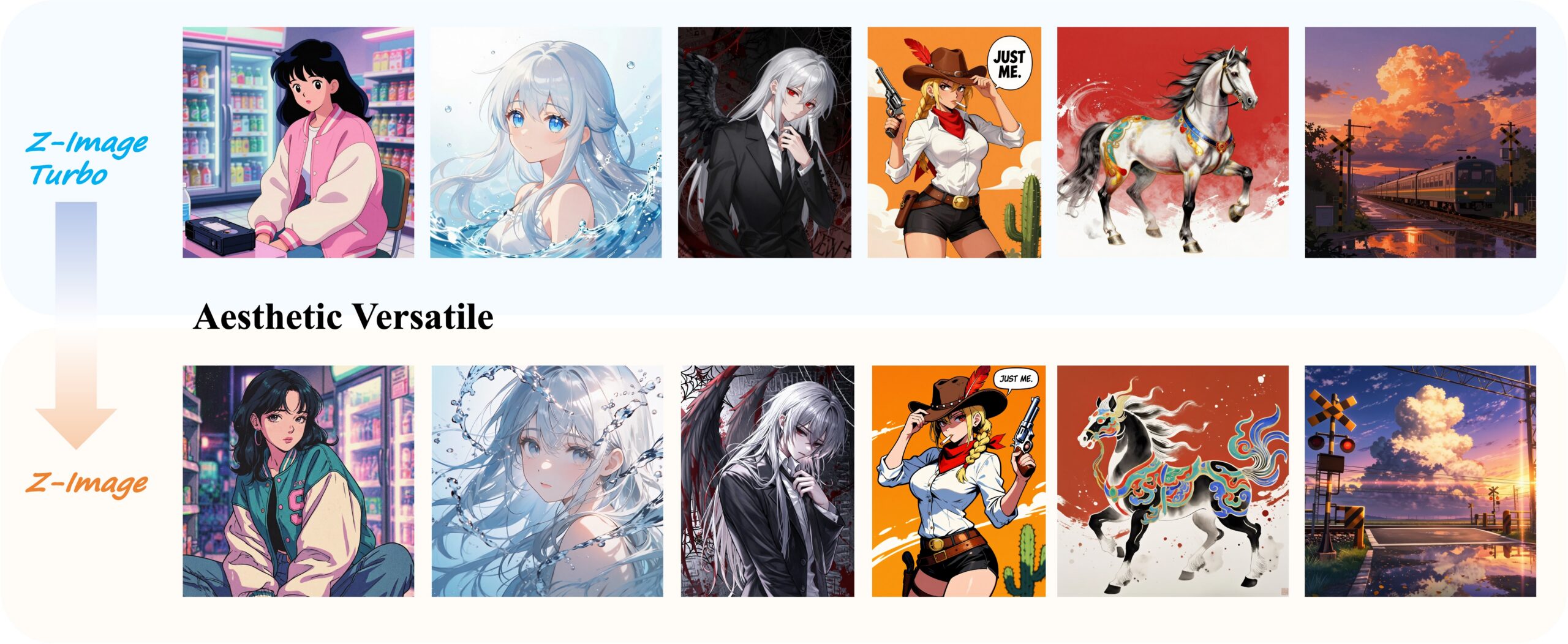
Alibaba’s Z-Image Model Delivers Power and Speed, But Its Demo Bias Is Hard to Ignore
Alibaba’s Tongyi Lab just dropped Z-Image, a vision-language model that compresses impressive capability into just 6 million parameters. The model runs on 6GB GPUs, generates high-quality realistic images, and supports full Classifier-Free Guidance for professional workflows. But within hours of its Hugging Face release, the AI community zeroed in on something the model card didn’t mention: its demo gallery is overwhelmingly populated by images of Asian women, sparking heated debates about bias, marketing, and whether China’s AI labs are learning the wrong lessons from Western model releases.
The Tease That Became a Release
The Qwen team didn’t announce Z-Image with a splashy press release. Instead, they let the code do the talking. Developers first noticed new T2I workflow templates appearing in ComfyUI repositories, followed by cryptic updates to model collections on Hugging Face. The speculation peaked when the Tongyi-MAI organization quietly published the model repository, immediately triggering download scripts across the community.
This stealth release strategy mirrors how Chinese AI labs are increasingly operating, moving fast, shipping code, and letting performance metrics speak louder than marketing. It’s a direct contrast to the carefully choreographed launches from OpenAI or Google, and it reflects the resource constraints Chinese labs face. When compute is scarce, you don’t waste it on press tours.
Technical Specs: Small but Mighty
- 6 million parameters, small enough to load on modest hardware
- 512×512 to 2048×2048 resolution support with arbitrary aspect ratios
- 28-50 inference steps for base model (vs. 8 for Turbo)
- Guidance scale 3.0-5.0 for precise prompt adherence
- 6GB GPU compatible, runs on consumer hardware with quantization
The model supports both Chinese and English prompts, though early testers note it handles English more reliably. The Hugging Face demo shows impressive results on realistic photography, with particular strength in natural lighting and skin tone rendering, though that strength may also reflect its training distribution.

The Elephant in the Room: Demo Bias
The most discussed aspect of Z-Image isn’t its architecture, it’s the demo gallery. Community members quickly observed that roughly 90% of the example images feature women, and within that subset, approximately 99% appear to be Asian. When compared side-by-side with Western models like Flux Klein, which default to generating Caucasian features, Z-Image’s bias becomes starkly apparent.
This isn’t just a cosmetic issue. The pattern reveals deep-seated biases in training data curation and target audience assumptions. As one developer noted, the model doesn’t hide its primary use case, but that transparency exposes a troubling feedback loop: models trained on datasets that over-represent certain demographics produce outputs that reinforce those representations, which then shape user expectations and future data collection.
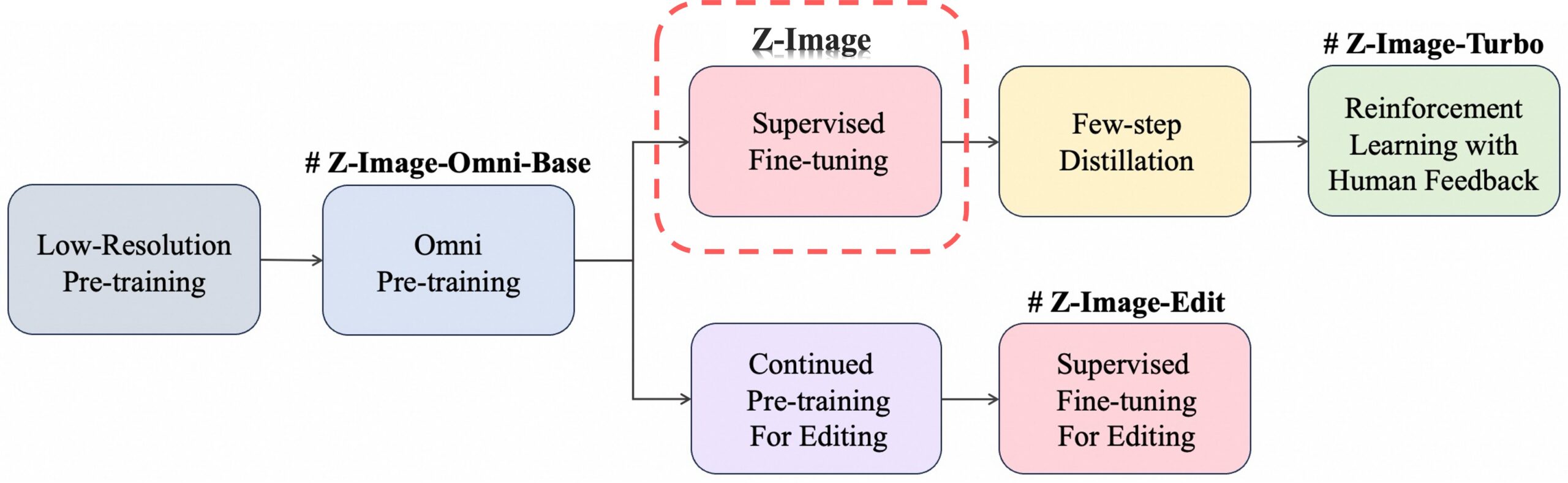
Base vs Turbo: A Strategic Split
| Feature | Z-Image Base | Z-Image Turbo |
|---|---|---|
| CFG Support | ✅ Full | ❌ Disabled |
| Inference Steps | 28-50 | 8 |
| Finetunability | ✅ Yes | ❌ No |
| Negative Prompting | ✅ Yes | ❌ No |
| Output Diversity | High | Low |
| Visual Quality | High | Very High |
| RL Training | ❌ No | ✅ Yes |
The base model preserves the complete training signal, making it ideal for researchers, artists, and developers who need fine-grained control. The turbo variant, trained with reinforcement learning, optimizes for speed at the cost of flexibility, perfect for rapid prototyping or applications where iteration speed matters more than precise control.
Community Reaction: Excitement and Skepticism
The developer response has been predictably mixed. On one hand, excitement about a powerful, lightweight model that can run locally has been palpable. The promise of finetuning capabilities has already sparked discussions about anime-style variants, something the turbo model notoriously fails at.
On the other hand, questions about competitiveness loom large. With models like Flux Klein offering full model access, distilled versions, and editing capabilities, some wonder if Z-Image arrived too late. The sentiment reflects broader anxiety about China’s ability to keep pace with Western labs despite impressive multimodal capabilities in models like Qwen3-VL.
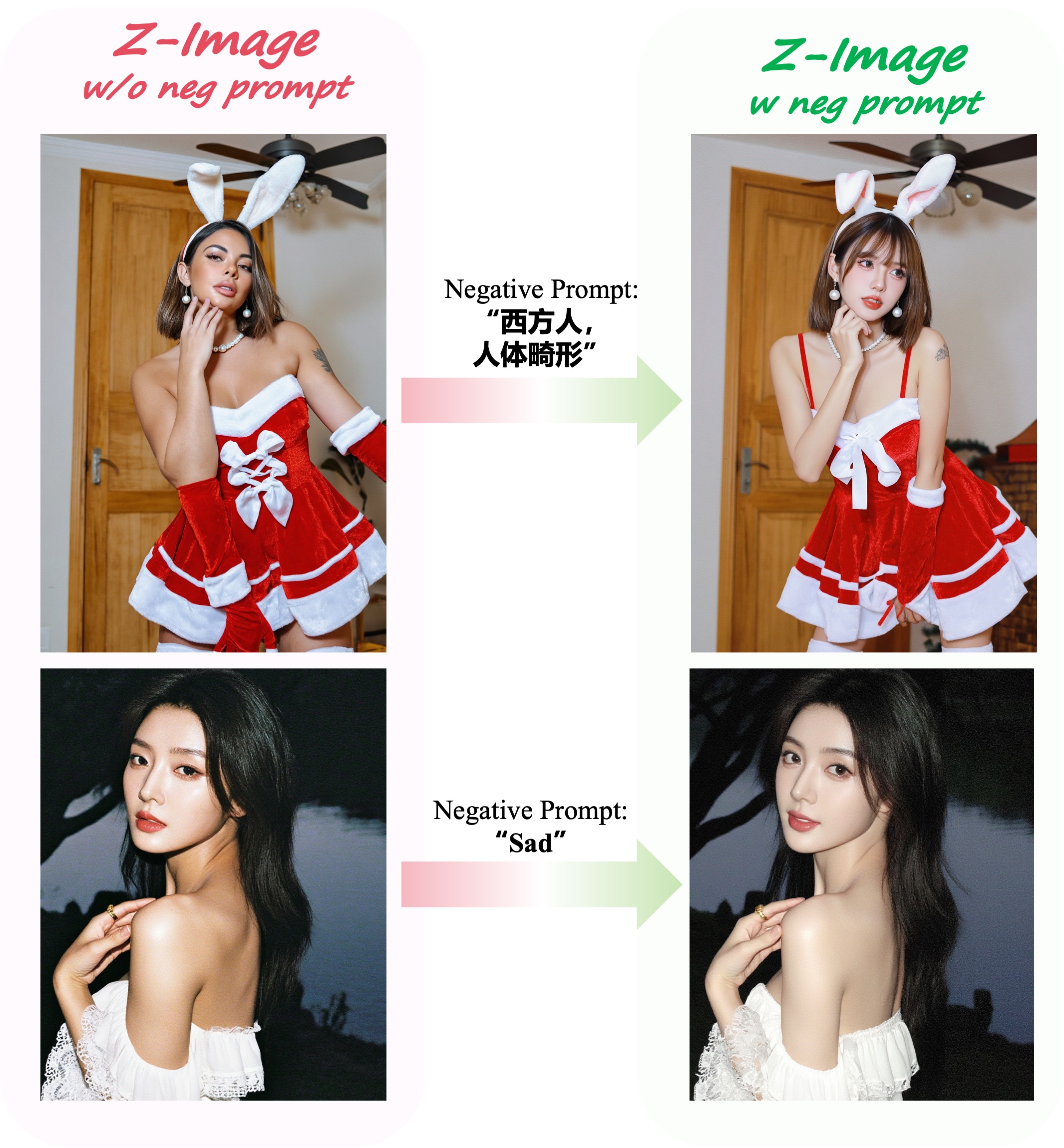
The Competitive Landscape
Z-Image enters a crowded field. Flux Klein has established itself as the go-to for open-source image generation, with better documentation, a more active ecosystem, and critically, less demonstrable bias in default outputs. Western models still dominate global benchmarks, and they benefit from training on more diverse (though still biased) datasets.
But Z-Image has one killer advantage: it’s designed from the ground up for efficiency. The 6M parameter count is a fraction of Flux’s size, making it far more accessible to researchers without corporate backing. For the Chinese domestic market, having a state-of-the-art model that understands Chinese cultural nuances and can run on local hardware isn’t just convenient, it’s strategically vital.
What This Means for China’s AI Ambitions
Z-Image’s release fits into a larger pattern of Chinese AI labs pushing forward despite severe constraints. With export controls limiting access to cutting-edge GPUs, labs like Tongyi are forced to innovate on efficiency rather than just scale. The result is models like Z-Image that prioritize parameter count and inference speed over raw parameter bloat.
This resource constraint is creating a different optimization function. Where Western labs can throw compute at problems, Chinese researchers have to be clever. The single-stream diffusion architecture, aggressive quantization support, and focus on consumer-grade hardware all reflect this reality.
The question isn’t whether China can build competitive AI, it clearly can. The question is whether it can build AI that serves diverse global needs while navigating domestic pressures and resource constraints.
Bottom Line
Z-Image represents both the promise and peril of China’s AI strategy. Technically, it’s a triumph, a powerful vision-language model that runs where others can’t, supports full finetuning, and delivers quality that rivals models many times its size. The community has already begun building on it, creating workflows and nodes that make it accessible to non-technical users.
But the demo bias controversy serves as a reminder that technical capability without thoughtful data curation creates blind spots. As one developer put it, “they don’t hide the #1 use case”, but maybe they should question why that use case dominates in the first place.
For practitioners, the choice is clear. If you need a lightweight, finetunable model for specific domains and can curate your own training data, Z-Image Base is compelling. If you want fast generation with less bias out of the box, alternatives like Flux Klein remain safer bets. And if you’re watching the geopolitical AI race, Z-Image shows that China’s labs can innovate under pressure, though the direction of that innovation still needs work.