For weeks, developers running GLM-4.7-Flash locally noticed something fishy: the model was chewing through VRAM like a model twice its size. A 4-bit quantized version would max out a 24GB RTX 4090 at just 45,000 tokens of context, far less than what the math suggested. The culprit wasn’t a memory leak or quantization artifact. It was a fundamental architectural assumption baked into every major inference engine: that all models need both K and V tensors in their KV cache.
Turns out, GLM-4.7-Flash never used the V tensor. The fix, merged into llama.cpp last week, removes this dead weight entirely, cutting KV cache memory by 47% and unlocking context lengths that were previously impossible on consumer hardware.
The KV Cache: Memory Killer in Sheep’s Clothing
The KV cache is the silent VRAM killer in transformer inference. For every token processed, you store Key and Value vectors for each attention head across all layers. The memory formula is brutal:
KV Cache [GB] = N × 2 × L × d/g × b_kv / 1024³
Where N is context length, L is layers, d is hidden dimension, g is the GQA grouping factor, and b_kv is bytes per scalar. For GLM-4.7-Flash with 47 layers and a hidden dimension of 5760, this adds up fast, 0.11 MiB per token in FP16.
The problem? GLM-4.7-Flash uses Multi-Latent Attention (MLA), a DeepSeek-style architecture that compresses both K and V into a single latent representation. The V tensor in the cache was literally just taking up space, 9GB of wasted VRAM at 45K context.
The Fix: V-Less Cache Implementation
The solution, introduced in PR #19067, adds native support for V-less KV caches. The changes are surgical but profound:
- Model detection:
llama_hparams::is_mla()now checks for MLA-specific parameters (n_embd_head_k_mlaandn_embd_head_v_mla) - Conditional allocation: When MLA is detected, the cache skips V tensor allocation entirely
- Graph optimization: New
llm_graph_input_attn_kclass handles K-only attention paths
The memory savings are immediate and dramatic. One user reported their KV cache dropping from 19.5GB to 10.3GB, a 47% reduction that fits nearly twice the context in the same VRAM footprint.
Before: llama_kv_cache: size = 19525.56 MiB, K (f16): 10337.06 MiB, V (f16): 9188.50 MiB
After: llama_kv_cache: size = 10337.06 MiB, K (f16): 10337.06 MiB, V (f16): 0.00 MiB
This isn’t just a GLM-4.7-Flash win. The same optimization applies to DeepSeek models and any future architecture that uses latent attention compression. The infrastructure is now in place for a new class of memory-efficient models.
Real-World Impact: From 45K to 90K Context
The community validation was swift. Within hours of the patch landing, users started reporting results:
- RTX 4090 (24GB): Context capacity doubled from ~45K to ~90K tokens with the same 4-bit quantization
- RTX 3090 (24GB): Similar scaling, with prompt processing speed improving by 1.48x at batch size 1
- Hybrid setups: The
--fitalgorithm automatically picks up the reduced memory requirements, enabling smarter GPU/CPU offloading
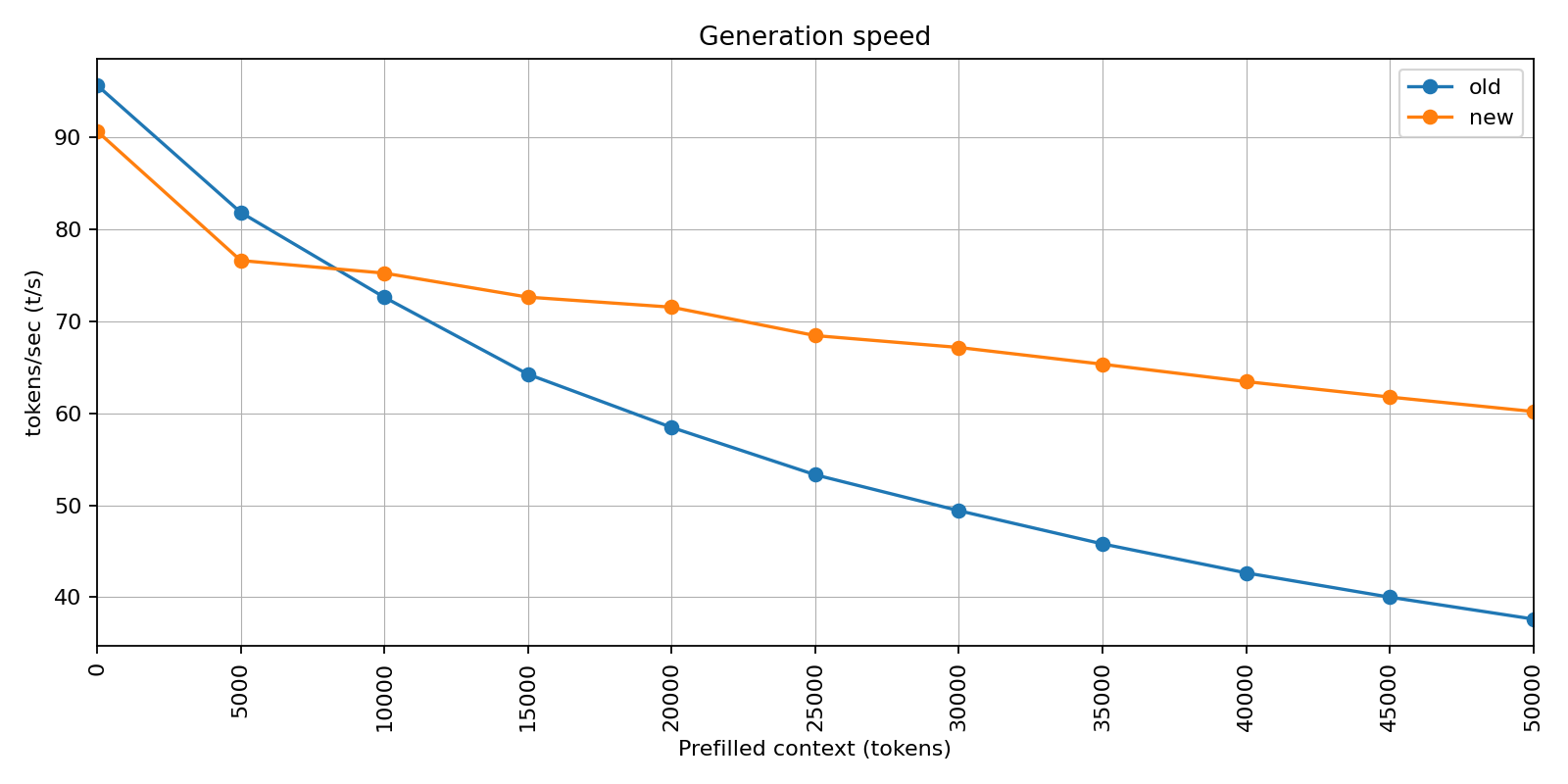
The performance gains extend beyond just memory savings. With less data to shuffle between GPU memory caches, prompt processing (prefill) speeds improved significantly. Benchmarks on RTX 3090 show 77.70 t/s vs 52.43 t/s at microbatch size 1, a 48% speedup that makes long-context RAG pipelines actually usable.
The CUDA Kernel Side Quest
The V-less cache was only half the battle. GLM-4.7-Flash’s GQA ratio of 20 (query heads to KV heads) didn’t play nice with existing FlashAttention kernels, which expected power-of-2 ratios. This forced a fallback to slower attention paths, creating a bizarre scenario where enabling Flash Attention actually hurt performance.
PR #19092 fixes this by padding Q columns to the next power of 2, wasting a bit of compute but unlocking the fast path. The result? Another 1.1-1.5x speedup depending on batch size, particularly on Ampere and newer GPUs.
The interaction between these two patches reveals something important: memory efficiency and compute efficiency are two sides of the same coin. The V-less cache reduces memory pressure, while the CUDA kernel fix ensures you’re not leaving compute on the table.
Why This Matters for Local AI
This optimization lands at a critical moment. As models push toward 1M+ token contexts, the KV cache has become the primary bottleneck for local inference. Cloud providers can throw HBM3 at the problem, consumer GPU owners can’t.
The GLM-4.7-Flash fix demonstrates that architectural innovations like MLA can slash memory requirements without sacrificing model quality. It’s a proof point for local-first AI architectures that don’t require data center-scale hardware.
For developers building RAG systems or agentic workflows, this changes the calculus. A 24GB GPU can now handle:
– Full codebases with 50K+ tokens of context
– Multi-document analysis without constant context window management
– Parallel agent execution where each instance gets meaningful context
The days of carefully trimming prompts to fit arbitrary token limits aren’t over, but they’re numbered.
The Controversy: Why Did This Take So Long?
Here’s where things get spicy. The fact that GLM-4.7-Flash wasn’t using its V tensor wasn’t a secret, it was obvious from the architecture diagram. Yet every major inference engine (vLLM, TensorRT-LLM, the original mlx-lm) was still allocating that memory.
Why? Because the KV cache abstraction is so deeply entrenched that questioning its basic assumptions became heretical. The “K” and “V” in KV cache are treated as immutable pairs, like thunder and lightning. Breaking that coupling required refactoring dozens of code paths and convincing maintainers that yes, sometimes half the cache is just dead weight.
This isn’t isolated. Kimi Delta Attention’s linear approach is attacking the same problem from a different angle, proving that the attention mechanism itself is ripe for disruption. Meanwhile, GLM-4.7-Flash’s CUDA issues show how hardware-specific optimizations can create invisible performance cliffs.
Practical Implementation
If you’re running GLM-4.7-Flash locally, here’s what you need to know:
No model re-download required. The fix is in llama.cpp’s handling, not the GGUF file. Just update to the latest commit:
# For llama.cpp users
git pull origin master
make clean && make LLAMA_CUBLAS=1
# For Ollama users
# Wait for the next release (likely 0.14.4) or build from source
Memory estimation is now simpler. The per-token cost drops from ~0.11 MiB to ~0.058 MiB. On a 24GB GPU with a 5GB model, you can estimate:
Available VRAM: 24GB - 5GB (model) - 1GB (overhead) = 18GB
Max tokens: 18GB / 0.058 MiB ≈ 310,000 tokens
In practice, you’ll hit other limits first, but 90K+ is now realistic.
Tool use improves dramatically. The model’s strong function-calling capabilities were previously hamstrung by context limits. With 90K tokens, you can feed it:
– Multiple API documentation pages
– Several repository trees
– Extended conversation history
– Complex system prompts
All without the constant token-budget anxiety.
The Bigger Picture: Beyond GLM-4.7-Flash
This optimization hints at a broader trend: model architectures are outpacing inference engines. MLA, Mamba, and other non-traditional architectures require rethinking assumptions baked into transformers since 2017.
The llama.cpp team’s willingness to merge breaking changes for MLA support sets a precedent. It signals that the “one size fits all” KV cache is dead, and future inference engines will need architecture-specific code paths.
For the community, this is a double-edged sword. On one hand, it unlocks incredible efficiency gains. On the other, it fragments the ecosystem, optimizations for GLM-4.7-Flash won’t help your Llama 3 inference, and vice versa.
The winners will be developers who understand these tradeoffs and pick models that match their hardware constraints. Running GLM-4.7 efficiently on consumer AMD GPUs or building local-first RAG pipelines requires matching architectural innovations to hardware capabilities.
Conclusion: The Free Lunch Was Just Served
The GLM-4.7-Flash KV cache optimization is a rare true free lunch in computer science: a change that reduces memory usage, improves speed, and requires no model retraining. By simply not storing data the model never uses, we’ve unlocked nearly double the context capacity on existing hardware.
For consumers, this means longer documents, more complex agents, and better local AI tools. For researchers, it’s a reminder to question fundamental assumptions. And for the cloud AI industry, it’s another warning shot: the gap between local and hosted inference just got smaller.
The patch is live. Update your llama.cpp. Feed your GPU the context it deserves.
Next Steps:
– Try GLM-4.7-Flash with the new optimizations and report your context capacity gains
– Explore how this changes your RAG pipeline design
– Consider whether MLA-style architectures fit your use case better than traditional GQA
The future of local AI isn’t just smaller models, it’s smarter memory usage.