The performance gap isn’t subtle. When running Qwen-3 Coder 32B in FP16 on identical hardware, an RTX 5090 paired with an RTX 3090 Ti, llama.cpp churns out 52 tokens per second while Ollama manages just 30. That’s not a rounding error, it’s a 70% throughput chasm that has the local AI community asking hard questions about abstraction layers and the price of convenience.
But raw numbers only tell half the story. The real controversy lies in why this gap exists, what it means for developers, and whether Ollama’s user-friendly wrapper deserves its dominant market position when it’s fundamentally hobbling the engine underneath.
The 70% Tax: Where Your Tokens Go
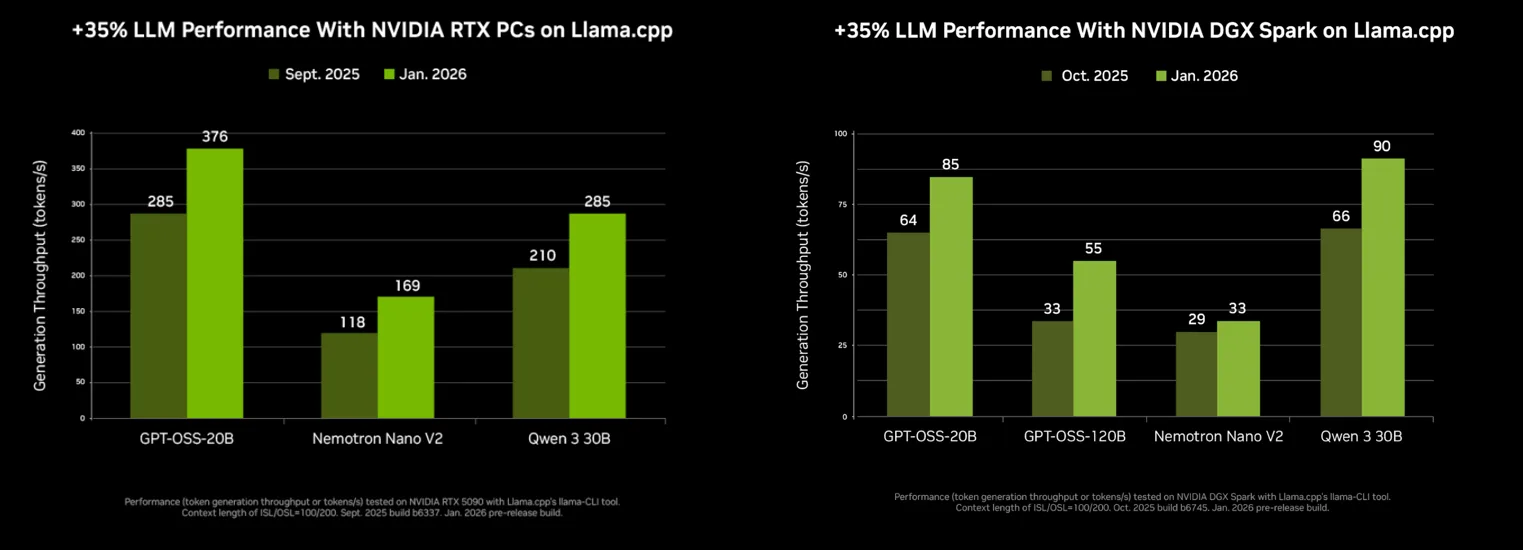
The benchmark that sparked this debate is straightforward: same model weights, same hardware, same task. Yet the results diverge dramatically. NVIDIA’s own telemetry confirms the trend, over the past four months, llama.cpp’s token generation throughput on MoE models increased by 35%, while Ollama’s improvements reached 30%. Even as both frameworks optimize, the gap persists.
The culprit isn’t a single bottleneck but a cascade of design decisions. According to technical analysis from the community, Ollama’s tensor allocation heuristics are fundamentally flawed. While both runtimes leverage the same GGML backend, Ollama’s “bad and hacked-on” logic for assigning GPU layers, especially problematic for MoE models and multi-GPU setups, ends up parking critical tensors in system RAM when they should reside in VRAM. This forces constant data shuffling across the PCIe bus, turning what should be a memory-bound operation into a bandwidth nightmare.
llama.cpp, by contrast, implements MoE-aware automation that intelligently distributes tensors across available GPUs. The difference is particularly stark on heterogeneous setups like the RTX 5090 + 3090 Ti combination, where proper tensor split can mean the difference between saturating both cards and leaving one idle.
The Wrapper Problem: Convenience at What Cost?
Ollama’s architecture is essentially a management layer atop llama.cpp (or more precisely, llama-cpp-python). This abstraction delivers tangible benefits: one-click model pulls, seamless model switching, a RESTful API that “just works”, and broad integration support across tools like Continue.dev and LM Studio. For developers who value “set and forget” deployments, this is worth its weight in gold.
The community sentiment reflects this divide. Some developers view Ollama as a “toy for technically ignorant users” that adds nothing but latency. Others argue this perspective misses the point entirely, most practitioners just want a solution that works without wrestling with build environments, CUDA versions, or manual GGUF management. As one developer put it, the difference between downloading a precompiled binary and running ollama serve is the difference between 99% adoption and 1%.
But the performance penalty is steep. When you’re burning 40% more GPU time for the same output, the calculus changes. For batch processing pipelines, autonomous agents making rapid API calls, or any scenario where throughput directly translates to user experience, that 70% tax becomes a dealbreaker.
The Technical Nitty-Gritty: What Actually Changed
Recent commits reveal why llama.cpp keeps pulling ahead. The January 2026 builds introduced several key optimizations:
- GPU token sampling (PR #17004): Offloads TopK, TopP, temperature, and other sampling algorithms to the GPU, reducing CPU-GPU synchronization overhead
- Concurrency for QKV projections (PR #16991): Enables concurrent CUDA streams with the
--CUDA_GRAPH_OPT=1flag, parallelizing attention computations - MMVQ kernel optimizations (PR #16847): Pre-loads data into registers and hides latency through better GPU utilization
- 65% faster model loading on DGX Spark systems, with 15% improvements on consumer RTX cards
Ollama’s recent updates, Flash Attention by default, improved memory management schemes, and LogProbs API support, are substantive. But they’re playing catch-up, and the wrapper architecture inherently adds latency. Every API call, every model switch, every tensor allocation decision that passes through Ollama’s heuristic layer introduces microseconds that compound into the 70% gap.
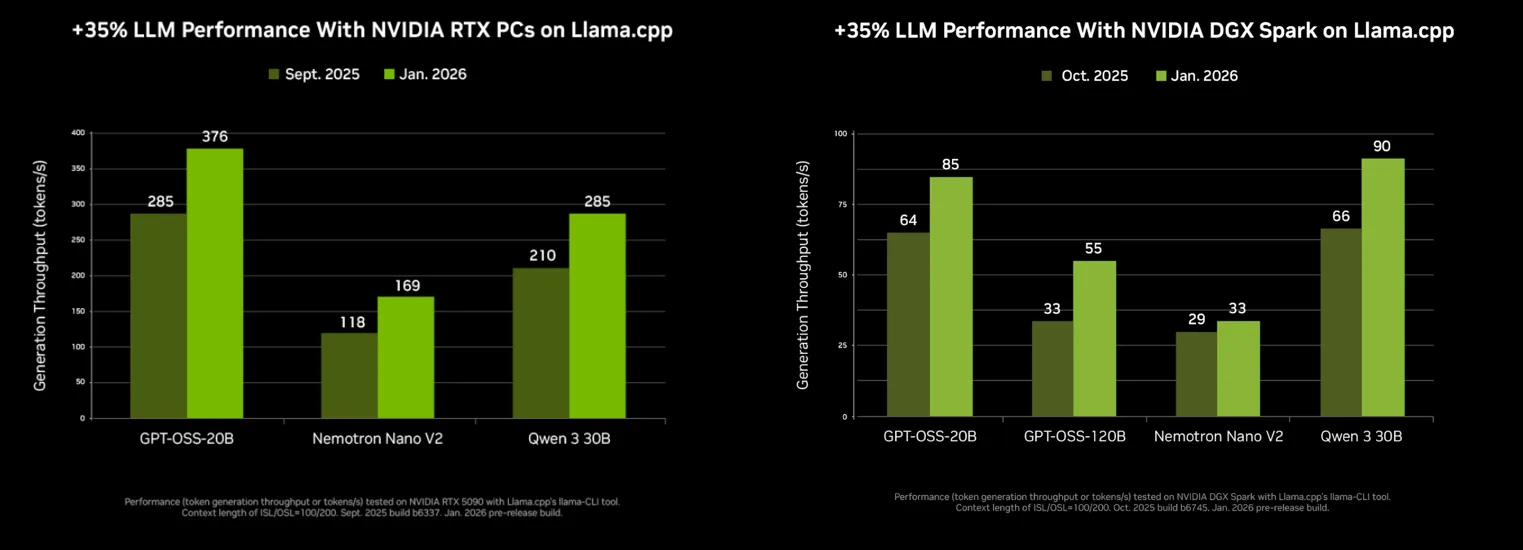
When the Gap Matters (And When It Doesn’t)
The controversy intensifies when you consider real-world usage patterns. For casual chatbot interactions, the difference between 30 and 52 tokens per second is barely perceptible. But for code generation, where the benchmark was run, the impact is concrete. A 70% faster generation means less waiting between autocomplete suggestions, faster test generation, and more fluid pair-programming experiences with your AI assistant.
The divide becomes critical in production scenarios. Autonomous agents making hundreds of sequential calls, RAG pipelines processing document chunks in parallel, or any application where latency compounds across multiple inference steps will feel that 70% penalty acutely. Conversely, for single-turn queries or applications where model loading time dominates, Ollama’s faster startup might offset its runtime disadvantage.
Multi-GPU setups also flip the script. Several developers report that on certain Intel GPU configurations, Ollama’s heuristics actually outperform llama.cpp’s defaults. This isn’t the common case, NVIDIA dominates the local AI space, but it reveals how hardware-specific the optimization game has become.
The Path Forward: Can Ollama Close the Gap?
The core tension isn’t going away. Ollama’s value proposition, simplicity and integration, directly conflicts with the performance purity that llama.cpp prioritizes. Recent improvements show both projects are accelerating, but the fundamental architecture difference remains.
One potential resolution is for Ollama to expose more low-level controls. Power users could bypass the problematic heuristics with manual GPU layer settings, tensor split configurations, and kernel selection flags. This would preserve the “it just works” experience for newcomers while letting performance-conscious developers tune around the overhead.
Another path is deeper integration of llama.cpp’s latest optimizations. Ollama’s recent adoption of Flash Attention and upstream GGML changes shows this is happening, but the pace matters. Every month the gap persists, more developers migrate to raw llama.cpp, fragmenting the ecosystem and reducing Ollama’s network effects.
The Bottom Line
The 70% performance divide isn’t a temporary artifact, it’s a structural consequence of abstraction. Ollama made a deliberate tradeoff: user experience over raw speed. For many, that tradeoff remains worthwhile. But as local LLMs move from toys to production tools, the market is splitting. One camp prioritizes developer velocity and integration, the other demands maximum performance and control.
The uncomfortable truth is that both sides are right. Ollama’s convenience has democratized local AI, bringing powerful models to developers who’d never compile from source. Yet llama.cpp’s performance gains are too substantial to ignore for serious applications. The question isn’t which is better, but which is better for your specific use case, and whether that 70% tax is a price you’re willing to keep paying.
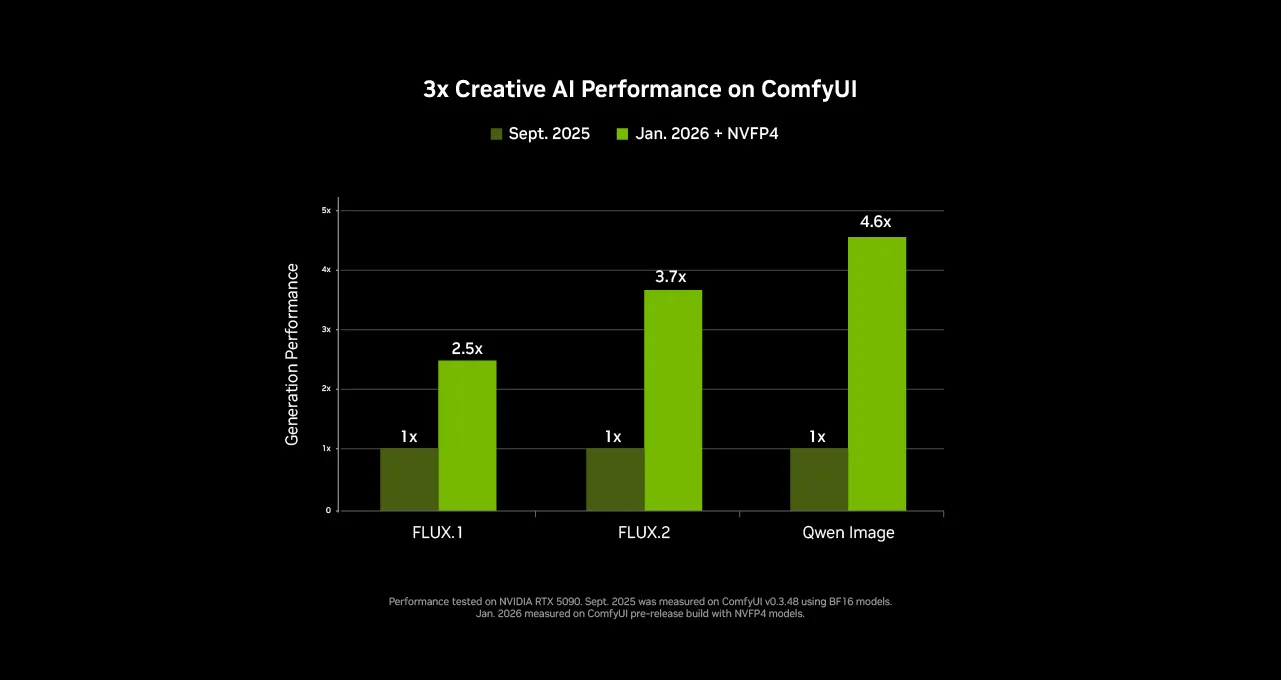
The benchmarks don’t lie. Neither do the developer experience metrics. The real controversy isn’t the performance gap itself, it’s that the AI community still hasn’t decided which matters more.