
The 3D Visualizer That Exposes How Little We Understand About Our Local AI Models
A developer’s weekend project just laid bare a fundamental tension in the AI community. While the open-source movement has made running powerful language models on consumer hardware almost trivial, our ability to actually see what these models are doing inside remains practically non-existent. The rough GGUF visualizer that surfaced on Reddit last week isn’t just a cool tool, it’s a mirror reflecting how unprepared we are for the transparency demands of democratized AI.
The Reddit Post That Started a Reckoning
The post was disarmingly humble. A developer shared a hacked-together tool that lets you upload any GGUF file and visualize its internals in a 3D representation of layers, neurons, and connections. The goal was simple: stop treating models as black boxes and start seeing what’s actually inside. The admission that “someone who actually knows what they’re doing could’ve built something way better” sparked a conversation that quickly revealed a deeper problem.
The community’s response was telling. Comments immediately pointed to existing solutions like bbycroft.net/llm, an impressive visualization tool that works beautifully, except you can’t upload new models. It’s locked to a handful of pre-loaded options. This limitation isn’t a design choice, it’s a technical barrier that highlights how difficult it is to create truly universal interpretability tools for quantized models.
Why Quantization Breaks Interpretability
The move to GGUF (GPT-Generated Unified Format) has been revolutionary for local AI deployment. These quantized models strip away precision to reduce size, making it feasible to run 70B parameter models on hardware that costs less than a month’s worth of cloud API calls. But this democratization comes at a hidden cost: quantization fundamentally obscures the model’s internal mechanics.
Traditional interpretability research focuses on full-precision models where activations and weights maintain their original relationships. Mechanistic interpretability, the field that treats neural networks like biological organisms to dissect, relies on precise measurements of how information flows through the residual stream, how attention heads activate, and how features are represented in specific directions of the latent space.
Quantization disrupts these delicate relationships. When you compress a model from 16-bit to 4-bit precision, you’re not just making it smaller, you’re fundamentally altering the geometry of its representational space. The features that sparse autoencoders painstakingly extract from full-precision models may not survive the quantization process intact. As research from Towards Data Science demonstrates, the residual stream in transformers contains rich semantic structure that can be manipulated to steer model behavior. But in a quantized model, that structure becomes a coarse approximation.
The Visualization Gap: What Exists vs. What We Need
The current landscape of model visualization tools reveals a stark divide between research-grade solutions and practical accessibility. On one end, you have sophisticated tools like Neuronpedia, which offers deep insights into model internals but requires significant expertise to use effectively. Despite common misconception, Neuronpedia isn’t an Anthropic product, it’s the brainchild of Johnny Lin, though Anthropic has contributed to its development. The tool’s power lies in its ability to visualize sparse autoencoder features, but it works best with models that have been specifically instrumented for analysis.
On the other end, you have educational tools like the Transformer Explainer from the Polo Club, which provides beautiful interactive visualizations but is similarly limited to demonstration models. These tools serve as proof-of-concept but don’t address the fundamental need: inspecting the actual models running on our local machines.
The Reddit developer’s GGUF visualizer sits in this gap. It’s not polished, but it’s trying to solve the right problem. The fact that it can load arbitrary GGUF files makes it immediately more practical for the local AI community than locked-down research tools. Yet the developer’s own admission of its roughness underscores how difficult this problem is.
The Technical Challenge of Real-Time Model Inspection
What makes building a universal model visualizer so hard? The answer lies in the architecture of modern inference engines. When you load a GGUF model into llama.cpp or similar frameworks, the weights are loaded into GPU memory in a format optimized for fast matrix operations, not for introspection. The computational graph is compiled on-the-fly, and intermediate activations are transient by design.
To build a truly effective visualizer, you need to:
- Hook into the inference loop: Capture activations at each layer without destroying performance
- Map quantized representations back to semantic space: Understand how 4-bit weights correspond to the features researchers have identified in full-precision models
- Handle the diversity of architectures: From standard transformers to MoE models to the latest hybrid approaches
- Present the data meaningfully: Raw activation heatmaps are overwhelming, effective visualization requires intelligent aggregation
The recent research on data-centric interpretability for multi-agent RL systems illustrates this challenge perfectly. Researchers analyzing Diplomacy-playing LLMs had to extract features from the residual stream using sparse autoencoders, then develop a “Meta-Autointerp” method to group thousands of individual features into coherent behavioral hypotheses. Their framework achieved 90% significance rates in validating discovered features, but only after processing over 6,400 trajectories and applying sophisticated statistical analysis.
Scaling this down to a tool that runs on a laptop and provides insights in real-time is orders of magnitude more difficult.
The Democratization Paradox
Here’s where the controversy gets spicy. The AI community has celebrated GGUF and similar formats as democratization triumphs. Suddenly, anyone with a decent GPU can run models that previously required enterprise infrastructure. But this democratization is superficial if we can’t understand what these models are doing.
The MIT Technology Review’s “alien autopsy” piece captures this tension perfectly. Researchers are treating LLMs like biological specimens, probing them with mechanistic interpretability tools to understand their internal workings. But these techniques require access to model internals that quantized formats obscure.
We’re in a situation where we’ve democratized usage while concentrating understanding among a few research labs with the resources to analyze full-precision models. The GGUF visualizer attempts to bridge this gap, but it’s fighting against fundamental technical constraints.
What the Visualizer Reveals (And What It Doesn’t)
The developer’s tool provides a 3D view of model architecture, layers as stacked planes, neurons as nodes, connections as edges. It’s visually impressive and gives users a sense of scale. You can see the 32 or 40 layers of a typical LLM, the width of the hidden dimensions, and the clustering of attention heads.
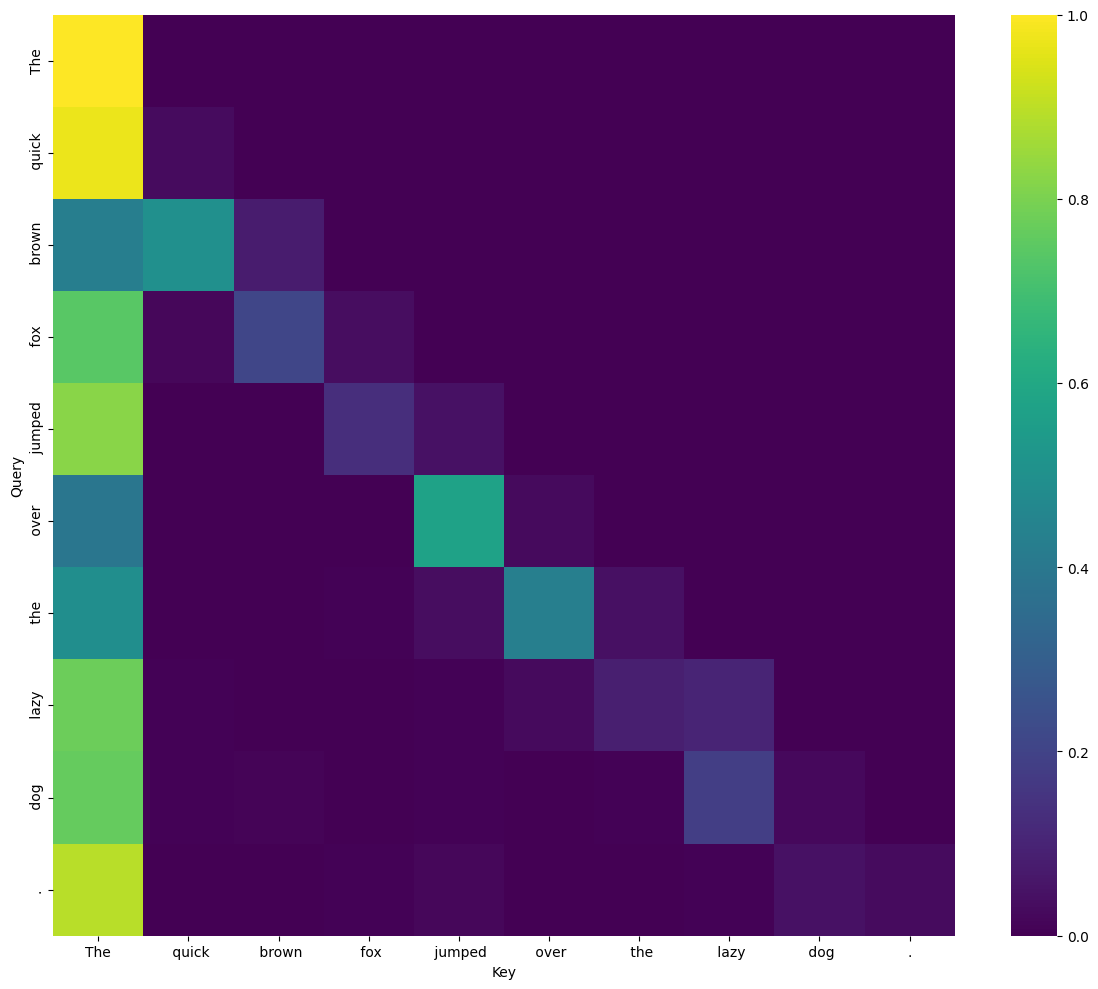
But this architectural view is just the skeleton. The real insights come from seeing how activations flow through this structure in response to specific inputs. The attention map image included in the research shows what this looks like for a single attention head in GPT-2 small. The patterns are interpretable: you can see which tokens attend to which other tokens, revealing the model’s syntactic and semantic processing.
For a quantized GGUF model, these activation patterns are what we need to see. Does the quantized version preserve the same attention patterns as the original? Do the same neurons activate for the same concepts? Are the “circuit” pathways identified in research papers still intact?
The current visualizer doesn’t answer these questions. It’s a starting point, not a solution. But it’s the right starting point.
The Quantization Trade-Off Nobody Talks About
The AI community has accepted quantization as a necessary optimization without fully grappling with its implications for model reliability and safety. When we quantize a model, we’re essentially performing brain surgery without a brain scan. We know the model still works, it produces coherent text, but we don’t know how it’s working.
This matters because quantization can introduce subtle failures. A model might lose the ability to perform certain types of reasoning, or it might develop new failure modes that aren’t apparent in standard benchmarks. The research on mechanistic interpretability shows that models develop sophisticated internal representations for concepts like space, time, and game states. Quantization could corrupt these representations in ways that only show up in edge cases.
The GGUF visualizer, if extended to show activation patterns, could help identify these issues. By comparing visualizations of full-precision and quantized versions of the same model, developers could see exactly what quantization changes. This would be invaluable for 2-bit quantization breakthroughs where the compression is so aggressive that we need to verify what survives.
The Path Forward: What We Actually Need
The Reddit discussion and subsequent community responses point to a clear need: an open-source, universal model inspection tool that works with quantized formats. This tool would need to:
- Integrate with existing inference engines: Rather than reinventing the wheel, it should hook into llama.cpp, vLLM, and other popular frameworks
- Provide multiple views: Architectural overview, activation heatmaps, attention patterns, and feature visualizations
- Support comparative analysis: Side-by-side comparison of different quantization levels, or of original vs. fine-tuned models
- Export insights: Generate reports that help developers understand model behavior and potential issues
The NVIDIA-Unsloth partnership shows that the industry is serious about making AI accessible. But accessibility without transparency is a recipe for trouble. As more developers fine-tune quantized models, the risk of unintended behavior increases. A visualizer that helps identify these issues before deployment would be invaluable.
The Performance Challenge
One reason we lack good visualization tools is performance. Capturing and displaying activations in real-time adds overhead. For a model generating tokens at 100+ tokens per second, even a 10% slowdown is noticeable.
But this is where the Soprano TTS breakthrough offers inspiration. If we can achieve 15ms end-to-end latency for speech synthesis, we can certainly build efficient model inspection tools. The key is selective activation capture and intelligent sampling rather than trying to visualize everything at once.
The multi-agent RL research demonstrates this principle. Instead of analyzing every activation, they used sparse autoencoders to identify the most informative features, then focused their analysis on those. A practical GGUF visualizer could use similar techniques to show users the most relevant activations for their inputs.
The Hardware Reality Check
All of this assumes we have the hardware to run these models and inspect them simultaneously. The eBay GPU scavenger hunt phenomenon shows that local AI enthusiasts are creative about hardware, but there’s a limit. Running a 70B model already pushes most consumer GPUs to their limits. Adding visualization overhead could make it impractical.
This suggests we need a two-tier approach: lightweight visualization for real-time use, and heavy-duty analysis that can be run offline on a subset of inputs. The real-time view might show high-level patterns and anomalies, while the offline analysis could generate detailed reports.
The Community Imperative
The most important aspect of the GGUF visualizer project is that it’s community-driven. Unlike corporate tools that are tied to specific platforms or models, an open-source visualizer can adapt to the community’s needs. The Reddit discussion already surfaced valuable feedback about what users want: the ability to upload any model, integration with existing tools, and both architectural and activation-level views.
This community-driven development model is essential for democratizing AI transparency. The major labs have incentives to keep their interpretability tools proprietary, using them as competitive advantages for safety marketing. A grassroots tool can be truly neutral, supporting any model and any use case.
The developer’s decision to share the code on GitHub and ask for feedback demonstrates the right approach. The community’s response, pointing to related tools and research, shows there’s appetite for collaboration. What we need now is sustained effort to turn this rough prototype into a robust tool.
Conclusion: Transparency as a Prerequisite, Not an Afterthought
The GGUF visualizer controversy highlights a fundamental shift in how we need to think about AI democratization. Making models runnable on consumer hardware was the first step. Making them understandable is the necessary next step.
Without transparency tools, we’re building a future where everyone can run AI models but only a few can truly understand them. This creates a dangerous asymmetry. Users can encounter model failures, biases, or unsafe behaviors without any ability to diagnose or mitigate them.
The rough visualizer that sparked this conversation won’t solve the problem on its own. But it asks the right question: if we’re going to democratize AI, shouldn’t we democratize understanding too?
The answer is yes. And the time to build these tools is now, before the gap between capability and comprehension widens further. The community has shown it can create useful tools. Now it needs to create essential ones.
The models are already on our laptops. It’s time to open them up and see what’s really inside.



