The Fork That Finally Forked Back: llama.cpp Adopts ik_llama’s Secret Quantization Sauce
The quantization wars just got a new chapter, and it’s written in the language of pull requests and performance benchmarks. While the AI community obsesses over parameter counts and context windows, a more important battle has been raging in the trenches of model compression. Now, a single pull request in llama.cpp threatens to reshape the landscape for anyone running large language models on consumer hardware, and it’s dragging some messy open-source politics along for the ride.
The Quantization Gap No One Talks About
Let’s be blunt: if you’re running 30B+ parameter models on a 24GB GPU, you’ve felt the pain. The difference between fitting a model and watching it crash with an out-of-memory error often comes down to a few hundred megabytes of VRAM. That’s where quantization strategies become less of a nice-to-have and more of a survival mechanism.
The Numbers Don’t Lie (But They Do Get Fishy)
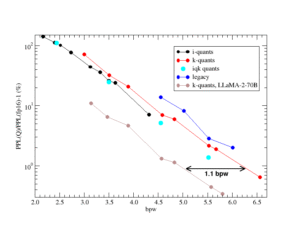
The pull request author, AesSedai, ran extensive perplexity and KL divergence testing on Qwen3-4B-Instruct-2507 to validate the port. The results reveal both the promise and the pitfalls of cross-fork quantization compatibility.
When using ik_llama.cpp’s quantized models with llama.cpp’s inference engine, the results are promising:
| Quant Type | Size | BPW | PPL(Q)/PPL(base) | Mean KLD | Same Top P |
|---|---|---|---|---|---|
| IQ2_K | 1.28 GiB | 2.73 | 0.999823 ± 0.005020 | 0.012506 ± 0.000749 | 93.41% |
| IQ3_K | 1.67 GiB | 3.57 | 0.994594 ± 0.003895 | 0.005542 ± 0.000260 | 96.08% |
| IQ4_K | 2.21 GiB | 4.72 | 1.004556 ± 0.003485 | 0.004944 ± 0.000198 | 96.16% |
| IQ5_K | 2.62 GiB | 5.60 | 0.991185 ± 0.003721 | 0.004930 ± 0.000239 | 94.90% |
| IQ6_K | 3.1 GiB | 6.63 | 1.001598 ± 0.003613 | 0.005122 ± 0.000366 | 94.98% |
But here’s where it gets interesting. When llama.cpp performs the quantization itself, things look… different:
| Quant Type | Size | BPW | PPL(Q)/PPL(base) | Mean KLD | Same Top P |
|---|---|---|---|---|---|
| IQ2_K | 1.3 GiB | 2.78 | 1.485431 ± 0.045757 | 0.435849 ± 0.012438 | 62.90% |
| IQ3_K | 1.75 GiB | 3.74 | 0.965421 ± 0.010749 | 0.049772 ± 0.002152 | 87.92% |
That IQ2_K result isn’t a typo, it’s a red flag. The KLD jumps from 0.012 to 0.435, and top-P agreement collapses from 93% to 63%. After debugging, AesSedai traced this to incorrect tensor type selection in llama_tensor_get_type. Once fixed, the numbers normalized, but the incident highlights how fragile quantization compatibility can be when crossing codebase boundaries.
The Drama Behind the Code
Now for the spicy part. This PR didn’t just introduce better quantization, it reignited a smoldering conflict between llama.cpp maintainer Georgi Gerganov and ik_llama.cpp creator Iwan Kawrakow. When collaborator JohannesGaessler stated he “cannot review, let alone merge any code written by Iwan Kawrakow unless and until the conflict between him and Georgi Gerganov has been resolved”, the thread exploded.
The urban legend that apparently needed addressing? That Kawrakow would sue llama.cpp developers for copying his code. He responded directly: “I’m not going to sue llama.cpp contributors (or anyone else). I have better things to do.” Instead, his grievance is about attribution, code and ideas lifted without acknowledgment.
The real tension lies in maintenance burden. Georgi Gerganov’s legitimate concern is sustainability, absorbing a fundamentally different quantization codebase adds ongoing complexity. Whether that cost justifies the quality gain is a reasonable debate, but one that should happen on technical merits, not interpersonal history.
What This Means for Edge AI Practitioners
If you’re running models on anything other than a data-center GPU, this matters. The performance optimization in local LLM runtimes like llama.cpp has already created a 70% throughput gap over alternatives like Ollama. Adding IQ*_K quantization potentially widens that chasm further.
The Ecosystem Ripple Effect
This PR doesn’t exist in isolation. It arrives alongside integration of cutting-edge models into llama.cpp for local execution, making Qwen3 and similar models more accessible to developers without enterprise budgets. The llama.cpp’s API flexibility enabling local execution of cloud-based models means you can now run Claude Code against local IQ-quantized models, severing cloud dependencies entirely.
The Road Ahead: CPU Backend and Beyond
AesSedai was upfront about limitations: “Since this implementation is for the CPU backend only currently, do not expect excellent performance.” The real magic happens when CUDA, Vulkan, and Metal backends get IQ*_K support. The community is already salivating over AVX-based implementations that promise “substantial perf gains.”
Final Thoughts: Open Source Realpolitik
This PR represents more than technical advancement, it’s a case study in open-source governance under pressure. The community wants these quants. The maintainer is concerned about sustainability. The original author wants proper attribution. And everyone is navigating MIT license freedoms and responsibilities.
The most telling comment came from RoughOccasion9636: “The users who would benefit do not care about the history, they just want better quants in mainline.” That sentiment captures the tension between project politics and practical needs. But it also oversimplifies the challenge: without sustainable maintenance, those benefits evaporate when bugs arise or architectures evolve.
What’s clear is that llama.cpp continues to evolve as the substrate for local AI inference. Whether through breaking cloud API dependencies through local inference with llama.cpp or compression advances like IQ*_K, the project is systematically removing barriers to running sophisticated models on commodity hardware.
The quantization gap between ik_llama.cpp and mainline llama.cpp might finally close. The real question is whether the social and technical debt incurred along the way proves worth the performance gains. For developers watching their VRAM meters hover at 23.8GB while trying to load a 34B model, the answer is probably yes.
Bottom line: If you’re running local LLMs on constrained hardware, start testing IQ*_K quants now. The performance per bit improvement is real, the compatibility is maturing, and the ecosystem momentum is undeniable. Just keep an eye on those tensor type selections, your perplexity scores will thank you.