
Xiaomi just threw a deep-ball pass into the crowded field of massive language models. The company, better known for smartphones and electric kettles, has dropped a 309-billion parameter beast called MiMo-V2-Flash that claims performance rivaling Claude Sonnet 4.5 and GPT-5 High. The twist? It does this while activating only 15 billion parameters per inference, making it monumentally cheaper and faster to run. It’s either a genuine architectural breakthrough or the most convincing benchmark hack of the year. Let’s dissect the claims, the code, and the community’s skeptical glare.
The Marketing Claims vs. The Algorithmic Reality
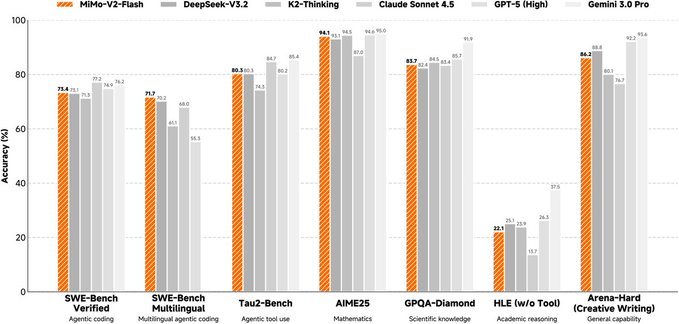
The headline specs are engineered for maximum intrigue: 309B total parameters, 15B active (a classic Mixture-of-Experts approach), a blazing 150 tokens/second inference speed, and a 256k context window. Xiaomi’s official benchmark table paints a picture of a model that punches far above its weight class.
It scores a 73.4% on SWE-Bench Verified, allegedly topping all open-source competitors and nipping at the heels of Claude Sonnet 4.5 (77.2%). On AIME 2025 (a rigorous math benchmark), it posts a 94.1%, essentially tied with GPT-5 High’s 94.6% and ahead of DeepSeek-V3.2’s 93.1%. The API pricing is audacious: $0.1/million input tokens, $0.3/million output tokens. That’s roughly 2.5% of Claude Sonnet’s cost.
Beyond the Headlines: The Mechanics of Efficiency
So how does a model with a fraction of the active compute compete with giants? It’s not magic, it’s a collection of deliberate, aggressive architectural trade-offs.
First, there’s the Hybrid Sliding Window Attention (SWA). Instead of full attention on a massive context, MiMo-V2-Flash uses a strict 5:1 ratio of local sliding window layers (with a tiny 128-token window) to global attention layers. This achieves a reported 6x reduction in KV cache memory usage. To compensate for the limited local view, it employs a “learnable attention sink bias” to maintain coherence over its full 256k context. The trade-off is clear: immense speed and memory savings, but potentially at the cost of nuanced, long-range reasoning, a point of contention for Retrieval-Augmented Generation (RAG) use cases.
Second is Multi-Token Prediction (MTP), baked directly into the architecture. Instead of relying on a separate draft model for speculative decoding, MiMo-V2-Flash integrates lightweight, dense Feed-Forward Networks (FFNs) into its blocks, adding only 0.33B extra parameters per block. During inference, it predicts multiple future tokens in a single forward pass, which Xiaomi claims triples the generation speed.
The final piece is the post-training process, dubbed Multi-Teacher On-Policy Distillation (MOPD). Here, the student model (MiMo-V2-Flash) learns from its own generations, guided by token-level rewards from multiple expert teacher models. This approach, trained on over 100,000 verifiable GitHub issues, is designed to produce a model that excels at execution, writing code, interpreting errors, iterating, rather than just conversation.
The Community Double-Click: “Benchmaxxed” or Breakthrough?
This is where the story gets spicy. Developer forums are not taking Xiaoami’s word for it. The Reddit discussion reveals a significant gap between official scores and grassroots experience.
One user pointed out that the Artificial Analysis Index (which favorably ranked MiMo-V2-Flash) has inconsistencies, such as ranking GPT-OSS 120B above the generally superior GLM 4.6. Skepticism runs high, with comments suggesting the performance is “suspiciously good for a model of this size.”
More damning are the real-world, qualitative reports. One developer noted that while the benchmarks look great, the model was “all over the place, not able to follow instructions” and that “tool call was unreliable,” even returning code for a simple “hello how are you” prompt. Another community reviewer, in a detailed Medium post, ran a side-by-side test on a “Flappy Dragon” game creation task.
Their finding? “The first game was created by MiMo-V2-Flash that resulted in my browser ‘freezing’ midgame. The second game was created by Gemini 3 Pro and it was fun to play.”
The consensus forming on forums is nuanced. The model appears to be highly task-specific. It might crush mathematical reasoning (its strong AIME score suggests this) and certain coding benchmarks, but falter on general instruction-following and creative tasks. This points to aggressive optimization and potentially “benchmark contamination”, training or fine-tuning that overfits to the specific problems in popular evaluations like SWE-Bench.
How It Stacks Up: The Real Competitive Landscape
Let’s put MiMo-V2-Flash in a real-world lineup.
- vs. DeepSeek-V3.2: DeepSeek activates 37B parameters per token vs. MiMo’s 15B. If MiMo’s benchmarks hold, it suggests a 60% reduction in active compute for similar results. However, DeepSeek has established reliability. Community feedback often places DeepSeek-V3.2 Speciale as more trustworthy for general use.
- vs. Claude Sonnet 4.5: This is the cost/value battleground. Claude costs $4.0/million input tokens. MiMo costs $0.1. That’s a 40x price difference. Even if MiMo is slightly worse, the price-performance ratio could be transformative for cost-sensitive agentic workflows.
- vs. GPT-5 High: This is the aspirational comparison. MiMo’s 94.1% on AIME 2025 vs. GPT-5’s 94.6% is too close to call statistically. But GPT-5’s broad, consistent intelligence across diverse tasks remains its unquantifiable moat.
The “Flash” in Practice: Deployment and Gotchas
If you want to try it yourself, the model is available on Hugging Face. The recommended deployment route is via SGLang, an inference framework that supports its unique architecture out of the gate. Here’s the basic setup command straight from the docs:
python3 -m sglang.launch_server \
--model-path XiaomiMiMo/MiMo-V2-Flash \
--served-model-name mimo-v2-flash \
--tp-size 8 \
--dp-size 2 \
--enable-dp-attention \
--host 0.0.0.0 \
--port 9001 \
--trust-remote-code \
--context-length 262144 \
--enable-mtp
Hardware is the kicker. For the claimed 150 tokens/sec performance, you’re looking at 8x H100 80GB GPUs. A more modest setup with 4x H100s and FP8 quantization will get you about 50 tokens/sec. This isn’t a consumer card project.

The community also flags critical configuration needs: always use the official system prompt, and be explicit with parameters. For agentic tasks and coding, a low temperature of 0.3 is recommended, while math and writing tasks perform better at 0.8.
What This Means: An Inflection Point for Efficiency
Xiaomi’s move isn’t just about releasing a model, it’s a declaration about priorities. In a field obsessed with scaling parameter counts into the trillions, MiMo-V2-Flash asks: Is raw size the only path to intelligence?
Its architecture is a masterclass in thoughtful constraint. The aggressive 128-token sliding window, the integrated MTP, the MoE design, every choice maximizes throughput and minimizes cost. This isn’t a model built to win a chatbot beauty pageant. It’s an execution engine, optimized for a future where AI agents perform defined, computational tasks at scale.
The open-source release under the MIT license is the most significant part. It invites scrutiny and iteration. The community can now probe its weaknesses, fine-tune it for specific domains, and potentially validate or debunk its benchmark claims. If the performance is real, it provides a stunningly efficient new baseline. If it’s largely “benchmaxxed”, it’s a fascinating case study in the gulf between curated evaluations and practical utility.
The Bottom Line: Cautiously Optimistic, Pragmatically Skeptical
MiMo-V2-Flash is a fascinating data point in the evolution of LLMs. It proves that with clever architecture, you can achieve top-tier results on specific, hard benchmarks with a fraction of the active compute. Its pricing makes high-end AI agentic workflows suddenly plausible for more organizations.
However, the initial user reports paint a picture of a brilliant but brittle specialist. It might be your go-to for automating complex mathematical problem-solving or generating code patches, but don’t expect Claude-level conversational polish or GPT-4’s generalist grace.
For researchers and engineers, it’s a must-try experiment. For companies looking to deploy reliable, general-purpose AI assistants, it’s a “wait and see.” The model is available on Hugging Face and through a free API trial. The burden of proof has shifted from Xiaomi’s marketing slides to the code running on your hardware. The next few weeks of community testing will determine if this is the efficiency breakthrough it claims to be, or just another reminder that in AI, the devil is always in the fine print.



