IQuest-Coder-V1’s 81% SWE-Bench Claim: A 40B Model That Punches Above Its Weight, or Just Benchmark Boxing?
When a relatively unknown lab drops a 40-billion-parameter dense model and claims it beats Claude Sonnet on SWE-Bench, the AI community’s collective eyebrow raises. IQuest-Coder-V1 isn’t just another entry in the increasingly crowded coding LLM space, it’s a litmus test for whether we’ve entered an era where benchmark scores tell the whole story or merely the story model developers want us to hear.
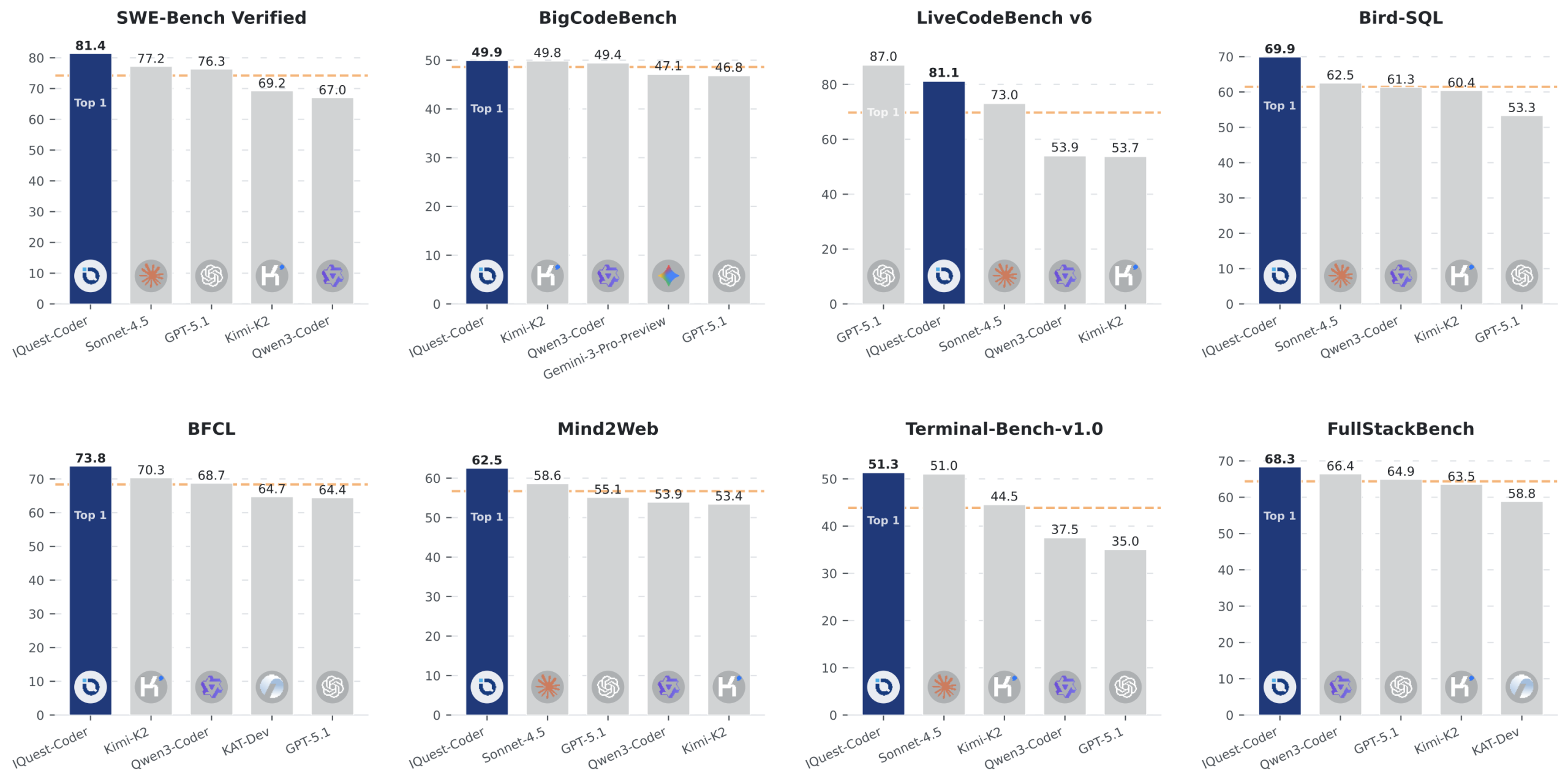
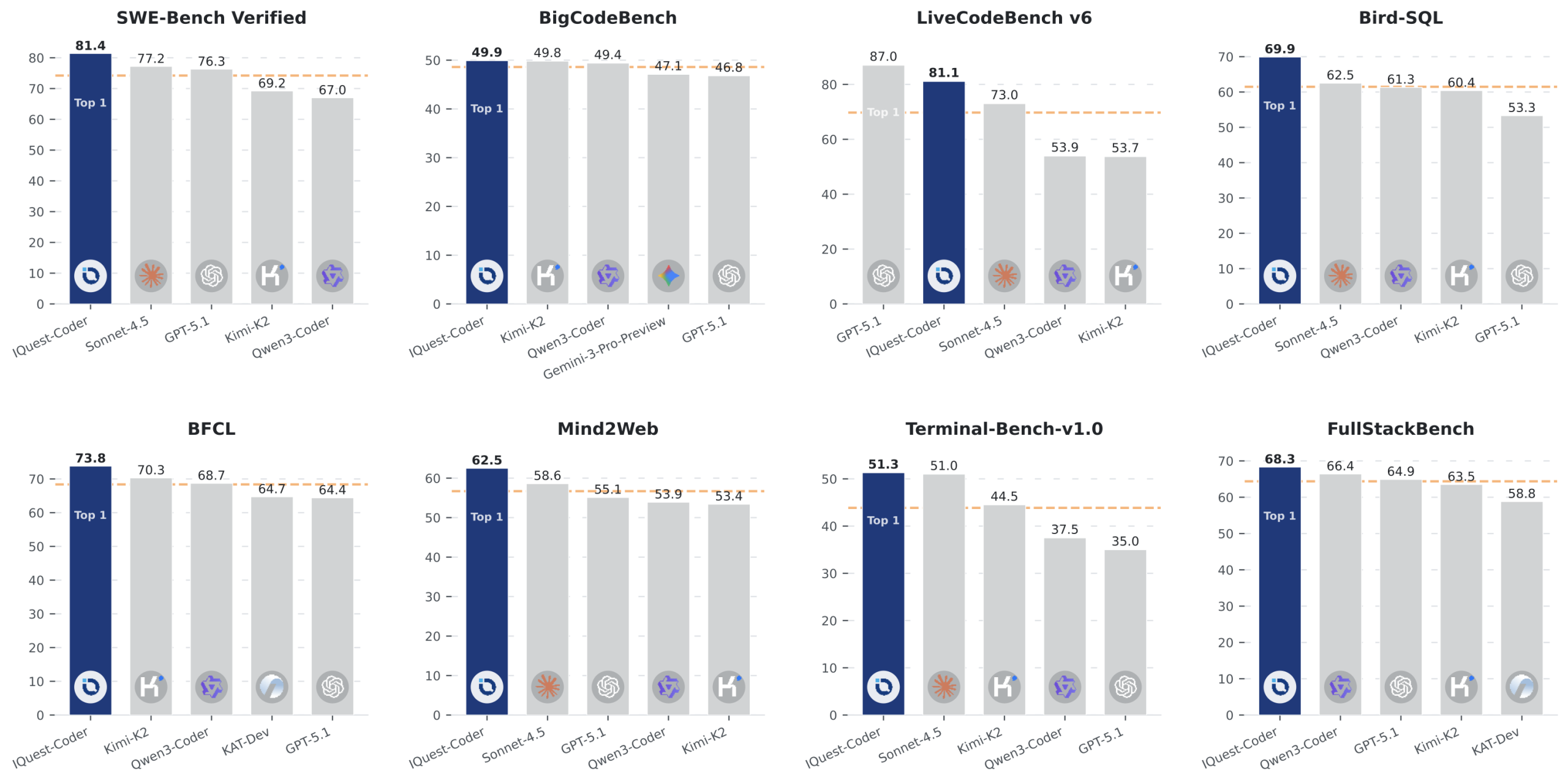
The claims are eye-catching: 81.4% on SWE-Bench Verified, 81.1% on LiveCodeBench v6, and 49.9% on BigCodeBench. For context, that SWE-Bench score puts it in the company of models several times its size and computational budget. But as the model maker’s GitHub page went live, a parallel narrative unfolded on Reddit and Hugging Face: early adopters hitting walls with real-world C++ problems, quantization mysteries, and accusations of “benchmaxing” that strike at the heart of AI evaluation ethics.
The Numbers That Raised Eyebrows
Let’s start with what IQuestLab is actually claiming. Their 40B-parameter model, available in both standard and “Loop” variants, purportedly achieves:
- SWE-Bench Verified: 81.4% (surpassing Claude Sonnet and approaching GPT-5.1 territory)
- LiveCodeBench v6: 81.1% (competitive with models 3-5x its size)
- BigCodeBench: 49.9% (strong multi-language performance)
These aren’t just incremental improvements. A 40B dense model hitting 81% on SWE-Bench is the kind of result that makes AI researchers question their assumptions about scale laws. The model uses a “code-flow multi-stage training paradigm” that learns from repository evolution patterns, commit transitions, and dynamic code transformations rather than just static code snapshots.
The Quant Trading Connection
Every open-source breakthrough needs a backstory, and IQuest-Coder-V1’s is particularly telling. Community research traced the lab to a Chinese quantitative trading firm, similar to DeepSeek’s origin story. The implications are fascinating: these firms have millions in infrastructure, teams of PhDs, and codebases that would make most enterprises blush. They’re not building models for chatbot demos, they’re training on real, production-grade algorithmic trading systems where a single bug costs real money.
This context reframes the “how did they do it” question. When your day job involves optimizing high-frequency trading algorithms across distributed systems, you develop intuitions about code structure, repository evolution, and debugging workflows that academic labs might miss. The “code-flow” training paradigm starts to look less like a marketing term and more like applied domain expertise.
But it also introduces a potential conflict: quant firms are notorious for secrecy. The model is released under a custom “iquestcoder” license, not Apache 2.0 or MIT, which raises questions about commercial use and transparency.
When Benchmarks Meet Reality: The C++ Stress Test
The most damning counter-evidence comes from early adopters testing the model on actual development tasks. One developer documented their experience trying to fix C++ compilation errors that Minimax M2.1 handled effortlessly:
Task: Fix errors in console command definitions
Result: Failed with multiple C4430 (missing type specifier), C2146 (missing semicolon), and C2086 (redefinition) errors
Context: The model struggled with complex C++ syntax involvinggroupsharedmemory and console command delegates
The developer noted that IQuest-Coder-V1 “failed completely” where Minimax succeeded, despite Minimax being a 120B model that should theoretically be less efficient per parameter.
This pattern repeated across the community. Another tester achieved 55% Pass@2 on Aider Polyglot, on par with GPT-OSS-120B, but far from the SWE-Bench numbers that suggested parity with frontier models. The discrepancy between benchmark scores and real-world performance became the central tension in community discussions.
The “Benchmaxing” Debate
The term “benchmaxing”, optimizing models specifically for benchmark performance rather than general utility, dominated Reddit threads. Critics pointed to several red flags:
- Benchmark-Specific Variants: IQuestLab released separate “Loop-Thinking” and “Loop-Instruct” models, with the Thinking variant specifically tuned for LiveCodeBench
- Temperature Tuning: The evaluation parameters show suspiciously specific temperature settings (0.0 for most benchmarks, 0.6-0.95 for others)
- Trajectory Overfitting: The 32k training trajectories could represent systematic benchmark problem solving rather than general coding ability
Defenders countered that this is standard practice: Google’s Gemini 3 Flash used similar techniques, and collecting large-scale trajectories is exactly what the field needs for robust RL training. The technical report details a sophisticated multi-agent role-playing system for synthetic data generation that goes beyond simple benchmark memorization.
The debate crystallized a fundamental question: If a model achieves SOTA on benchmarks through targeted training, but fails on real-world tasks, are the benchmarks broken or is the model?
Architecture Deep Dive: Loop Mechanism and Dual Attention
Beneath the controversy lies genuine architectural innovation. The IQuest-Coder-V1-Loop variant uses a recurrent transformer design with shared parameters across two iterations, effectively creating an 80-layer model that fits in a 40B footprint. This “close the loop” mechanism optimizes the trade-off between capacity and deployment cost, a real concern for developers trying to run these models on 32GB GPUs.
The model also features dual gated attention (not hybrid, but dual), which community members discovered when examining the quantized versions. One quantizer noted the model was “supposed to be using SWA [sliding window attention], but it didn’t get used in the final version”, suggesting architectural decisions were made based on empirical performance rather than theoretical elegance.
For practitioners, this matters. The model runs on consumer hardware at usable speeds: 32.97 tokens/second on Blackwell 96GB at full context, according to one benchmarker’s report. The GGUF quantization ecosystem has already embraced it, with IQ4_XS delivering “very good numbers for coding tasks” despite aggressive compression.
The Reproducibility Challenge
IQuestLab’s GitHub repository includes the complete SWE-Bench evaluation framework and trajectory data, a move toward transparency that the community demanded after DeepSeek’s controversial release. The evaluation uses R2E-Gym, and the trajectory zip file contains full agent logs.
Yet reproducibility remains elusive. The model requires transformers>=4.52.4 and custom modeling code via Hugging Face’s auto_map feature. Deployment needs vLLM with tensor parallelism across 8 GPUs for the 40B variant. For most independent researchers, the computational cost of verifying these claims approaches the cost of training a smaller model from scratch.
This creates a trust paradox: the data is open, but verification is gated by compute access. As one Reddit commenter noted, “If we could validate this ourselves independently then it would be a huge opportunity gain for local model runners after quantizing the model.” The subtext: until then, we’re taking their word for it.
What This Means for Open-Source AI
IQuest-Coder-V1 arrives at a pivotal moment. The open-source community is still digesting DeepSeek’s impact, and frontier labs are increasingly closed. A genuine 40B model that rivals GPT-4-class coding abilities would democratize access to advanced software engineering automation.
But the benchmark-reality gap threatens to erode trust in open-source claims. If every release is met with “but does it actually work?”, the community fragments between benchmark-chasers and practitioners who’ve been burned before. The controversy around IQuest-Coder-V1 mirrors broader debates about evaluation in AI: we need benchmarks that reflect real-world use, not just academic leaderboards.
The model’s performance on LiveCodeBench v6 (81.1%) is particularly telling. LiveCodeBench is designed to be “uncheatable” with constantly refreshed problems, yet even here, the gap between benchmark performance and practical utility persists. This suggests the problem isn’t just benchmark gaming, it’s that our evaluation methodologies fundamentally misalign with how developers actually write and debug code.
The Verdict: Promise with Caveats
After reviewing community tests, technical reports, and architecture details, IQuest-Coder-V1 emerges as neither pure hype nor revolutionary breakthrough. It’s something more nuanced: a highly capable but specialized model that excels at the specific workflows its creators prioritized, likely those found in quantitative trading systems.
What it does well:
– Python and web development tasks (where most benchmarks focus)
– Repository-level understanding with its 128K context and code-flow training
– Iterative problem-solving when given clear feedback loops
– Efficient deployment through Loop architecture and GGUF support
Where it struggles:
– Complex systems languages (C++, Rust) with intricate memory models
– One-shot debugging without iterative feedback
– Tasks requiring deep framework-specific knowledge outside its training distribution
For developers, the takeaway is pragmatic: download the IQ4_XS quant, test it on your actual codebase, and ignore the leaderboard. The model might be transformative for your workflow or completely useless, benchmarks won’t tell you which.
The Bigger Picture
IQuest-Coder-V1’s release, regardless of controversy, signals a maturation of open-source AI. We’re seeing sophisticated training paradigms (code-flow), architectural innovations (Loop), and multi-million-dollar investments from unexpected players (quant firms). The community’s skeptical response, demanding reproducibility, real-world tests, and architectural transparency, is exactly what healthy science looks like.
The model’s custom license and benchmark-reality gap are red flags, but not deal-breakers. They reflect the tension between commercial AI development and open-source ideals. As one community member observed, the quant trading backing is “interesting that all these quant trading companies are stepping into llm training”, a trend that will likely accelerate.
Whether IQuest-Coder-V1 truly achieves SOTA coding performance matters less than what it represents: open-source AI is no longer just fine-tuning Llama, it’s training competitive models from scratch, with novel architectures and domain-specific optimizations that closed labs might overlook. The benchmarks may be contested, but the ambition is undeniable.
For now, the model sits at 476 GitHub stars and climbing. The real test won’t be the next leaderboard update, but whether those stars convert to production deployments. If developers start building with IQuest-Coder-V1 despite the controversy, that’ll be the only benchmark that matters.


Try it yourself: The model is available on Hugging Face with GGUF quants for local deployment. The technical report and evaluation framework are on GitHub. Just don’t be surprised if your C++ compile errors stump a model that supposedly mastered software engineering.



