after.
The new HTTP QUERY method (RFC 10008) finally bridges the gap between GET and POST for complex queries. But does the web need another verb, or is this a solution in search of a problem?
GLM-5.2 is the third-best model overall, but its MIT license means the real magic, distillation into small, local models, hasn’t even started yet.