ACE-Step 1.5: How MIT Just Shook Up the AI Music Industry
The AI music generation scene has been dominated by gated APIs and subscription tiers that charge you per minute of audio. Suno built a moat around convenience: give us your credit card, and we’ll give you radio-ready tracks from a prompt. That model just collided with a 2-billion-parameter wrecking ball called ACE-Step 1.5, and the debris is scattering across GitHub, Hugging Face, and consumer GPUs everywhere.
This isn’t another research demo that buckles under real-world use. ACE-Step 1.5 ships with an MIT license, generates full songs in under 2 seconds on an A100, runs locally on hardware as modest as a 4GB VRAM GPU, and, most provocatively, beats Suno v4.5 and v5 on common evaluation metrics. The claim isn’t just marketing fluff, it’s backed by a peer-reviewed paper and a model zoo that puts the entire stack in your hands.
The Benchmarks That Matter
Let’s cut to the numbers. The research team evaluated ACE-Step 1.5 against commercial heavyweights (Suno v4.5, v5, Udio-v1.5, MinMax-2.0) and open-source contenders (HeartMuLa, DiffRhythm 2, Yue). The results show ACE-Step 1.5 scoring 8.09 on SongEval, outpacing Suno v5’s 7.87 and MinMax-2.0’s 7.95. On Style Alignment, it hits 6.47, competitive with Suno v5’s 6.51. Lyric Alignment? 4.72, effectively tied with Suno v5’s 4.71.
| Model | AudioBox ↑ | SongEval ↑ | Style Align ↑ | Lyric Align ↑ |
|---|---|---|---|---|
| Suno-v5 | 7.69 | 7.87 | 6.51 | 4.71 |
| ACE-Step 1.5 | 7.42 | 8.09 | 6.47 | 4.72 |
| MinMax-2.0 | 7.71 | 7.95 | 6.42 | 4.59 |
| Udio-v1.5 | 7.45 | 7.65 | 6.15 | 4.15 |
But raw scores only tell half the story. The model’s generation speed is 10, 120× faster than alternatives. A 4-minute song that takes Suno minutes to produce lands in under 2 seconds on an A100. Even on an RTX 3090, you’re looking at under 10 seconds. For creators iterating on ideas, this collapses the feedback loop from “grab coffee while you wait” to “blink and it’s done.”
Why Local Execution Changes Everything
The commercial AI music paradigm runs on APIs because the models are too large, too specialized, or too legally encumbered to ship. ACE-Step 1.5 flips this by running on less than 4GB of VRAM. One developer reported generating a full song in 30 seconds on an old GTX 1080 with 8GB RAM. Another benchmarked 7.7 seconds on an RTX 5090 for a minute of audio.
This isn’t just about saving GPU costs. Local execution means:
– No subscription lock-in: You own the model, the weights, the outputs.
– No data exfiltration: Your musical ideas never leave your machine.
– No rate limits: Generate 8 songs simultaneously in batch mode.
– Commercial freedom: The MIT license lets you sell, remix, or integrate without royalty nightmares.
The implications ripple through the creator economy. A YouTuber can generate background music without worrying about Content ID claims. A game developer can ship a soundtrack generated on their laptop. A startup can build a music product without negotiating enterprise API contracts. The open-source AI music generation with local execution and commercial use model just became a viable business strategy.
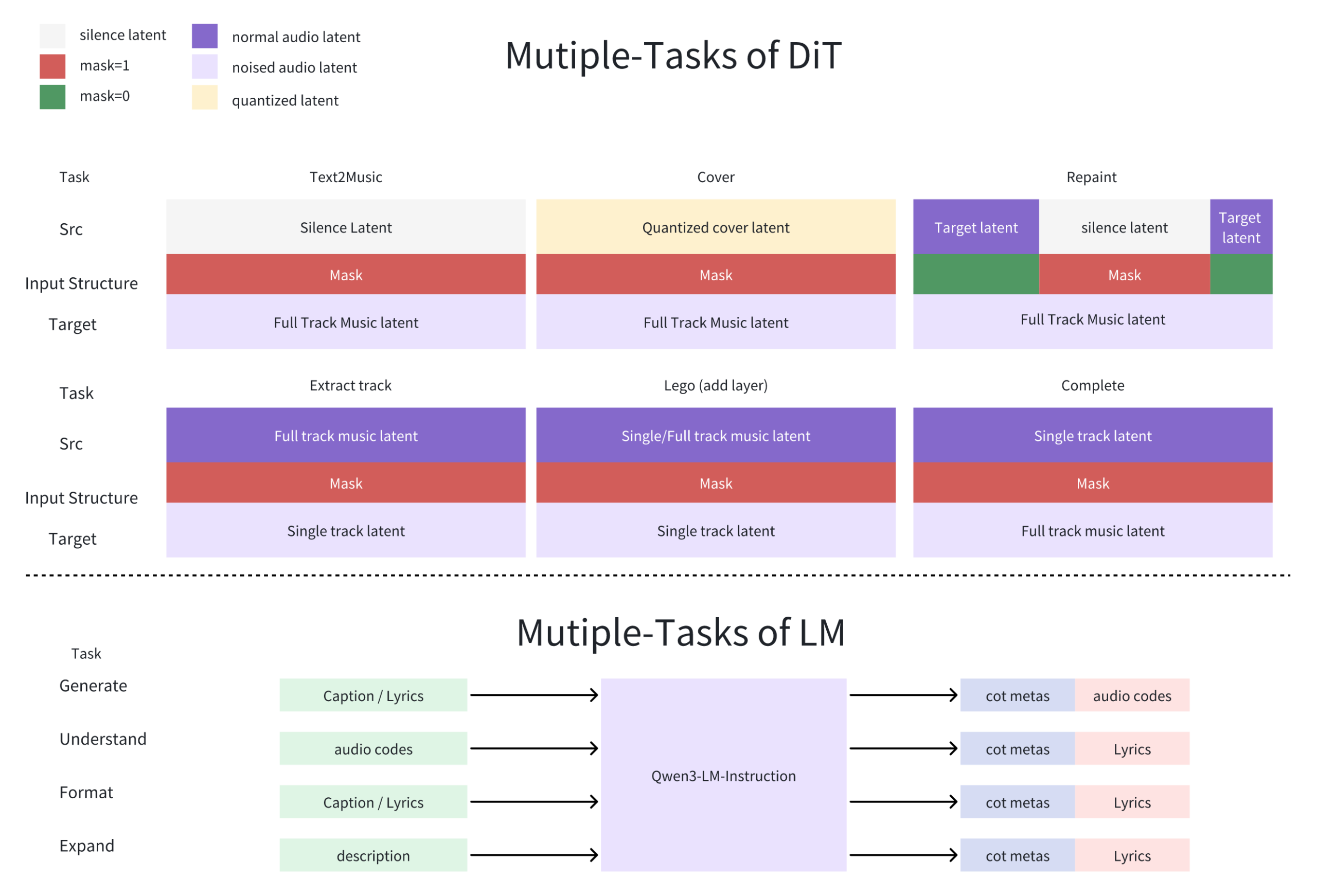
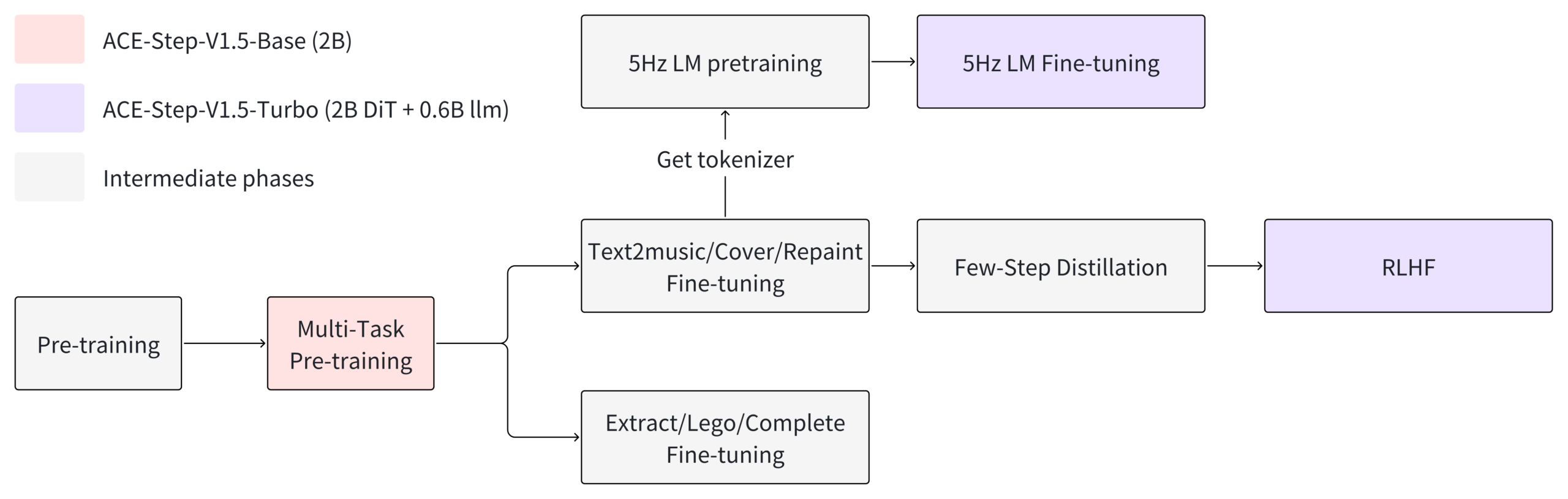
Architecture: When Language Models Become Composers
ACE-Step 1.5’s secret sauce is a hybrid architecture where a Language Model functions as an omni-capable planner. Unlike diffusion models that treat music as pure waveform prediction, ACE-Step uses an LM to transform simple user queries into comprehensive song blueprints. The LM synthesizes metadata, lyrics, and captions via Chain-of-Thought, then guides a Diffusion Transformer (DiT) to render the audio.
This LM-DiT coupling solves a core problem in generative audio: semantic drift. Most models lose the plot halfway through a song, forgetting the genre, structure, or lyrical theme. ACE-Step’s LM maintains a running “score” of what should happen next, enforcing coherence across 10-minute compositions. The DiT handles the raw acoustic generation, but the LM acts as a conductor, ensuring the violins don’t suddenly turn into death metal guitars unless prompted.
Critically, the team used intrinsic reinforcement learning that relies solely on the model’s internal mechanisms. They ditched external reward models and human preference tuning, common sources of bias and alignment failures. The model learns to please itself, which turns out to produce more consistent musicality than trying to game a separate discriminator.
The LoRA Revolution for Music
Fine-tuning a 2B parameter model on a consumer GPU sounds like a fantasy, but ACE-Step 1.5 supports LoRA training from just a few songs. One user reported training a custom style in 1 hour on an RTX 3090 with 12GB VRAM using 8 reference tracks. The Gradio UI includes a one-click annotation pipeline that handles captioning and style extraction.
This means artists can clone their own sound without surrendering their catalog to a cloud provider. A producer could train a LoRA on their drum patterns and chord progressions, then generate infinite variations for scoring. A band could feed their demos into the model and get studio-quality arrangements back. The line between “AI-generated” and “artist-created” blurs when the artist owns the entire pipeline.
The Community’s Brutally Honest Feedback
Reddit’s r/LocalLLaMA community, known for sniffing out vaporware, has been stress-testing ACE-Step 1.5 since release. The consensus: impressive, but not perfect.
On instrumental quality: Users note that while ACE-Step handles simple arrangements beautifully, dense multi-instrumental sections can get “messy” with “ugly noise.” One tester compared it to Suno 2.5 for complex rock band simulations. The model shines when the beat is slow and the arrangement sparse, hitting Suno 4.5-level fidelity.
On prompt adherence: The demo prompts on the official site show detailed lyric structures, but early users found the model often ignores most instructions. The team admits they used synthetic captions from models like Gemini, which are notoriously bad at describing music. The result: prompts that look sophisticated but deliver generic outputs. Users are discovering that testing AI models before investing in expensive hardware is essential, ACE-Step rewards simple, direct prompts over elaborate prose.
On vocals: While the model supports 50+ languages, vocal synthesis remains “coarse” compared to Suno’s polished sheen. A developer generating a rap in a non-English language called it “flawless”, but others noted the lack of nuance in emotional delivery.
The takeaway: ACE-Step 1.5 is a foundation model, not a finished product. It’s the Linux kernel to Suno’s macOS, powerful, flexible, but requiring user expertise to shine.
The Data Question Nobody Wants to Answer
Here’s where the controversy heats up. The ACE-Step team claims their training data is “fully authorized plus synthetic.” But the Reddit hive mind is skeptical. One commenter referenced a 300TB Spotify dataset leak from weeks prior, wondering when someone would train a model on it. Another pointed out Suno’s ongoing lawsuits for allegedly training on copyrighted music.
The uncomfortable truth: we don’t know what’s in the training data. The MIT license protects the model code and weights, but it doesn’t immunize users from copyright liability if the model regurgitates protected melodies. The team encourages users to “verify originality”, which is practically impossible at scale. This is the same legal gray area haunting image models, now migrating to audio.
The community’s response has been pragmatic: open weights beat closed APIs for accountability. If a model generates a ripoff, you can inspect its internals. With Suno, you’re flying blind. But this doesn’t solve the core issue, AI music is trained on human music, and the licensing regime hasn’t caught up.
Installation: From Zero to Song in 10 Minutes
Getting started is refreshingly simple. The team ships a uv-based installer that handles dependencies automatically:
# Install uv package manager
curl -LsSf https://astral.sh/uv/install.sh | sh
# Clone and install
git clone https://github.com/ACE-Step/ACE-Step-1.5.git
cd ACE-Step-1.5
uv sync
# Launch Gradio UI
uv run acestepThe UI runs at localhost:7860 and auto-downloads models on first use. For API integration, a REST server spins up on port 8001. The entire package weighs in at under 4GB VRAM for the turbo variant, though you can scale up to a 4B parameter LM if you have the headroom.
The model zoo includes multiple variants: acestep-v15-turbo for speed, acestep-v15-sft for quality, and acestep-v15-base for experimentation. LM options range from 0.6B to 4B parameters, automatically selected based on your GPU’s memory.
The Efficiency Arms Race
ACE-Step 1.5’s speed isn’t magic, it’s architecture. The team optimized for inference efficiency from day one, unlike many models that bolt on optimizations post-training. This aligns with broader trends in AI: efficiency improvements in AI model inference and Mixture-of-Experts optimization are rewriting the rules of what consumer hardware can achieve.
The turbo variant uses only 8 diffusion steps versus 50 for the base model, trading marginal quality for massive speed gains. On an RTX 3090, generation time drops from 20 seconds to under 10. For creators iterating on ideas, this is the difference between staying in flow and context-switching to Twitter.
Bottom Line: A Tipping Point, Not a Victory Lap
ACE-Step 1.5 doesn’t kill Suno. Suno’s v5 still edges ahead on raw audio quality for complex arrangements, and its polished UX remains unmatched. But ACE-Step 1.5 proves that open-source can compete on commercial benchmarks while offering freedoms that closed platforms can’t match.
The real story isn’t the benchmarks, it’s the permission structure. With MIT licensing, local execution, and LoRA fine-tuning, ACE-Step 1.5 hands control back to creators. You don’t need to trust a startup’s data practices or pray they don’t rug-pull your API access. You download, you run, you own.
For developers, this is a green light to build music features without legal teams. For artists, it’s a tool to amplify creativity without surrendering rights. For the AI community, it’s proof that the gap between open and closed models is narrowing faster than expected.
The next year will determine whether ACE-Step becomes the Stable Diffusion of audio or fades into novelty. If the community solves the instrumental complexity and vocal nuance issues, Suno’s subscription model starts looking like a legacy business. If not, it remains a powerful tool for a niche of technically-savvy creators.
Either way, the subscription moat has been breached. The question isn’t whether open-source music AI will catch up, it’s how fast the incumbents can innovate before their users realize they don’t need to pay per minute anymore.
Quick Start for the Impatient
# Run this now, thank me later
git clone https://github.com/ACE-Step/ACE-Step-1.5.git
cd ACE-Step-1.5
uv sync
uv run acestep --init_service trueYour browser will open to a Gradio interface. Type “aggressive heavy metal with dual guitars and a raspy vocalist” and hit generate. While Suno’s servers churn, ACE-Step 1.5 will already be playing your track, locally, privately, and free.