
The open-source AI community just dropped something that makes the general-purpose model arms race look like a sideshow. While everyone obsesses over chatbots that can write mediocre poetry, Intern-S1-Pro is quietly achieving state-of-the-art results on scientific reasoning benchmarks with a trillion-parameter MoE architecture that only activates 22 billion parameters per token. That’s not just efficient, that’s a statement.
The Architecture: When Bigger Actually Means Smarter
Let’s cut through the parameter-count hype. Yes, Intern-S1-Pro scales to 1 trillion parameters, but the real story is in its sparsity. With 512 experts and only 8 activated per token, it maintains a 22 billion active parameter footprint. This isn’t just a computational trick, it’s a fundamental design choice that lets the model specialize without bloating inference costs.
The MoE implementation uses two critical innovations:
- STE Routing (Straight-Through Estimator): Unlike traditional MoE routers that struggle with gradient flow, STE provides dense gradients for router training. This means the model actually learns which expert to use rather than stumbling through random allocation. The result? Stable convergence and balanced expert parallelism, problems that have plagued MoE models since their inception.
- Grouped Routing: This isn’t just load balancing, it’s expert democracy. By grouping experts and distributing tokens intelligently, Intern-S1-Pro avoids the “hot expert” problem where a few specialists burn out while others collect dust.
But the real magic for scientific applications is Fourier Position Encoding (FoPE). Standard position encodings treat sequences like flat text, FoPE understands that scientific data, especially time-series, has periodic structure. The model supports heterogeneous time-series from 10^0 to 10^6 points, meaning it can handle everything from millisecond chemical reactions to million-point seismic data without breaking a sweat.
Benchmark Reality Check: Beating Closed-Source at Their Own Game
The performance numbers don’t just impress, they challenge the assumption that only proprietary models can lead in science. On MMLU-Pro, Intern-S1-Pro scores 83.5%, matching DeepSeek-R1-0528 and trailing only Gemini-2.5 Pro (86.0%) and o3 (85.0%). For an open-source model, that’s punching well above its weight class.
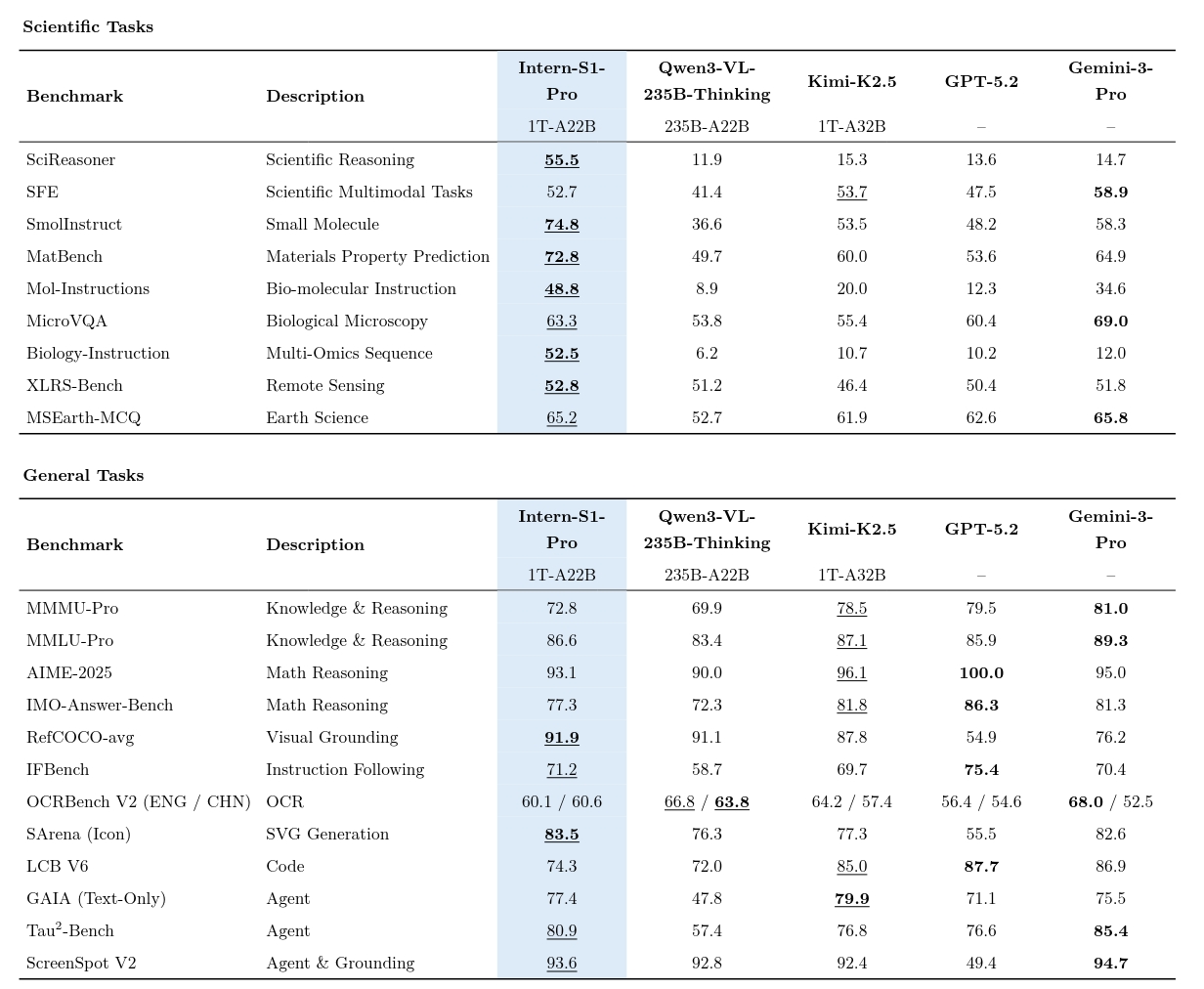
Where it really shines is domain-specific science:
- ChemBench: 83.4% (best among open-source, competitive with Gemini-2.5 Pro’s 82.8%)
- MatBench: 75.0% (outperforming Kimi-K2’s 61.7%)
- Physics: 44.0% (nearly double InternVL3-78B’s 23.1%)
- SFE (Scientific Figure Explanation): 44.3% (beating GPT-4o’s 43.0%)
The model achieves these results while maintaining strong general multimodal capabilities. It’s not a one-trick pony that sacrifices broad understanding for narrow expertise, it’s a thoroughbred designed for scientific workflows.
The Community Response: Excitement Measured in VRAM
The Reddit discussion around Intern-S1-Pro reveals a community that’s both impressed and pragmatic. Researchers immediately noted the model’s 262,144 token context window (clarifying early confusion about a 32K limit), which makes it viable for analyzing full research papers, not just abstracts. For context, that’s enough to process a 200-page thesis in a single pass.
The sentiment around specialist models is clear: “I like these specialist models”, one researcher noted. “Not all models need to do everything.” This reflects a growing fatigue with general-purpose models that promise to do everything but excel at nothing.
However, the community also raised deployment realities. Without llama.cpp support, running Intern-S1-Pro locally requires GPU+CPU hybrid inference. One researcher calculated that with 96GB VRAM, most weights would need to live in system RAM, a reminder that trillion-parameter models remain infrastructure-heavy, even with MoE sparsity.
The comparison to forgotten models like Ling/Ring serves as cautionary tale. As one commenter observed, “Everyone forgets ling/ring lol”, noting that despite impressive specs, those models failed to deliver practical results. Intern-S1-Pro’s lineage from Qwen3 235B Instruct (evidenced by matching token IDs and attention dimensions) suggests a more mature foundation, but the community will judge by results, not ancestry.
The Scientific AI Landscape: Specialization vs. Generalization
Intern-S1-Pro arrives at a pivotal moment. The Nature paper on OpenScholar, published just a day before this announcement, demonstrates that retrieval-augmented scientific models can outperform human experts on literature synthesis tasks. OpenScholar-8B beats GPT-4o by 6.1% on multi-paper synthesis while achieving citation accuracy on par with human researchers, something GPT-4o fails at 78-90% of the time.
This creates a fascinating dichotomy. While OpenScholar focuses on retrieval and synthesis, Intern-S1-Pro tackles direct reasoning over scientific data. Together, they represent a bifurcation in AI4Science: systems that find and connect knowledge versus systems that reason about it natively.
OpenAI’s Prism project (covered in our analysis of scientific AI capabilities) takes yet another approach, integrating GPT-5.2 into LaTeX workflows for theorem proving and paper writing. The common thread? Specialization beats scale when domain expertise matters.
Practical Deployment: From Cloud to Cluster
Intern-S1-Pro’s ecosystem integration shows serious engineering intent. Support for vLLM and SGLang means it’s not a research toy, it’s built for production serving. The recommended hyperparameters (top_p=0.95, top_k=50, temperature=0.8) suggest a model that thrives on controlled creativity rather than rigid determinism.
For researchers wanting to experiment, the deployment path is clear but demanding:
# Example from the deployment guide
from openai import OpenAI
client = OpenAI(
api_key="EMPTY",
base_url="http://0.0.0.0:23333/v1"
)
response = client.chat.completions.create(
model="intern-s1-pro",
messages=[{"role": "user", "content": "Explain the quantum tunneling effect in semiconductors"}],
temperature=0.8,
top_p=0.95,
max_tokens=32768
)
The model also supports dynamic thinking mode control, allowing you to toggle between deep reasoning and faster responses:
# Disable thinking for simpler queries
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
This flexibility is crucial for scientific workflows where some tasks need exhaustive reasoning and others just need quick, accurate answers.
The Implications: Open Science Gets a Power Tool
Intern-S1-Pro’s Apache 2.0 license isn’t just permissive, it’s strategic. In a field where the best models are increasingly closed, releasing a trillion-parameter scientific specialist as open-source is a statement. It suggests confidence that the real moat isn’t model weights but the infrastructure to train and serve them.
For research institutions, this changes the calculus. Instead of relying on API access to closed models that hallucinate citations and lack domain depth, labs can deploy Intern-S1-Pro on their own infrastructure. The implications for reproducibility alone are massive, no more wondering if GPT-4o gave you a different answer than it gave your colleague because of stealth updates.
The model’s performance on agentic benchmarks like Tau2 Bench (beating Kimi 2.5, supposedly the agentic specialist) adds another dimension. This isn’t just a passive question-answerer, it’s a system that can potentially plan experiments, analyze multi-modal data, and synthesize insights across papers.
The Counter-Narrative: Size Isn’t Everything
Let’s address the elephant in the lab: trillion parameters don’t guarantee success. The Ling/Ring models proved that spectacularly, delivering disappointing real-world performance despite impressive specs. Intern-S1-Pro’s authors seem to have learned this lesson, focusing on training efficiency and stable convergence rather than just scale.
The model’s 22B active parameters are actually fewer than Kimi K2’s activated count, making it theoretically faster and more efficient. But as the community notes, “without llama.cpp support, it is a bit hard to get going.” The gap between theoretical performance and practical deployment remains significant.
Moreover, the Nature study’s findings on citation hallucination serve as a sobering reminder: even models with perfect benchmark scores can fabricate references. Intern-S1-Pro’s scientific reasoning capabilities must be paired with retrieval systems like OpenScholar to ensure factual grounding. The model is a reasoning engine, not a knowledge base.
The Road Ahead: Integration Over Isolation
The real power of Intern-S1-Pro will emerge when it’s integrated into scientific workflows. Imagine a pipeline where:
1. OpenScholar retrieves and synthesizes relevant literature
2. Intern-S1-Pro reasons over the data and proposes hypotheses
3. Prism helps write and verify the resulting paper
4. A local LLM with internet access keeps the entire system current
This isn’t science fiction, it’s a plausible near-term architecture built on open-source components.
The model’s limitations are clear: no llama.cpp support (yet), heavy hardware requirements, and the need for careful prompt engineering. But its release signals a maturation of AI4Science, moving from proof-of-concept to production-ready tools.
Key Takeaways
- Specialization wins: Intern-S1-Pro proves that domain-specific architectures can match or exceed general-purpose closed models on scientific tasks
- Efficient scale: The 1T/22B MoE design demonstrates that parameter count is less important than architectural innovation
- Open science momentum: Apache 2.0 licensing and ecosystem integration (vLLM, SGLang) make this a practical tool, not a demo
- Hardware reality check: You’ll need serious infrastructure to run this, but less than a dense 1T model would require
- Integration imperative: The model’s true value emerges when combined with retrieval systems and scientific workflows
Intern-S1-Pro won’t replace your lab notebook tomorrow. But it might just replace your reliance on closed AI APIs, and that’s a shift worth paying attention to. The age of specialized, open-source scientific AI isn’t coming, it’s here, and it’s measured in trillions of parameters.



