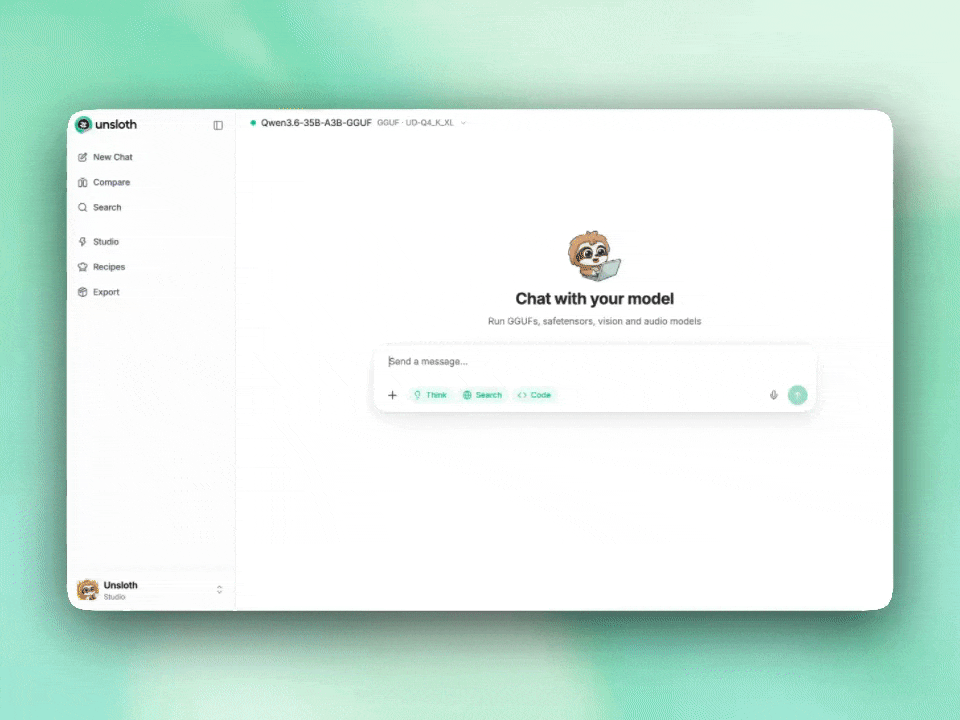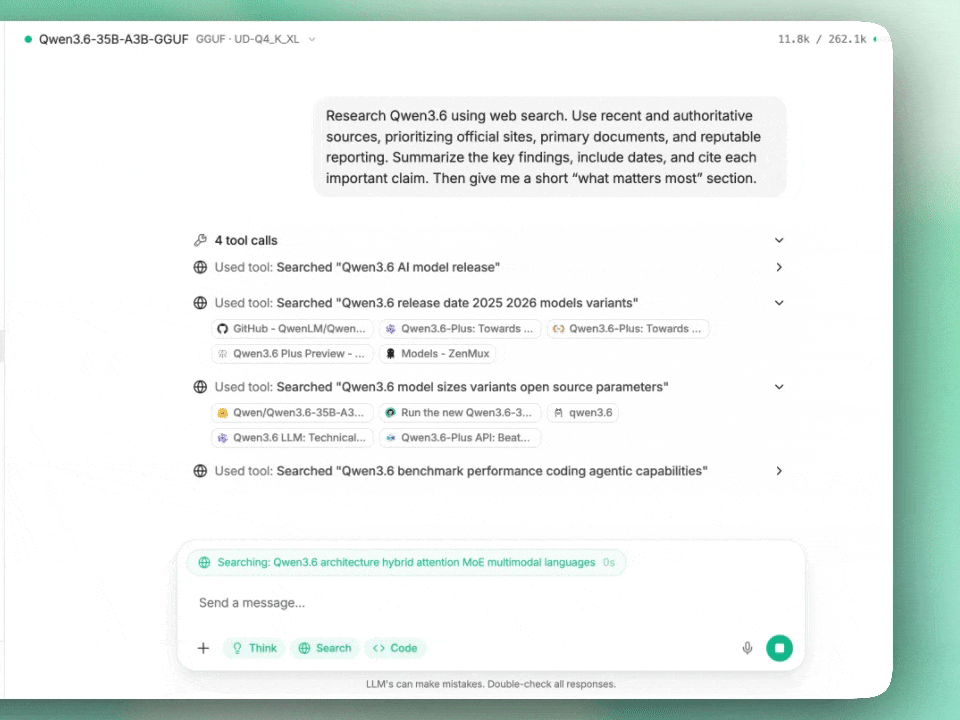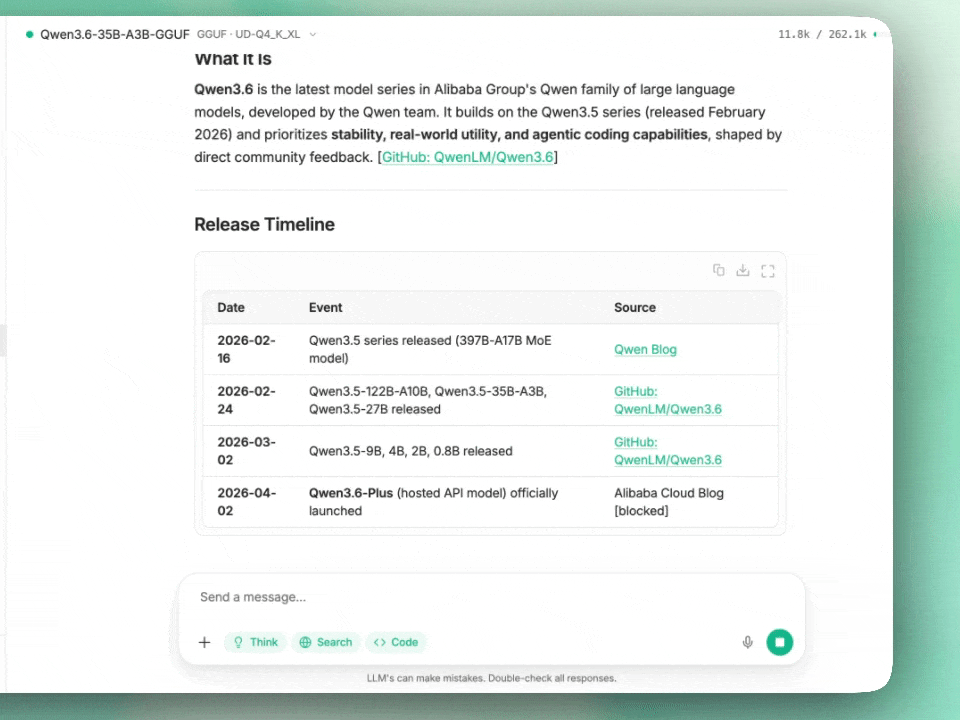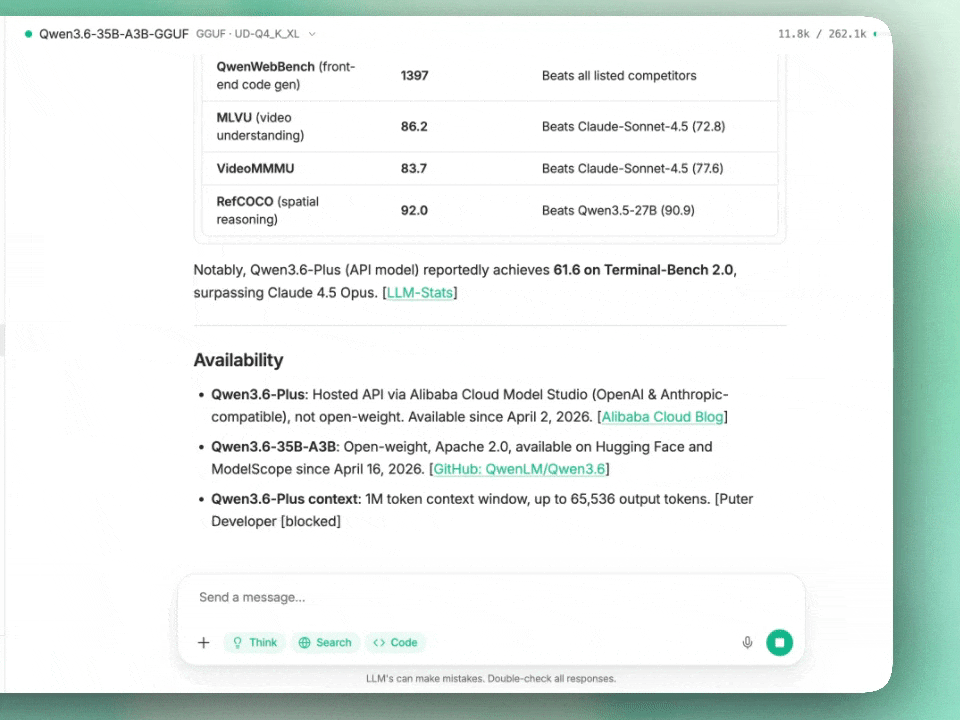
25 articles found
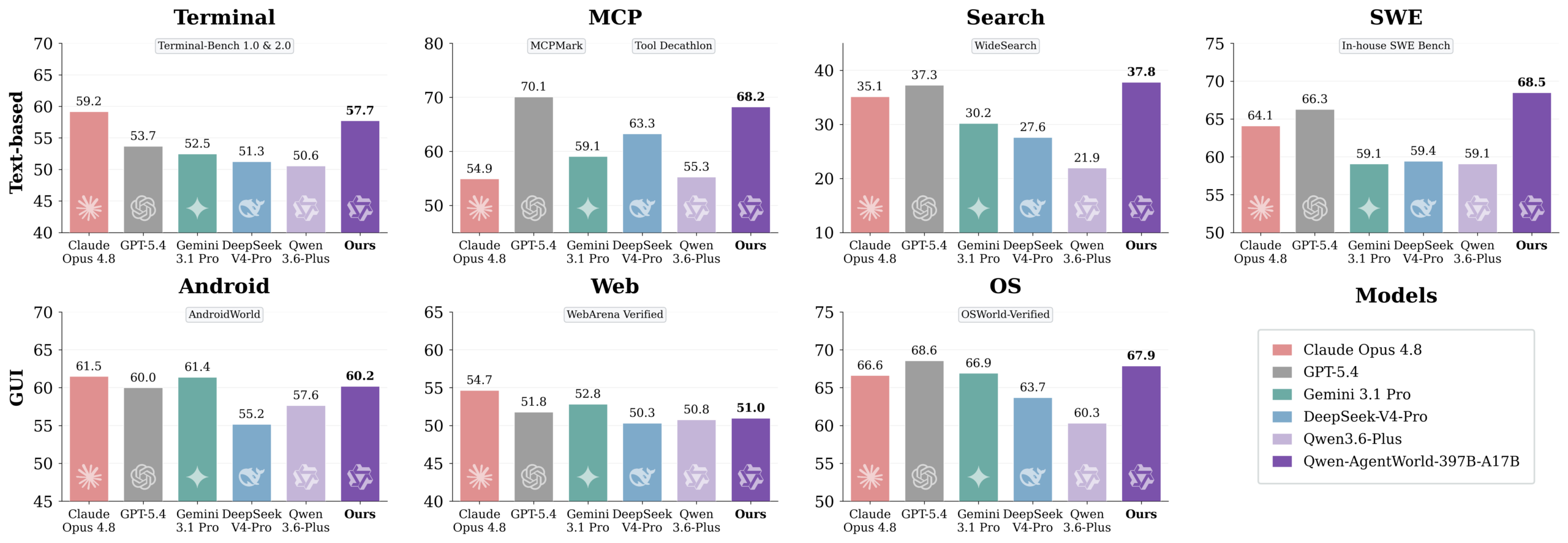
Alibaba’s new 35B MoE model (3B active) can simulate seven different agent environments, MCP, terminal, web, Android, and more, without running the real tools.
Nvidia dropped Nemotron-3 Ultra, a 550B MoE model that runs on just 8 H100s. It’s fast, efficient, and surprisingly practical, but the benchmarks tell a nuanced story.
Cohere’s Command A+ brings sparse mixture-of-experts to mere mortals with aggressive quantization, Apache 2.0 licensing, and hardware requirements starting at two H100 GPUs.
NVIDIA packs 30B, 23B, and 12B reasoning models into one checkpoint, achieving 360x training cost reduction and dynamic speed scaling.
Analysis of Qwen3.6-27B vs Coder-Next shows statistical ties despite massive parameter differences. The era of bigger-is-better has ended.
Alibaba’s Qwen3.6-35B-A3B activates only 3B parameters per token yet claims agentic coding parity with models 10x its size. We dissect the architecture, benchmarks, and whether this Apache 2.0 release actually changes the local AI equation.
Why Nvidia’s hybrid Mamba-MoE architecture is less about benchmark glory and more about owning the inference stack from cloud to workstation.
Technical deep dive into unlocking 2x inference speed on RTX PRO 6000 Blackwell GPUs by fixing CUTLASS SMEM overflow bugs for MoE models
Qwen 3.5’s sub-10B models are outperforming last generation’s giants, and with Unsloth’s Dynamic 2.0 quantization, they’re running on your phone at 60 tokens per second. The ‘GPU poor’ just got their revenge.
Liquid AI’s new sparse MoE model activates only 2.3B parameters per token, delivering server-class AI performance on consumer hardware while challenging the cloud-only paradigm.
MiniMax-2.5 achieves 80.2% on SWE-Bench Verified with 200K context, runs locally at 3-bit precision, and costs $1/hour, forcing a reckoning for proprietary AI pricing.
MiniMax’s 230B MoE model hits 80.2% on SWE-Bench at 1/20th the cost of competitors. Here’s why the AI pricing model just collapsed.
Unsloth’s custom Triton kernels deliver 12x faster MoE training with 35% less VRAM, enabling Qwen3 and DeepSeek fine-tuning on consumer GPUs. But the real story is what this means for AI democratization and hardware vendor lock-in.
Intern-S1-Pro’s 1T MoE architecture delivers SOTA scientific reasoning while activating only 22B parameters, challenging closed-source models and redefining specialized AI for chemistry, materials, and life sciences.
Stepfun’s sparse MoE model activates only 11B parameters yet outperforms models 3-5x larger on coding and agentic tasks, delivering 100-300 tok/s on consumer hardware and forcing a reckoning with the parameter count arms race.
OpenMOSS’s MOVA delivers synchronized video-audio generation with 18B active parameters, challenging closed models with fully open weights and day-0 SGLang support.
Transformers v5’s 6x-11x performance gains for Mixture-of-Experts models reveal more about v4’s limitations than v5’s innovations. The API simplification and dynamic weight loading rewrite the rules for LLM inference.
Z.ai’s new 30B MoE model promises transparent step-by-step reasoning, but its meticulous thought process reveals a deeper tension in local AI deployment: when interpretability becomes a performance bottleneck.
GLM-4.7-Flash is delivering reliable agentic performance on consumer hardware, but the path to getting it running reveals the messy reality of local AI deployment.
A 30-billion-parameter model is beating Llama 3.3 70B on reasoning tasks while using a fraction of the compute. Here’s how NVIDIA’s hybrid architecture changes the local AI game.
An in-depth look at how Xiaomi’s modestly-sized MoE model delivers elite performance at a fraction of the cost, and why the community isn’t buying it.
NVIDIA’s new open-weight Nemotron-3-Nano promises 1M token context and best-in-class reasoning performance, but early deployments reveal a more complicated reality. Here’s what the benchmarks don’t tell you.
LLaDA2.0’s MoE-powered diffusion architecture challenges everything we know about local AI deployment
REAP pruning outperforms merging in MoE models, enabling near-lossless compression of 480B giants to local hardware
Alibaba’s hybrid MoE architecture delivers 80B parameter performance with 3B activation costs, revolutionizing local task automation