Showing page 2 of 27
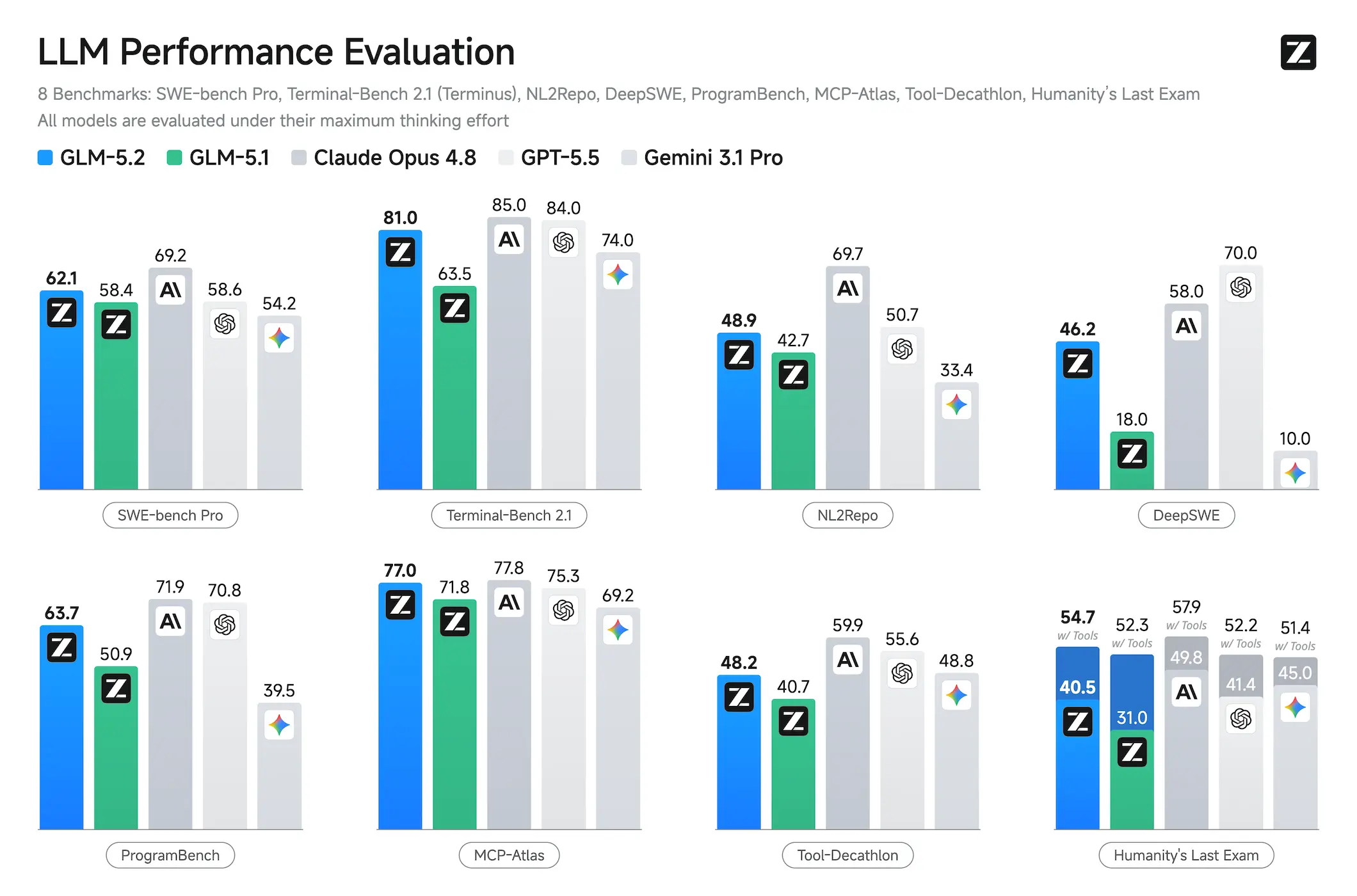
Z.AI’s GLM-5.2 is the first open-weight model to cross 80% on Terminal-Bench, beating Gemini and threatening the closed-source business model. Here’s how 753B parameters and an MIT license are reshaping the AI landscape.
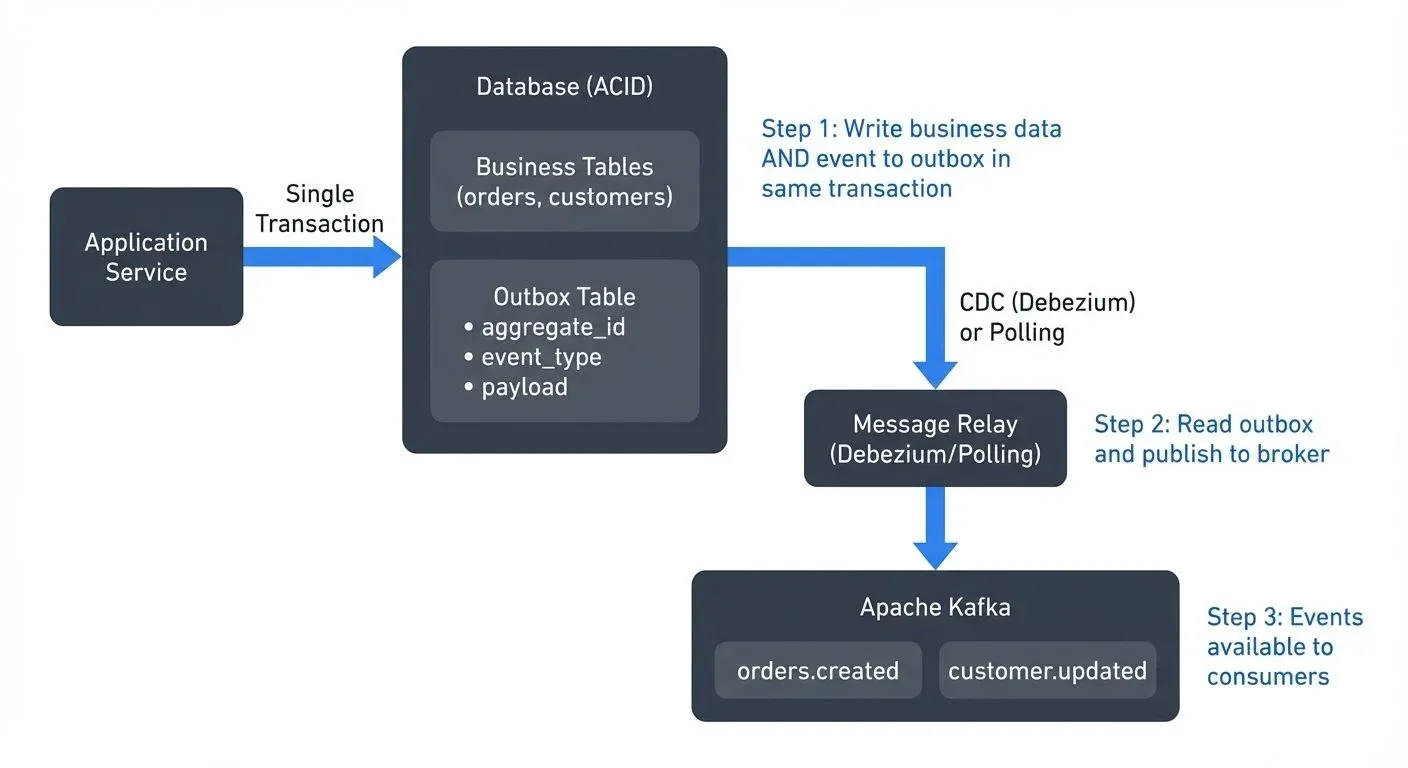
At-least-once delivery guarantees duplicates. Here’s how to handle them without losing your mind, or your data.
One day after the US shut down Anthropic’s Fable 5, ZAI dropped GLM-5.2 under MIT license. This isn’t a coincidence, it’s a calculated geopolitical strategy that exposes the fragility of closed AI models.
An emergency export control forced Anthropic to disable Fable 5 and Mythos 5 globally over a jailbreak that found minor code bugs. This is your warning about centralized AI APIs.
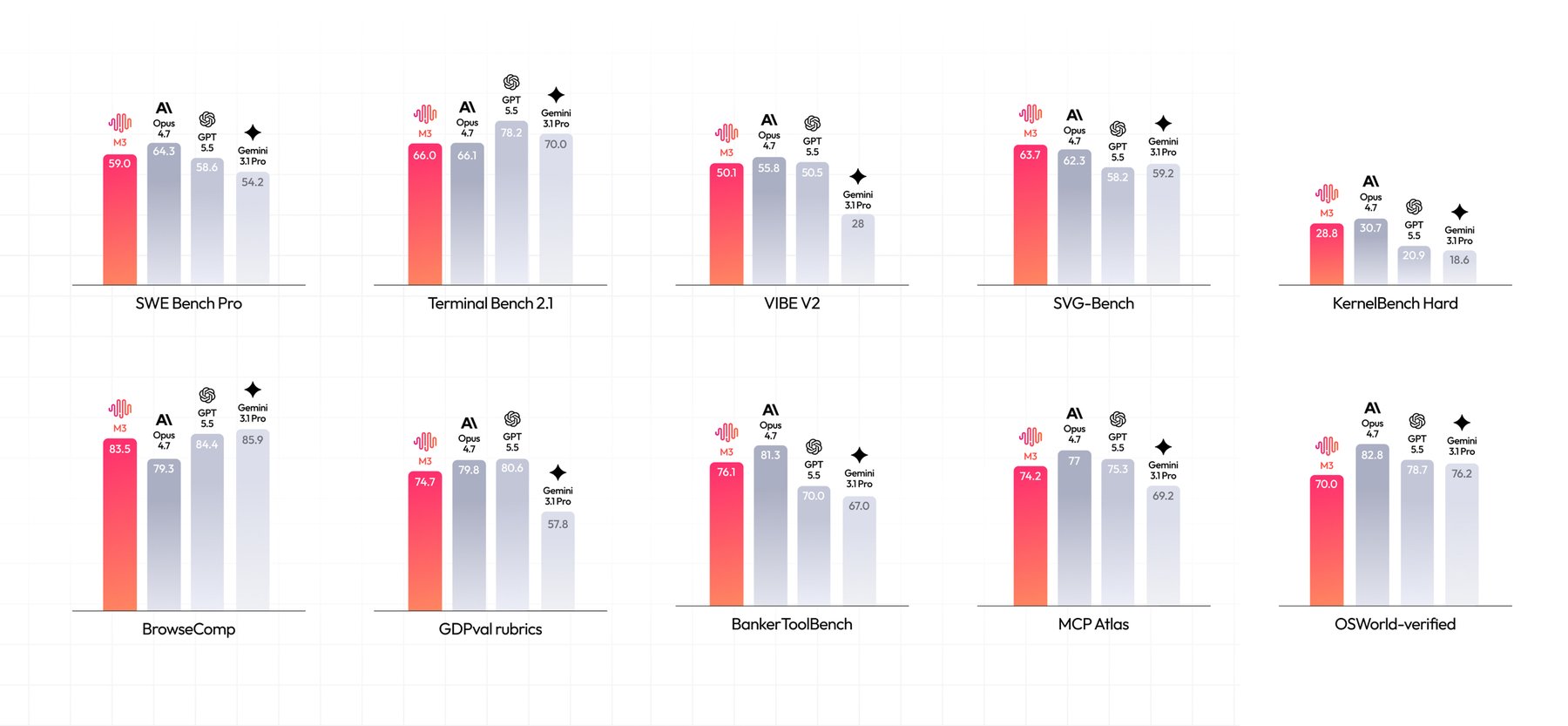
MiniMax surprises the AI community by dropping M3’s open weights on a Friday evening. Here’s what this means for the open LLM landscape versus Qwen, Llama, and Gemma.
A distinguished engineer at a hyperscaler reveals that Fable 5 shows little practical improvement over previous models in iterative software engineering. Benchmark leaps don’t translate to the real world.
How attackers compromised Microsoft’s open source AI tools to steal credentials, and why the real vulnerability is the broken trust model in AI development supply chains.
Google DeepMind’s Gemma 4 12B brings video, audio, and text processing to standard laptops with 16GB RAM. No cloud, no subscription, just pure local intelligence.
Why your ORM is hiding production-killing N+1 queries and the seven other patterns that only show up under load. Plus, the one habit that catches them before you ship.
PewDiePie’s Odysseus AI hit 30k stars in 48 hours, then security researchers showed how a single malicious prompt could hand over admin access. A deep dive into the vibe-coding security crisis.
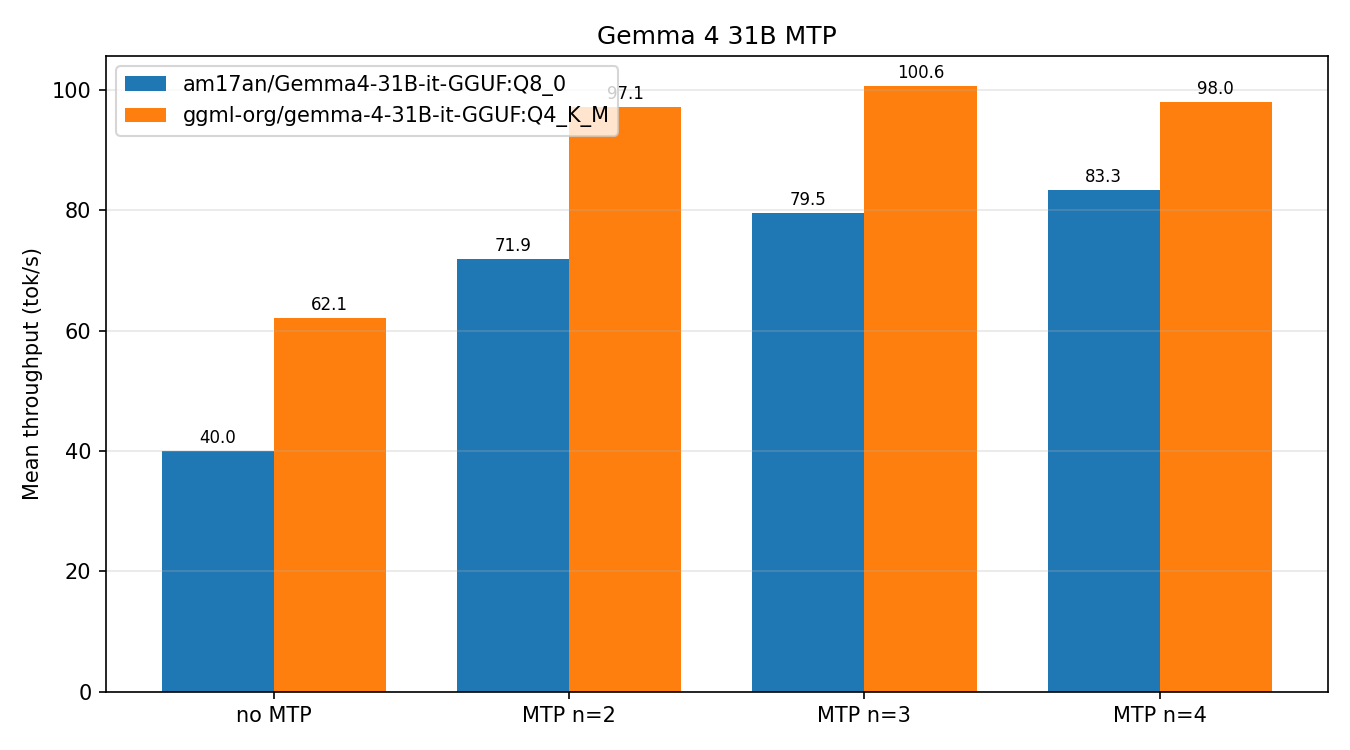
The merge of Gemma 4 MTP support into llama.cpp b9549 enables speculative decoding that doubles local inference speeds on consumer hardware. Real benchmarks from the community reveal surprising caveats.
Deep benchmarks of Qwen 3.6 27B KV cache quantization methods reveal that TurboQuant’s glory days are behind it, while KVarN shifts the entire quality-per-memory curve.