16 articles found
Tracking DDR5 across four EU countries reveals a 28% price drop in under a month. Germany is 20% cheaper than the Netherlands. Here’s what it means for local LLM builders.
Open model makers are skipping the sweet spot for unified memory owners. A deep dive into the gap, the hardware, and what we can do about it.
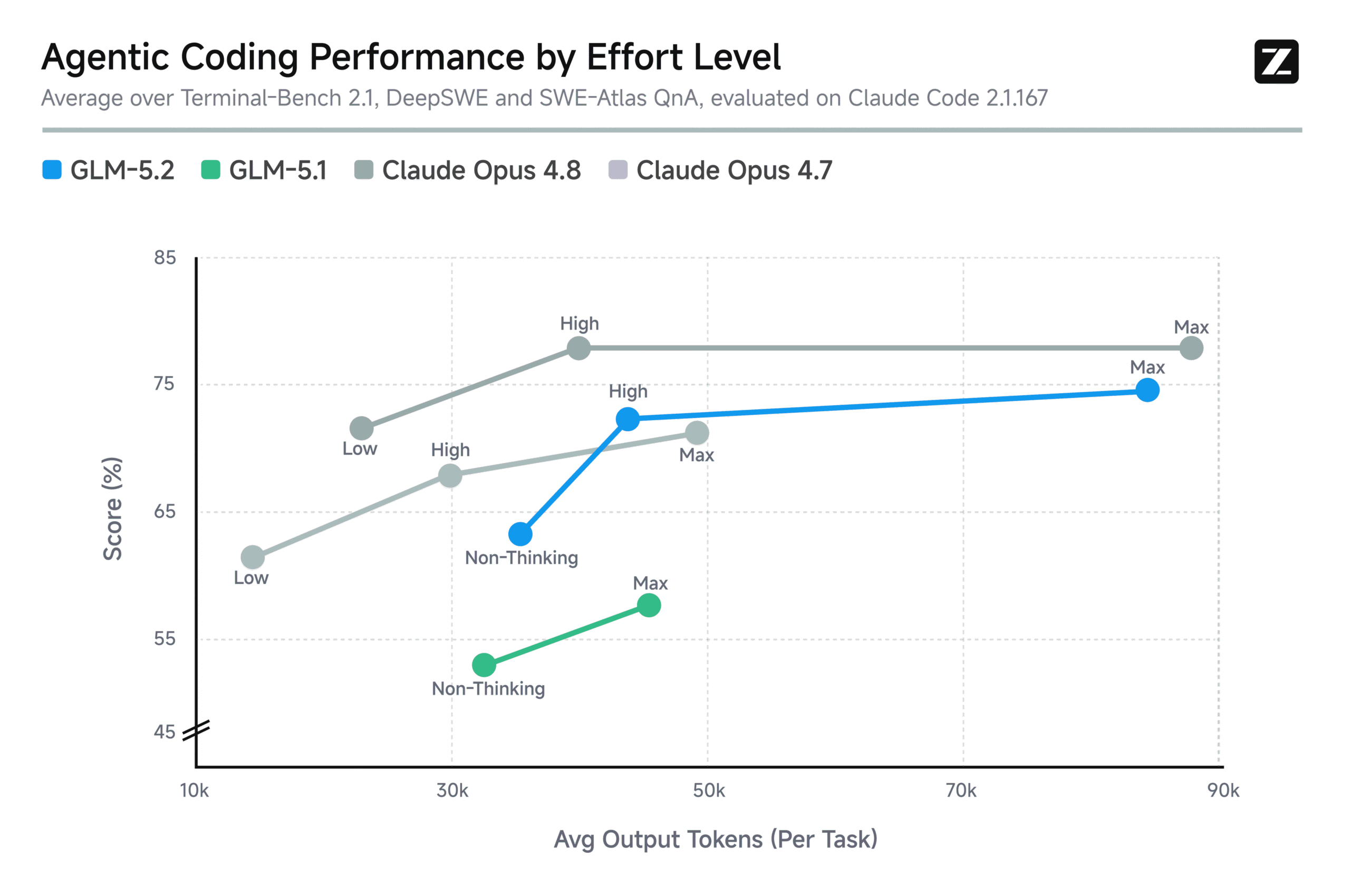
GLM-5.2 is the third-best model overall, but its MIT license means the real magic, distillation into small, local models, hasn’t even started yet.
Google DeepMind’s Gemma 4 12B brings video, audio, and text processing to standard laptops with 16GB RAM. No cloud, no subscription, just pure local intelligence.
Google DeepMind’s Gemma 4 12B kills separate vision and audio encoders, bringing native multimodal AI to 16GB laptops. We dig into the architecture, benchmarks, and why the community is begging for a 124B monster.
PrismML’s Bonsai Image 4B compresses a 16GB model to 3GB using 1-bit quantization, running entirely in-browser on WebGPU. Here’s the technical breakdown and the controversy around attribution.
Microsoft’s clever twist on the ‘local AI’ promise forces developers to pay for GitHub Copilot, even when the models are running on their own hardware.
The new Medusa-style MTP support in llama.cpp beta isn’t just catching up, it threatens to rewrite the economics of local model serving.
Qwen 3.6 27B on consumer hardware is disrupting the SaaS subscription model. Here’s how, and why it’s a warning sign for cloud AI.
How Qwen3-VL-Embedding enables semantic video search locally without transcription APIs, cutting costs from $2.84/hour to zero while keeping your data private.
Technical autopsy of why NVIDIA’s highly anticipated Nemotron 3 4B collapsed under reasoning benchmarks while Qwen 3.5 4B sailed through, despite the hype around Elastic compression and Mamba-2 hybrids.
Qwen3 Coder Next delivers 70.6% SWE-Bench performance with only 3B active parameters, running comfortably under 60GB and finally making local AI coding assistants genuinely usable for interactive development.
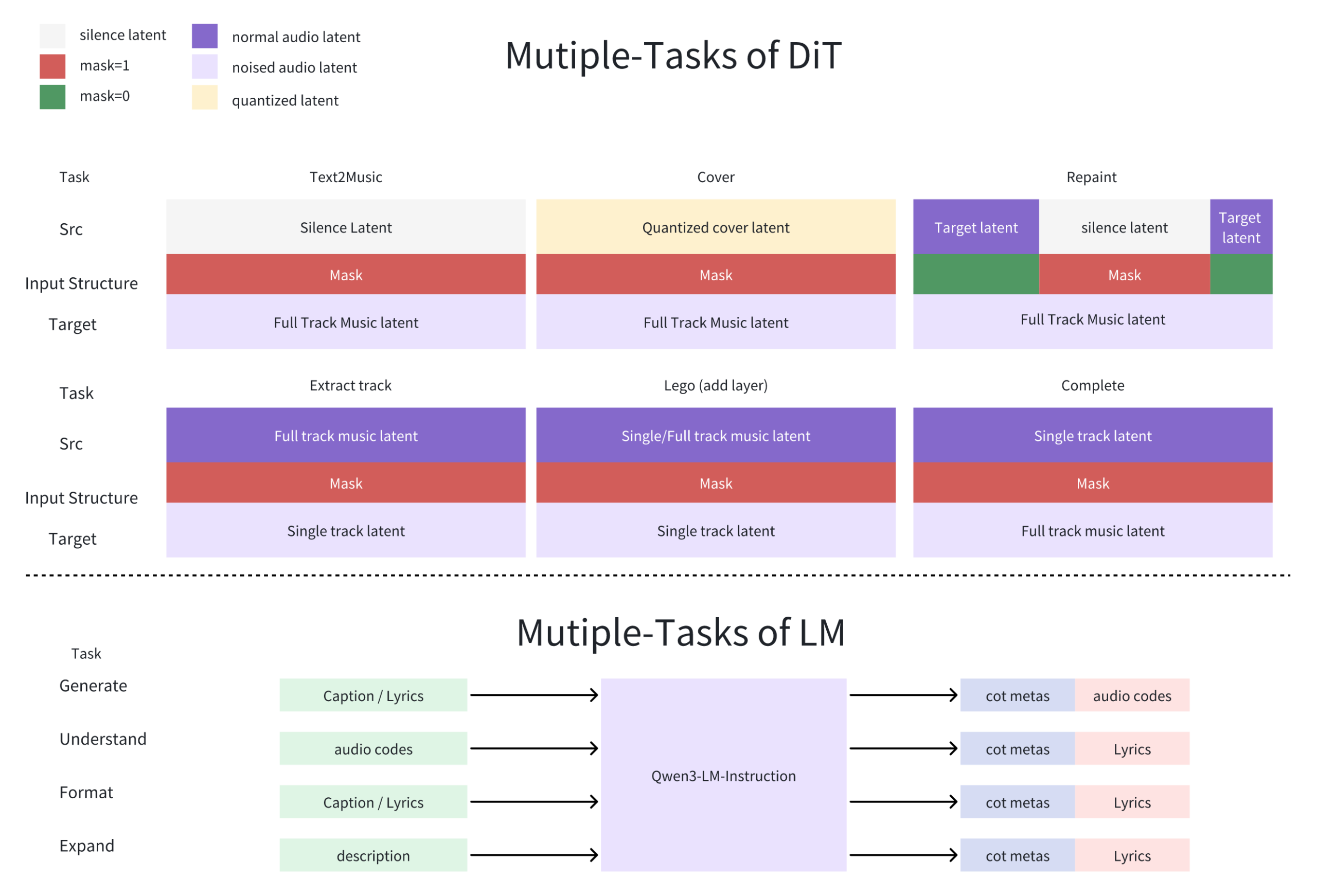
The open-source music generation model that generates songs in 2 seconds on an A100, runs on 4GB VRAM, and beats Suno on key benchmarks, while giving creators full commercial rights.
Unsloth’s aggressive 2-bit quantization slashes GLM-4.7 from 400GB to 134GB, forcing a reckoning with what ‘good enough’ means for frontier models
A deep technical analysis of an 8x Radeon 7900 XTX build running local LLM inference at 192GB VRAM, exposing the cost-performance gap between DIY consumer hardware and cloud AI infrastructure.
The new router mode in llama.cpp server enables dynamic model loading and switching without restarts, bringing enterprise-grade flexibility to local LLM deployment while exposing new resource management challenges.