
The most disruptive AI release of 2026 isn’t from OpenAI, Anthropic, or Google. It’s from a Chinese lab called MiniMax, and it’s exposing just how much margin the incumbents have been charging. Their new M2.5 model scores 80.2% on SWE-Bench Verified, within spitting distance of Claude Opus 4.6’s 80.8%, while costing roughly one-twentieth the price. At $1 per hour for continuous operation, we’re not looking at incremental improvement. We’re looking at a controlled demolition of AI pricing economics.
The Benchmark Reality: 80.2% Isn’t Just a Number
Let’s be clear about what 80.2% on SWE-Bench Verified actually means. This isn’t some synthetic coding quiz. It’s a brutal test where models must fix real GitHub issues across production codebases, Django, scikit-learn, pytest, without hand-holding. For context, GPT-4 barely cracked 30% when the benchmark debuted. The fact that a relatively unknown Chinese lab is now trading blows with Claude Opus isn’t just impressive, it’s a geopolitical statement.
According to the OpenHands Index, M2.5 sits at #4 overall, trailing only Opus variants and GPT-5.3 Codex. It’s the first open-weight model to definitively surpass Claude Sonnet, long considered the sweet spot for price-performance. The composite scores show particular strength in long-running app development tasks, exactly where smaller models typically collapse.
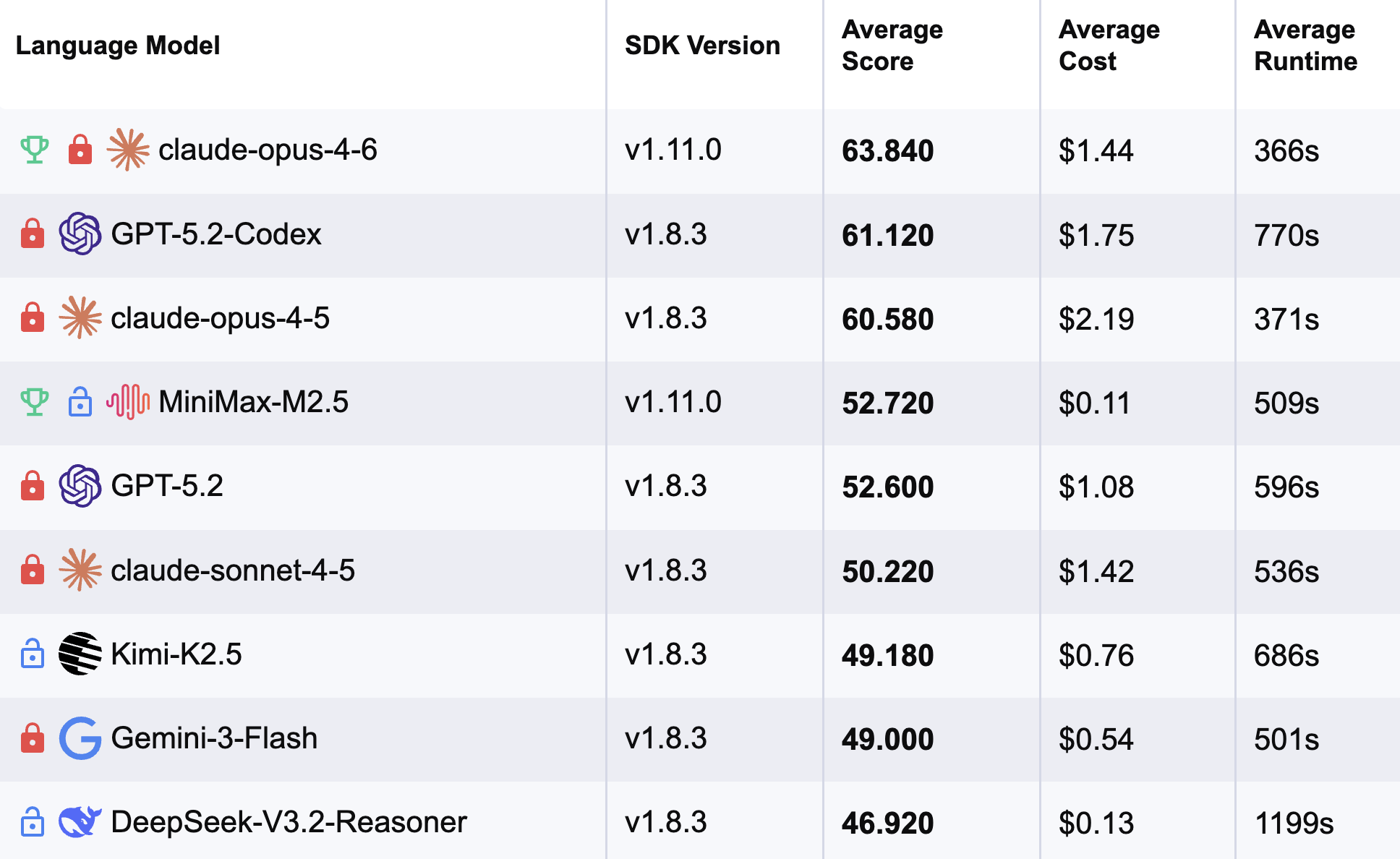
The Multi-SWE-Bench score of 51.3% is arguably more significant. This variant tests cross-repository reasoning, understanding how changes in one codebase affect another. M2.5 leads Opus 4.6 (50.3%) and crushes Gemini 3 Pro (42.7%). If you’ve ever watched an AI struggle with dependency chains, you know this is the difference between a toy and a tool.
Architecture: 230B Parameters, 10B Active, Infinite Implications
The MoE (Mixture of Experts) architecture is key here. 230 billion total parameters with only 10 billion active per token. On paper, this looks like efficiency genius. In practice, it means the model can route queries to specialized “experts” without loading the entire parameter set every forward pass.
Reddit’s r/MachineLearning crowd immediately clocked the implications. One user pointed out that this architecture makes M2.5 a prime candidate for aggressive compression techniques like REAP/REAM, potentially shrinking it to ~160GB with minimal quality loss. Another joked about zipping it to fit on a CD-ROM, then revealed they’d actually tested gzip compression on model weights, achieving 30% size reduction. The information theory takeaway? These models are still wildly redundant. There’s a PhD thesis waiting for whoever figures out how to exploit that redundancy at runtime.
The active parameter count also matters for inference speed. While you still need to host the full 230B somewhere (good luck on consumer hardware), only 10B touches each token. This enables the 100 tokens/second output speed of the Lightning variant, nearly double what most frontier models achieve.
The Cost Disruption: A 20x Price War
Here’s where things get uncomfortable for incumbents. MiniMax is charging $0.30 per million input tokens and $2.40 per million output tokens for Lightning. Compare that to Claude Opus at ~$75/M output. That’s not a discount, that’s a different business model entirely.
The math is brutal: running M2.5 Lightning continuously at 100 TPS costs $1/hour. At 50 TPS (standard variant), it drops to $0.30/hour. MiniMax claims four instances running 24/7 for a year costs $10,000. For comparison, a single Claude Opus instance would run you roughly $200,000 for the same period.
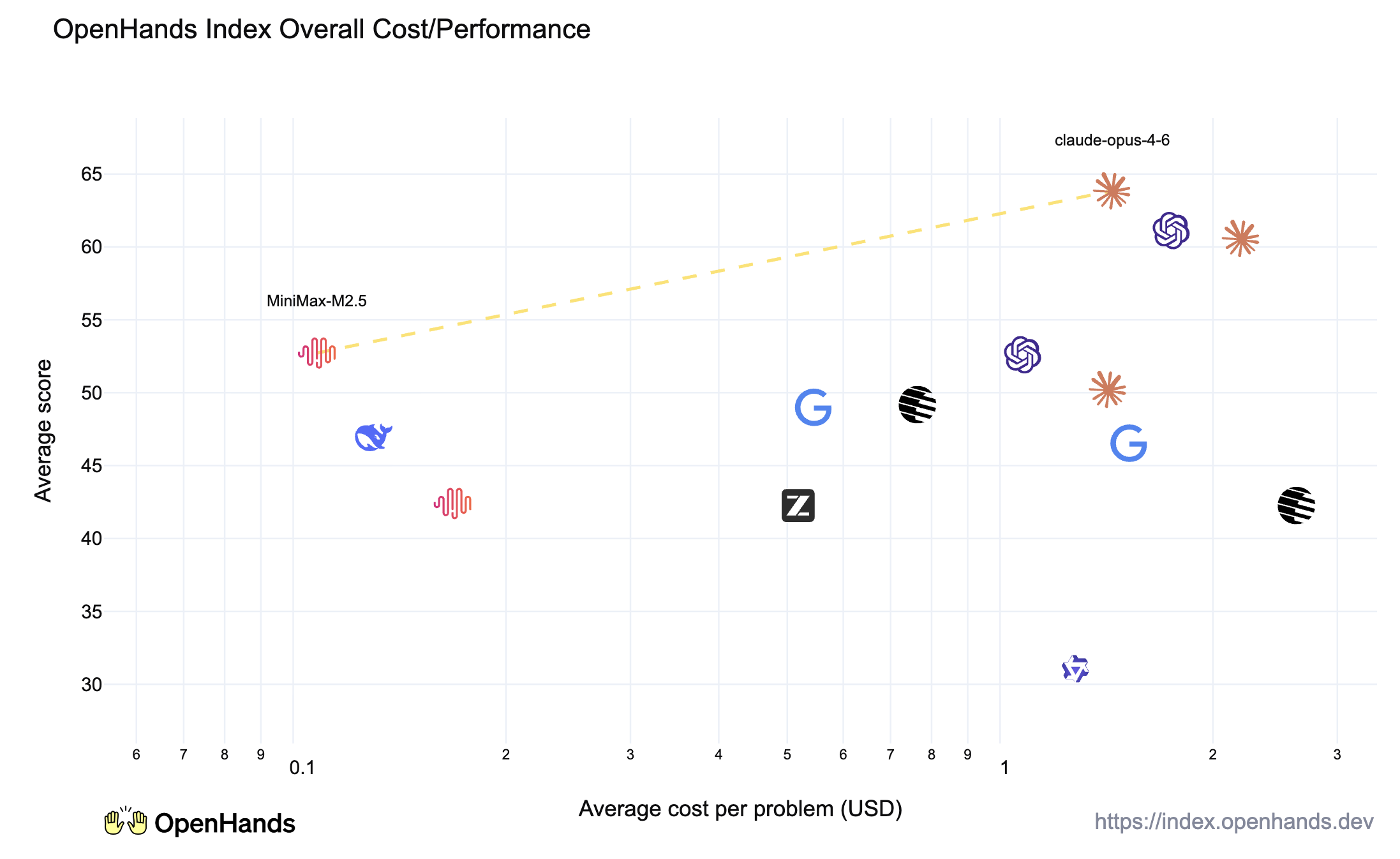
The developer community is simultaneously thrilled and skeptical. One Reddit commenter noted that at these prices, “you can have four M2.5 instances running continuously for an entire year for $10,000”, but immediately questioned profitability. The energy costs alone would eat half that budget. The consensus? MiniMax is either running at a massive loss to gain market share, or they’ve cracked efficiency in ways Western labs haven’t.
This pricing strategy directly challenges the entire API economy built by OpenAI and Anthropic. When MiniMax M2, the predecessor to M2.5 launched, it was already undercutting competitors. M2.5 takes this to an extreme that feels unsustainable, for everyone else.
RL Scaling: The Forge Framework’s Secret Sauce
Most frontier models use RLHF (Reinforcement Learning from Human Feedback). MiniMax built something different: Forge, an agent-native RL framework that trains models by deploying them into live environments.
The numbers are staggering: 200,000+ training environments spanning code repositories, web browsers, office applications, and API endpoints. Forge achieves a 40x training speedup through asynchronous scheduling and tree-structured sample merging. This isn’t theoretical, MiniMax reports that 30% of their company’s daily operations are now autonomously completed by M2.5, including R&D, product, sales, HR, and finance functions. Their own codebase is 80% AI-generated.
The CISPO algorithm (Clipped Importance Sampling Policy Optimization) stabilizes training for MoE architectures at scale. Combined with process-based rewards that evaluate entire task trajectories rather than single outputs, M2.5 learns to plan like an architect before writing code. This explains the strong performance on multi-step benchmarks like BFCL Multi-Turn (76.8% vs Opus’s 63.3%).
This approach fundamentally differs from the human preference tuning that dominates Western labs. While Anthropic hires thousands of contractors to label “good” vs “bad” responses, MiniMax lets models learn by actually doing the work. It’s a distinction that shows up clearly in tool-use benchmarks where M2.5 completes tasks with 20% fewer rounds than its predecessor.
The Agentic Angle: More Than Just a Code Monkey
M2.5’s capabilities extend beyond coding into what MiniMax calls “office work”, Word formatting, PowerPoint creation, Excel financial modeling. This is where the “digital employee” marketing starts to feel less like hype and more like product strategy.
The model achieved 59% win rate on internal evaluations against mainstream models across document editing, spreadsheet manipulation, and presentation building. On the MEWC benchmark (Microsoft Excel World Championship problems), it scored 74.4%. For finance teams drowning in quarterly reporting, a $1/hour AI that can build DCF models is a no-brainer.
MiniMax has productized this through their Agent platform, which provides pre-built “Office Skills” and “Experts”, domain-specific agent configurations. Users have created over 10,000 custom Experts. This positions MiniMax not as a model provider, but as an enterprise automation platform competing directly with Microsoft Copilot and Google Gemini.
The China’s AI agent rivalry between GLM-5 and MiniMax M2.5 reflects a broader strategic battle: Chinese labs are moving from model releases to full-stack platforms much faster than their US counterparts.
The Open Weights Question: Trust, But Verify
Here’s where the community’s enthusiasm meets cold reality. MiniMax promised open weights. The Hugging Face repo is still empty days after launch. An American infrastructure company called NovitaAI is already hosting M2.5 on OpenRouter, but latency metrics suggest it’s just a passthrough to MiniMax’s API. No one has actually seen the weights.
This isn’t MiniMax’s first rodeo with retracting open-source promises. The M2.1 release followed a similar pattern: big promises, delayed delivery. The AI community has a long memory for this kind of behavior. One Reddit user dryly noted they’re “waiting for the open weights on HF” with the patience of someone who’s been burned before.
The implications are significant. If M2.5 truly goes open-weight, it becomes a cost-effective inference target for commodity hardware. If it doesn’t, it’s just another API product with aggressive pricing. The difference determines whether this is a democratization moment or just a pricing war.
Competitive Landscape: China’s AI Chess Game
M2.5 doesn’t exist in isolation. It dropped the same week as Z.ai’s GLM-5, which also beat Gemini 3 Pro on key benchmarks. The GLM-5, a competing large-scale Chinese language model shows China isn’t pursuing a monolithic AI strategy, it’s a multi-horse race.
The compute bottleneck is real, though. China’s AI compute bottlenecks affecting large model development have forced labs to optimize harder. US sanctions on H100s mean Chinese companies can’t just throw more GPUs at the problem. This constraint is producing innovation: better MoE architectures, more efficient RL, aggressive quantization.
The BFCL Multi-Turn leaderboard now has three Chinese models in the top 5. The SWE-Bench Verified top 10 is similarly dominated. The narrative that China is “catching up” misses the point, they’re already competing on equal footing, with different constraints driving different optimizations.
The Vibe Check: When Benchmarks Meet Reality
OpenHands’ testing reveals the gap between benchmark scores and production usability. M2.5 excels at long-running tasks like building apps from scratch, areas where smaller models typically fail. But it struggles with instruction-following, occasionally forgetting to add answers between solution tags or pushing to the wrong Git branch.
One Reddit developer who tested M2.5 against GLM-5 reported that despite higher benchmarks, M2.5 “didn’t follow implementation details really well” and produced non-functioning code that it blamed on “compiler caching issues.” The vibe was worse than the numbers suggested.
This highlights a critical truth: benchmarks are necessary but insufficient. SWE-Bench tests a specific scaffolding (Claude Code with overridden prompts). Performance on Droid (79.7%) and OpenCode (76.1%) harnesses shows strong generalization, but real-world usage surfaces edge cases. The model is capable, but not magical.
The Profitability Paradox: Who’s Subsidizing Whom?
At $1/hour, the economics don’t pencil out. A back-of-envelope calculation: 100 TPS × 3600 seconds = 360,000 tokens/hour. At $2.40/M output, that’s $0.86/hour in revenue. Subtract inference costs on H800s, infrastructure, engineering support, it’s a loss leader.
This suggests three possibilities:
1. Subsidized growth: MiniMax is burning VC money to gain market share, planning to raise prices later (the Uber model).
2. Efficiency breakthrough: They’ve achieved inference costs far below industry norms through architectural innovations.
3. Strategic value: The model is a loss leader for their Agent platform and enterprise services.
The third option seems most likely. By making the base model cheap, they create a funnel for higher-margin products. It’s the same playbook that made AWS dominant, commoditize your complement.
This strategy has implications for Z.ai’s commercialization and implications for open model availability in China. As Chinese AI companies face pressure to justify valuations, the “free model” era may end. MiniMax’s pricing could be a temporary window before enterprise lock-in.
The Real Impact: What Changes Monday Morning
For developers, M2.5 means you can now run sophisticated coding agents at scale without bankruptcy. A startup can afford 24/7 agentic code review, documentation generation, and testing. The cost barrier to agentic workflows has effectively disappeared.
For enterprises, the math is compelling: four instances for $10K/year vs. $200K+ for Claude. The catch is data sovereignty and compliance, sending code to a Chinese API gives security teams hives. Open weights would solve this, enabling on-prem deployment.
For AI labs, MiniMax just reset the price-performance curve. Every model roadmap now needs to answer: “Can you beat 80.2% at $2.40/M output?” The margin compression will be brutal. Anthropic’s $18B valuation assumes Opus maintains premium pricing. That assumption just shattered.
The broader implication is that AI capabilities are commoditizing faster than anyone predicted. The gap between “frontier” and “open” models has collapsed from years to months. Unsloth’s MoE optimization breakthroughs show the community can further accelerate this trend.
The Bottom Line: A Wake-Up Call, Not a Victory Lap
MiniMax M2.5 is simultaneously overhyped and underappreciated. The benchmark scores are real, the cost advantage is massive, and the RL innovation is substantive. But the delayed open-weight release, occasional instruction-following failures, and questionable unit economics mean you shouldn’t cancel your Claude subscription just yet.
What it definitively proves is that the AI race is now global, multi-polar, and moving at a pace that makes six-month roadmaps feel geological. The US labs’ comfortable lead has evaporated. The question isn’t whether Chinese models can compete, it’s whether Western business models can survive the pricing pressure.
The $1/hour AI employee isn’t science fiction anymore. It’s here, it works, and it’s priced to move. The only question is: who’s ready to hire it?

For more on the evolving AI landscape, check out our analysis of China’s AI agent war between GLM-5 and MiniMax M2.5 and the technical architecture behind MiniMax’s MoE efficiency.



