The AI coding assistant market has been stuck in a frustrating loop: either pay premium API fees for capable models or wrestle with local models that promise efficiency but deliver glacial speeds and reliability issues. Alibaba’s Qwen3 Coder Next just torched that compromise. Users report it’s the first sub-60GB coding model that’s both fast enough for interactive work and reliable enough to trust with real repositories, no reasoning loops, no mystery failures, just consistent performance.
The 3B Parameter Punch That Hits Like 80B
Let’s cut through the architecture marketing. Qwen3 Coder Next is an 80-billion parameter Mixture-of-Experts (MoE) model that activates only 3 billion parameters per token. That’s not a typo, 3B active parameters, total. The model uses a hybrid attention mechanism combining Gated DeltaNet (linear complexity) with traditional attention layers, structured in twelve blocks of three DeltaNet layers followed by one attention layer. Each block feeds into a sparse MoE layer with 512 experts, activating only 10 experts plus 1 shared expert per token.
This isn’t just academic efficiency theater. The math translates directly to hardware reality: you can run the Q4_K_XL quantized version in under 46GB of VRAM while maintaining 30 tokens per second generation speed. On a modest 24GB GPU with 64GB system RAM, one developer achieved 180 TPS prompt processing and 30 TPS generation using aggressive offloading strategies.
The key architectural decision? No internal reasoning loops. While models like QwQ and DeepSeek-R1 get bogged down in multi-step chain-of-thought processes that can spiral into infinite recursion, Qwen3 Coder Next is an instruct-based MoE that generates tokens directly. For interactive development where you’re iterating rapidly, this design choice alone eliminates the “will it finish or hang?” anxiety that plagues reasoning models.
Benchmarks That Actually Matter for Real Work
The official numbers tell a compelling story, but the community’s real-world testing reveals something more important: these benchmarks translate to practical utility.
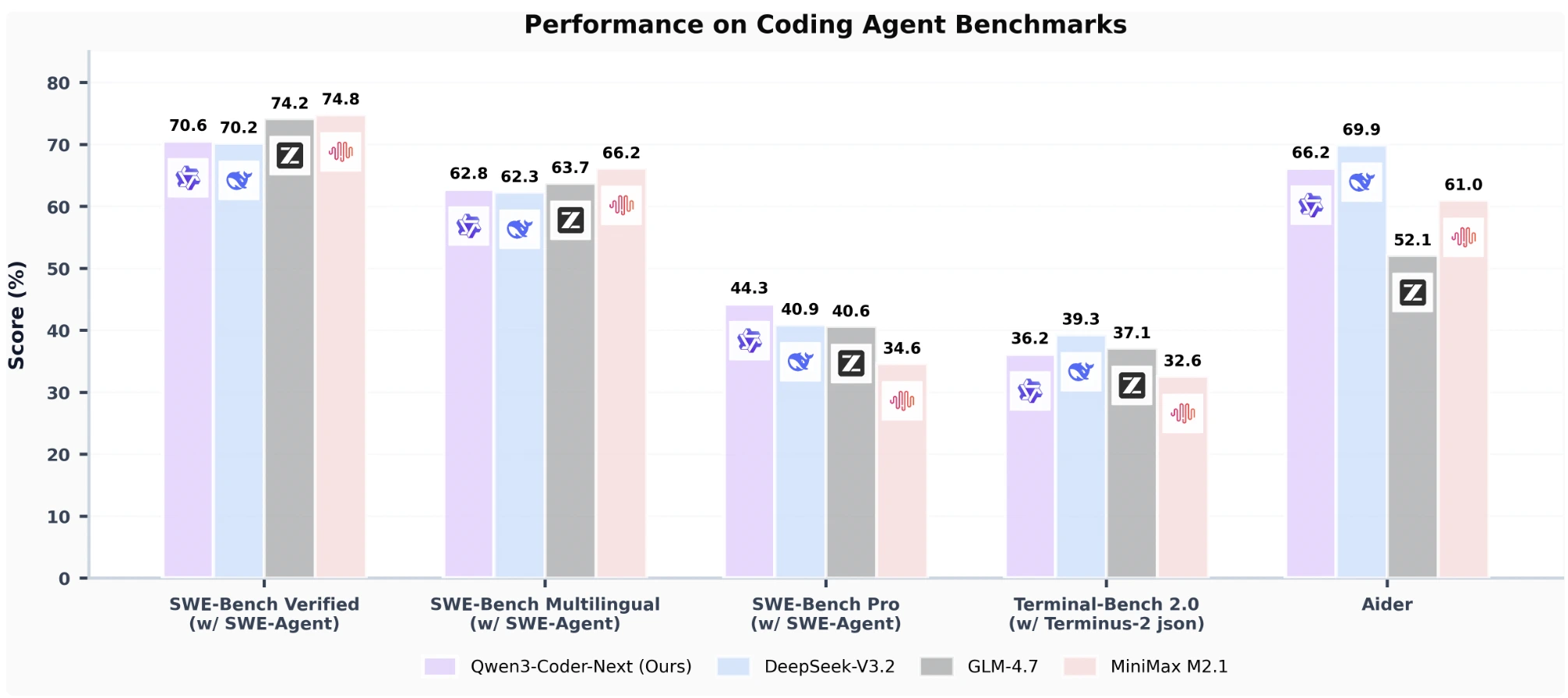
| Benchmark | Qwen3 Coder Next | DeepSeek-V3.2 | GLM-4.7 | Claude Opus 4.5 |
|---|---|---|---|---|
| SWE-Bench Verified | 70.6% | 70.2% | 74.2% | ~72% |
| SecCodeBench | 61.2% | 58.4% | 59.1% | 52.5% |
| CWEval (func-sec@1) | 56.32% | 54.1% | 55.8% | 49.7% |
The 70.6% SWE-Bench Verified score puts it within striking distance of models activating 10-20x more parameters. But the real story is the 8.7 percentage point gap on secure code generation over Claude Opus 4.5. For teams where compliance and security aren’t just buzzwords, an open-source model that leads on security metrics while running locally represents a fundamental shift in risk calculus.
One developer testing on actual production codebases noted: “It finally handles a moderately complex codebase with custom client/server components, different languages, protobuf definitions, and quirks. It answers extreme multi-hop questions and makes reliable full-stack changes.” This isn’t LeetCode toy problems, this is the messy reality of existing software.
The llama.cpp Tuning Deep Dive
Getting these numbers isn’t plug-and-play. The community has discovered specific optimizations that make or break the experience. Here’s the configuration that delivered 180 TPS prompt processing:
set GGML_CUDA_GRAPH_OPT=1
llama-server -m Qwen3-Coder-Next-UD-Q4_K_XL.gguf \
-ngl 99 -fa on -c 120000 \
--n-cpu-moe 29 --temp 0 \
--cache-ram 0Key insights from the trenches:
--temp 0: Eliminates the occasional hallucination token that can derail code generation. For instruct models doing deterministic work, creativity is a bug, not a feature.--cache-ram 0: Despite promises of 30ms cache updates, real-world usage showed 3-second query times. Disabling it for single-conversation workflows removes the bottleneck.GGML_CUDA_GRAPH_OPT: Experimental but delivers measurable TPS gains. It can break some models, but Qwen3 Coder Next handles it reliably.--n-cpu-moe 29: Offloading MoE experts to CPU while keeping attention layers on GPU creates an optimal balance for 24GB cards.
The --fit parameter in recent llama.cpp versions automates this tuning. One tester on dual RTX 3090s found --fit on --fit-ctx 262144 delivered 42-53 tokens/second, automatically balancing layers across GPUs better than manual --ot configurations. The model’s ultra-sparse nature (only 3.75% of parameters active) makes it uniquely suited to this auto-offloading approach.
When “Usable” Beats “State-of-the-Art”
The controversial take: Qwen3 Coder Next isn’t trying to beat Claude Opus 4.5 on every metric, and that’s exactly why it wins for most developers. The gap between 70.6% and 74% on SWE-Bench is negligible when you factor in the practical differences:
- Cost: Running locally costs pennies in electricity versus $20+ per task with cloud APIs
- Latency: No network roundtrips, no rate limiting, no mysterious slowdowns during peak hours
- Privacy: Your entire codebase stays on your hardware
- Control: No sudden API changes or access restrictions (remember Anthropic’s January 9th lockdown?)
The model’s sweet spot is “good enough” performance at interactive speeds. As one developer bluntly stated: “For regular day-to-day dev work, it’s no longer needed to have the latest and greatest. Q3CN is the first local model that’s usable for me in this area.” When you’re iterating on features, fixing bugs, or refactoring, the difference between 70% and 74% solution accuracy is dwarfed by the ability to get results in seconds rather than minutes.
The Multi-GPU vs. Single-GPU Reality Check
Performance scales dramatically with proper hardware utilization. On dual RTX 3090 systems, increasing --ubatch-size and --batch-size to 4096 tripled prompt processing speed. The model’s architecture allows linear layer splitting across GPUs without the graph fragmentation that plagues manual configurations.
The community has moved beyond simplistic layer offloading. Instead of dumping entire blocks to CPU, the optimal strategy involves:
– Attention layers stay on GPU (they’re the latency bottleneck)
– MoE experts distribute across available VRAM
– KV cache gets aggressively quantized
– Context compaction runs during idle moments
This nuanced approach yields 2.5x speedups while maintaining model quality. The alternative, throwing more GPU memory at the problem, works, but defeats the sub-60GB value proposition.
Integration with Agentic Workflows
Qwen3 Coder Next shines in agentic coding environments like OpenCode and Roo Code. The model’s reliability on tool calls makes it practical for autonomous workflows. However, there’s a critical configuration difference:
OpenCode defaults to permissive mode, running shell commands without confirmation. This enables smooth automation but risks environment-breaking changes when the model gets confused.
Roo Code defaults to asking permission for everything, creating a tedious confirmation loop. The fix is a carefully tuned permission list that allows safe operations while blocking destructive ones.
Both frameworks work, but OpenCode’s default autonomy once drove the model to uninstall and reinstall packages in a failed debugging attempt, breaking the development environment. The lesson: even with a capable model, guardrails matter.
The 60GB Threshold: Why It Matters
The sub-60GB specification isn’t arbitrary. It represents the tipping point where consumer hardware becomes viable:
- RTX 4090: 24GB VRAM + system RAM offloading = usable
- Mac Studio M3 Ultra: 64GB unified memory = excellent performance
- RX 7900 XTX: 24GB VRAM = community-confirmed viable
This accessibility unlocks a developer segment that cloud APIs can’t serve: those working on proprietary code, air-gapped systems, or simply tired of subscription fatigue. The model’s 370 programming language support (up from Qwen2.5 Coder’s 92) means it handles polyglot codebases without the context-switching overhead of multiple specialized tools.
The Open-Source Moat Deepens
Qwen3 Coder Next arrives at a pivotal moment. When Anthropic restricted third-party tool access, developers started treating open-source models as insurance. The sentiment on developer forums is clear: platform lock-in is now a recognized risk, and local models are the hedge.
The model’s Apache 2.0 license enables commercial use without the legal ambiguity of some “open” releases. Combined with the technical capability to run locally, this creates a genuine alternative to cloud dependency. The integration of Qwen3-Next into llama.cpp for local AI execution further solidifies this ecosystem, making deployment increasingly turnkey.
Tencent’s broader strategy becomes apparent when you see their open-source AI ecosystem including Qwen3-Coder-Next and Qwen3-TTS Studio. They’re not releasing isolated models, they’re building a parallel infrastructure where developers retain control.
Trade-offs and Honest Limitations
This isn’t magic. The model has clear boundaries:
- Advanced problem solving: For novel algorithm design or architectural planning, larger models still outperform. One developer’s workflow uses GPT-5.2 Codex for high-level design, then Qwen3 Coder Next for implementation.
- Context saturation: At 256K tokens (extendable to 1M), it’s generous but not infinite. Massive monorepos still require selective context loading.
- Quantization sensitivity: The Q4_K_XL quant works reliably, but some report the Q8 REAP quant produces more errors, possibly due to outdated calibration or REAP-specific issues.
The model also occasionally needs “reminders” to go deeper on complex changes, showing a slight laziness compared to frontier models that aggressively pursue optimal solutions. For routine development, this is fine. For breakthrough innovation, you’ll still want backup.
The Bottom Line: A New Baseline for Local AI
Qwen3 Coder Next doesn’t win every benchmark, but it wins where it counts: making local AI coding assistants genuinely usable. The combination of sub-60GB footprint, 30+ TPS generation speeds, and reliable tool use creates a practical tool that developers can integrate into daily workflows without constant babysitting.
The 70.6% SWE-Bench score isn’t just a number, it’s proof that sparse architectures have matured from research curiosity to production viability. When you can run a model locally that outperforms Claude on security benchmarks while costing essentially nothing per token, the economic argument for cloud APIs starts collapsing.
For engineering teams evaluating AI infrastructure, the question shifts from “which API provider?” to “how much hardware should we own?” The answer increasingly looks like: enough to run Qwen3 Coder Next at scale, with cloud access reserved for the 5% of tasks requiring frontier reasoning.
The model is available on Hugging Face and ModelScope. If you’re still paying per-token for routine coding tasks, you’re already behind.

Ready to deploy? Check out the Qwen3-TTS low-latency performance claims to see how the broader Qwen3 ecosystem handles real-time applications, and explore Tencent’s open-source AI ecosystem for complementary tools that keep your entire pipeline local.