30 articles found
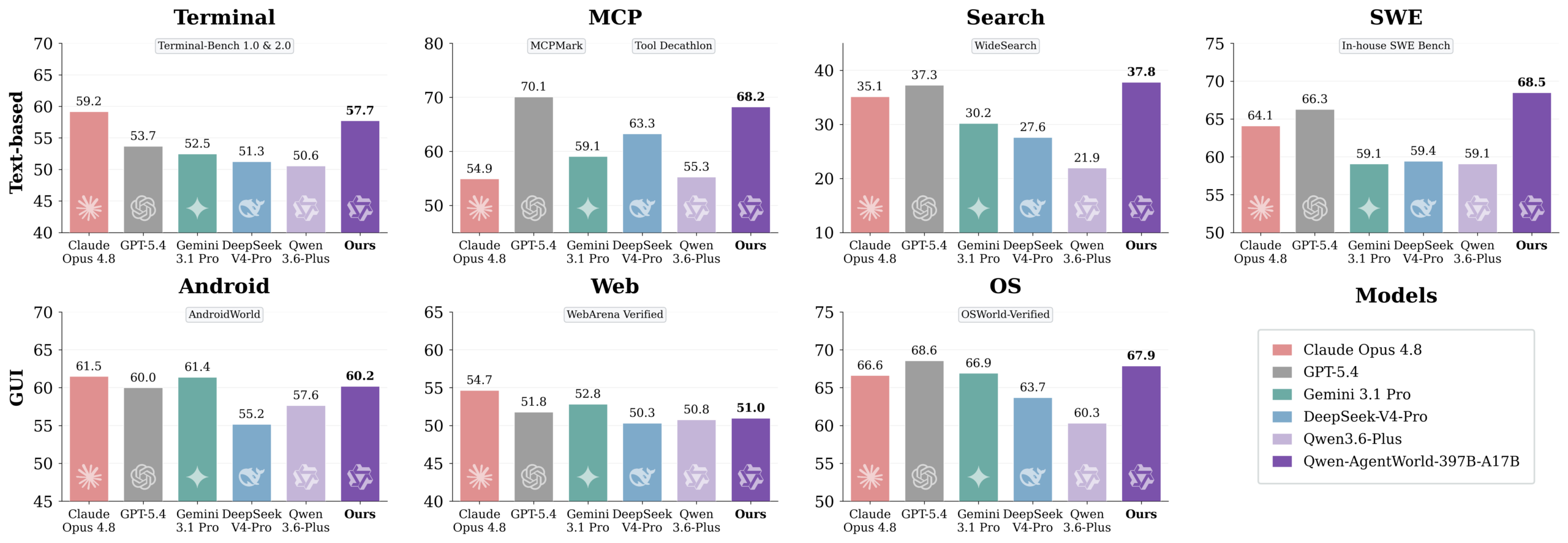
Alibaba’s new 35B MoE model (3B active) can simulate seven different agent environments, MCP, terminal, web, Android, and more, without running the real tools.
Alibaba’s Qwen 3.7 Max Preview scored 57 on the Artificial Analysis Intelligence Index and hit #7 in Math on Arena AI, but the open-weight 27B and 35B variants the community actually runs remain stubbornly unavailable.
Alibaba’s Qwen 3.7 previews appeared in Qwen Chat before anyone got a press release, sending the open-source community into a benchmarking frenzy and reviving the debate over open weights versus cloud lock-in.
A deep dive into the latest uncensored Qwen3.6 27B release, exploring MTP preservation, NVFP4 quantization, and what happens when safety training gets neuro-surgically removed.
Qwen 3.6 27B on consumer hardware is disrupting the SaaS subscription model. Here’s how, and why it’s a warning sign for cloud AI.
Investigation into the integrity and safety of ‘abliterated’ open-source models (HauhauCS/Heretic/Huihui), focusing on forensic benchmarking results and community fallout from model modification claims.
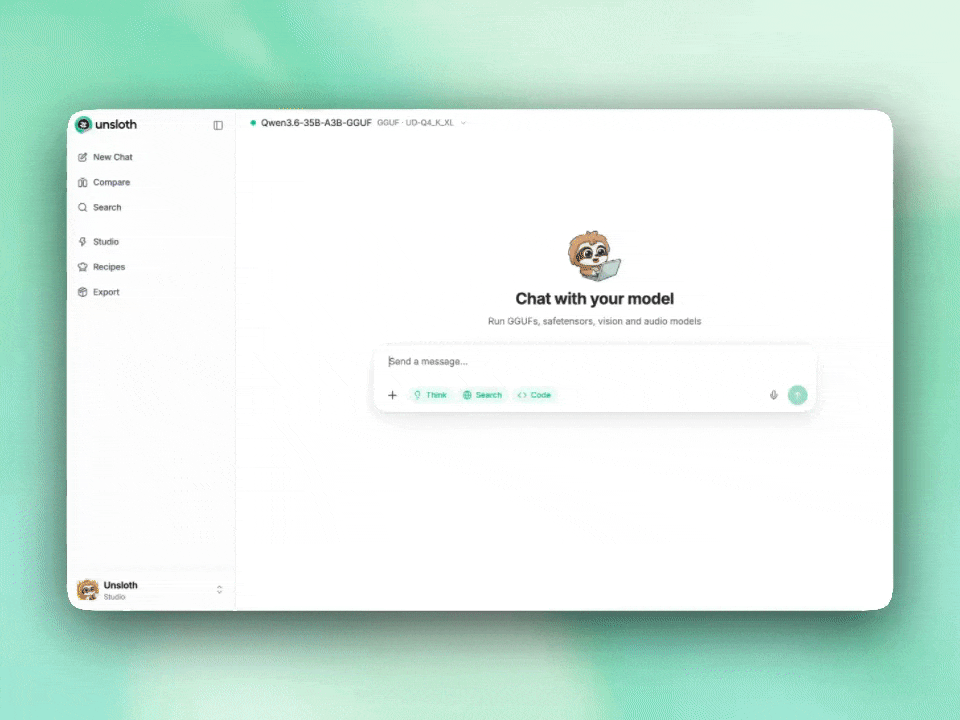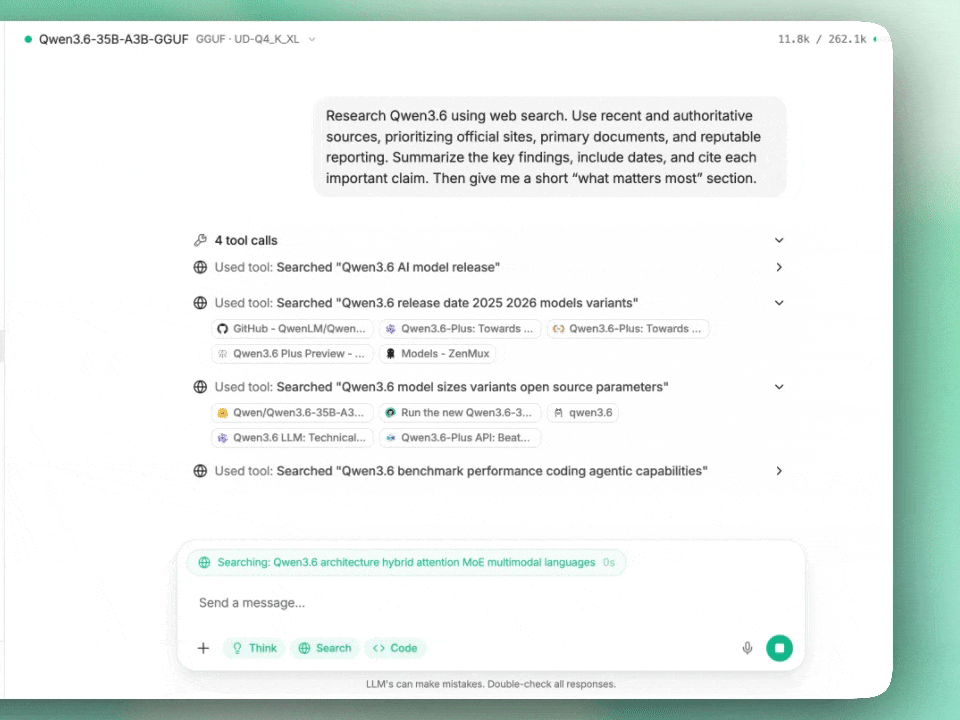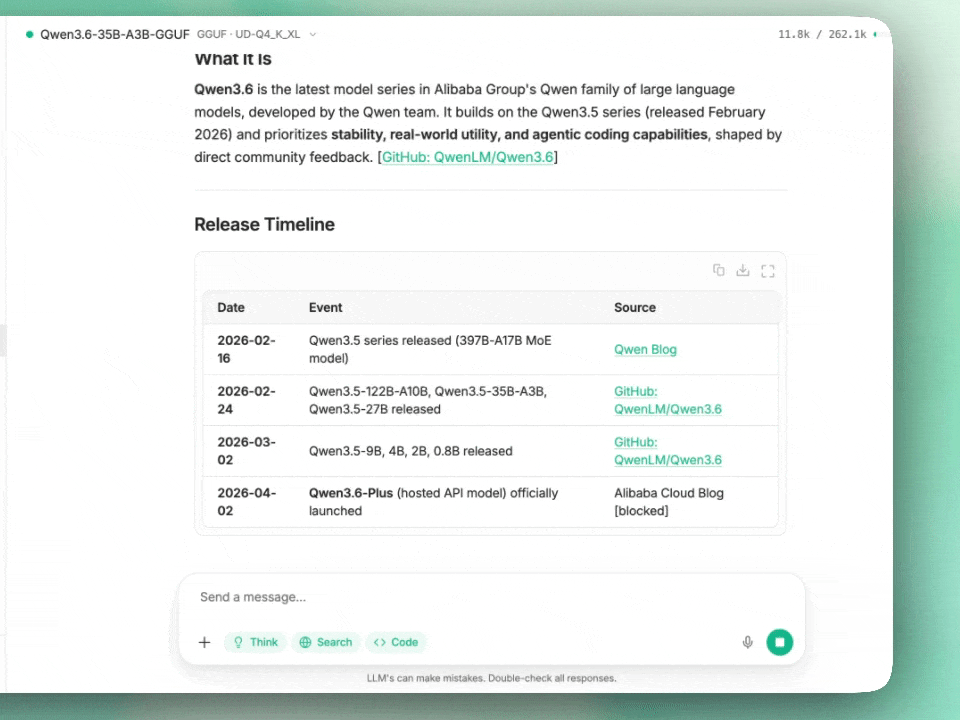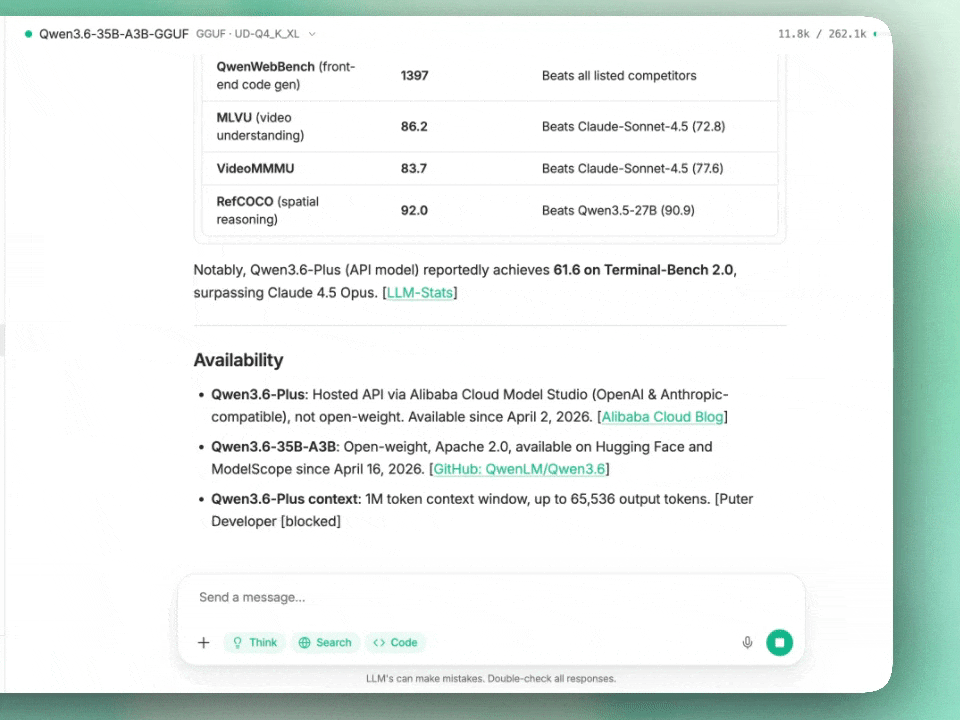
Alibaba’s Qwen3.6-35B-A3B activates only 3B parameters per token yet claims agentic coding parity with models 10x its size. We dissect the architecture, benchmarks, and whether this Apache 2.0 release actually changes the local AI equation.
Developer presents solution for deeply recursive union types in Qwen function calling – an area industry generally claims doesn’t work. Achieved 100% first-try success rate on qwen3-coder-next fixing double-stringify bugs affecting entire Qwen 3.5 family.
Experimental analysis of Qwen 3.5’s latent representations reveals cross-lingual convergence in middle layers, suggesting transformers develop a language-agnostic reasoning space.
Technical autopsy of why NVIDIA’s highly anticipated Nemotron 3 4B collapsed under reasoning benchmarks while Qwen 3.5 4B sailed through, despite the hype around Elastic compression and Mamba-2 hybrids.
How Qwen 3.5 0.8B manages complex spatial reasoning and action execution on smartwatch-grade hardware, and what it means for the future of edge AI.
Analysis of Alibaba CEO’s commitment to keep Qwen open-source alongside Unsloth GGUF optimizations and community benchmarks, set against the backdrop of commercial AI consolidation and internal team exodus.
Alibaba’s Qwen team is imploding just as they released their best models yet. Here’s how to exploit the chaos using Unsloth to fine-tune Qwen3.5 on consumer hardware.
Qwen 3.5’s sub-10B models are outperforming last generation’s giants, and with Unsloth’s Dynamic 2.0 quantization, they’re running on your phone at 60 tokens per second. The ‘GPU poor’ just got their revenge.
Alibaba’s Qwen 3.5 small series (0.8B-9B) is rewriting the rules of AI efficiency, with the 9B dense model outperforming 30B+ competitors and proving that smart architecture beats raw parameter count.
GPQA and HLE, benchmarks that determine which AI models lead the pack, are fundamentally broken. The Qwen team’s systematic verification reveals incorrect answers, ambiguous problems, and systematic errors that artificially deflate model scores by up to 40%.
Alibaba’s Qwen3.5-397B-A17B ranks #3 in the Artificial Analysis Intelligence Index, challenging Llama’s open-source dominance with a sparse MoE architecture that activates only 17B of its 397B parameters, no chain-of-thought required.
Alibaba’s Qwen-Image-2.0 delivers native 2K resolution, professional typography, and unified generation/editing in a 7B model that challenges assumptions about what smaller models can achieve.
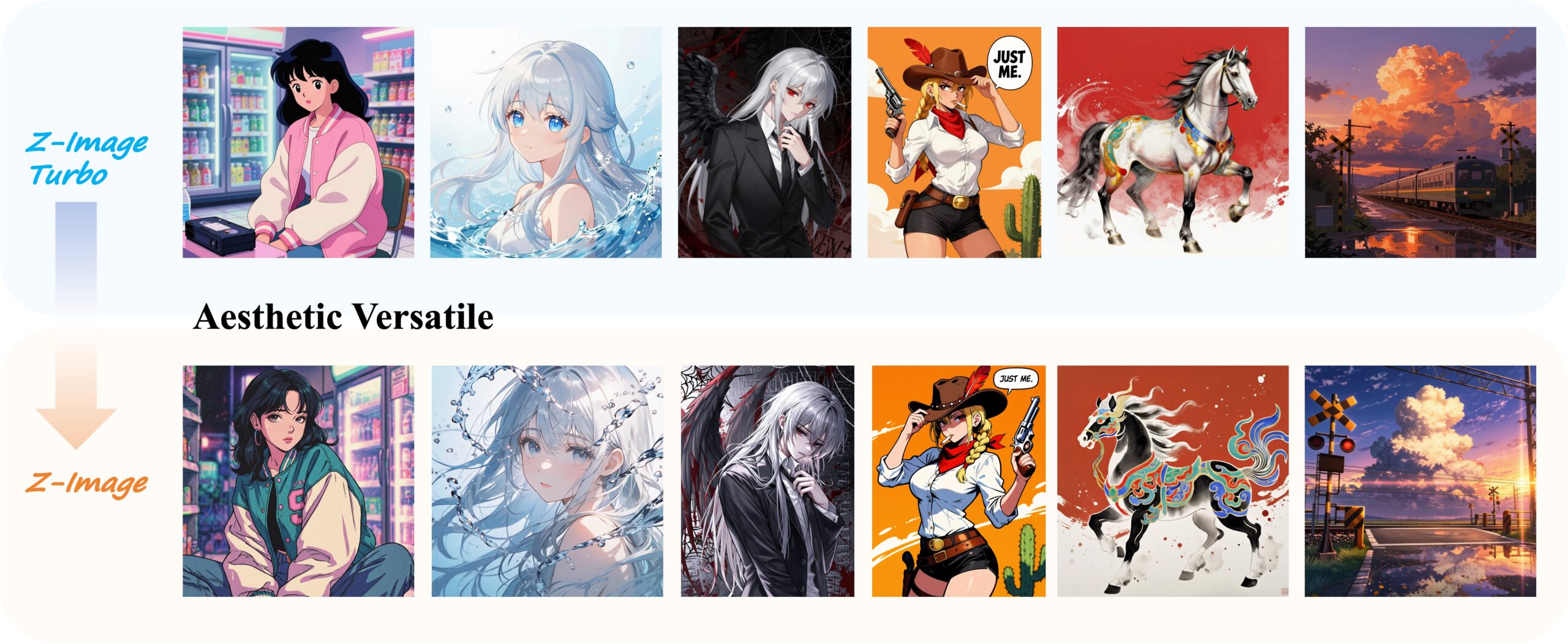
The Qwen team’s latest vision-language model Z-Image impresses with 6M parameters and consumer GPU compatibility, while raising uncomfortable questions about representation in AI training demos.
Alibaba’s Qwen team lead reveals how compute constraints and export controls are creating a structural gap that Chinese AI firms can’t optimize their way out of
Alibaba’s Qwen team releases an open-source image generator that doesn’t just compete with closed-source models, it beats them at their own game on human realism, text rendering, and fine details.
DeepFabric’s fine-tuned Qwen3-4B achieves 93.5% tool calling accuracy, crushing Claude Sonnet 4.5 (80.5%) and Gemini Pro 2.5 (47%). Here’s how synthetic data, real tool execution, and domain focus rewrite the rules for cost-effective AI agents.
Alibaba’s Qwen team just dropped a major image editing upgrade that fixes AI’s identity amnesia problem, while baking in community LoRAs and challenging the hardware status quo.
Recent benchmarks reveal local vision-language models like Qwen3-VL achieving near-perfect performance in OCR and complex visual tasks, challenging assumptions about cloud dependency.
Qwen’s open-source LLM has surged to 20% of OpenRouter traffic while outperforming Claude on key benchmarks. We analyze the data behind its rise, its real-world performance vs. marketing claims, and whether Alibaba’s bet can sustain against OpenAI and Anthropic’s funding firepower.
Alibaba’s Qwen3-VL 4B/8B models deliver enterprise-grade vision-language AI that runs locally on consumer hardware via GGUF, MLX, and NexaML.
China’s vision-language model outperforms GPT-5 Mini and Claude Sonnet while running locally – and developers are taking notice
Exploring how Qwen3Guard’s security-focused models challenge conventional AI safety approaches while delivering real-world protection.
Alibaba’s latest AI marvel dominates benchmarks while quietly locking down its most powerful model. The open-source community isn’t celebrating.
Alibaba’s trillion-parameter Qwen3-Max is crushing coding benchmarks and reshaping the AI landscape, but is it all smoke and mirrors?