
Which is all genuinely impressive, right up until you try to download the weights.
The Stealth Drop and the 97-Million-Token Fine Print
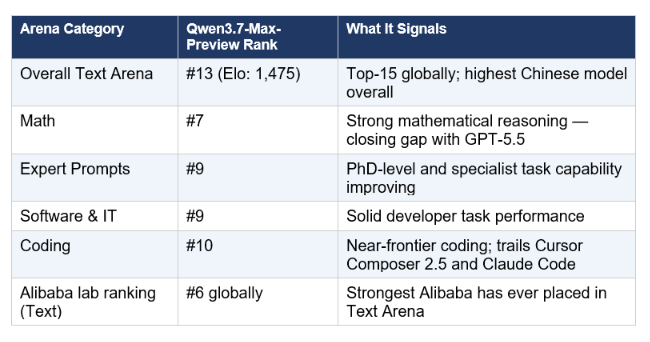
Alibaba’s playbook here is almost performance art. Drop the model anonymously on Arena, let developers pit it against GPT-5.5 and Claude Opus 4.7 for a week, then hold the Apsara Summit keynote once the buzz is self-sustaining. It worked for Qwen 3.6, and it worked again here. But the headline score comes with baggage that gets buried under the hype: during evaluation, Qwen 3.7 generated 97 million output tokens against a median of 26 million for the evaluated set. The benchmark report calls it “very verbose in comparison to the average”, which is reasoning-model speak for “it thinks out loud, extensively, and your API bill will feel every syllable.”
That verbosity matters because it highlights a basic truth: the 57 AAI score measures the hosted Max Preview running on Alibaba’s first-party silicon at presumably BF16 precision. It tells you approximately nothing about how an open-weight 27B or 35B variant will behave on your desktop RTX 3060 crammed into Q4_K_M quantization. Precedent from the 3.6 generation is instructive. Qwen 3.6 Max Preview scored 52 AAI, the open Qwen 3.6-27B scored 46 under the same methodology, a six-point gap. If history repeats, the open Qwen 3.7 27B lands around 51 AAI. That’s excellent, essentially tied with 3.6 Max, but well below the 57-point headline everyone is retweeting.
The Open-Weight Paranoia We All Deserve
If there is one thing the LocalLLaMA community has learned from Alibaba over the past year, it is that the word “open” now comes with asterisks the size of Apsara Summit keynotes. Alibaba’s open-source strategy and Qwen leadership changes have already sketched a bifurcated future: flagship Max models remain behind API walls, while mid-tier open-weights are released under Apache 2.0 to keep the ecosystem warm. Through Qwen 3.5, the family shipped everything open. Starting with 3.6, the Max tier went API-only. Qwen 3.7 follows that pattern precisely.
The community now assumes the 3.7-Max tier stays closed while 27B dense and 35B-A3B MoE variants eventually surface on Hugging Face. But “eventually” is doing Olympic-level heavy lifting. Open 27B and 35B weights are announced but unscheduled, and anyone claiming a firm date is either reading tea leaves or has a source inside Alibaba they aren’t sharing. Community sleuthing around researcher roadmaps has intensified, with anticipation posts racking up serious engagement, one discussion on the probability of another 27B release scored 1,128, while open-weight hype posts landed around 280. The message is clear: people want this. They just do not trust it will arrive on schedule.
Alibaba’s open-source track record is undeniable, over 942 million cumulative downloads by March 2026, more than 200,000 derivative models on Hugging Face, and a global open-weight download share exceeding 50%. That gravity is exactly why the closed-flagship pivot stings. The co-announcement of the Zhenwu M890 AI accelerator (144 GB on-chip memory, 800 GB/s inter-chip bandwidth) and the Panjiu AL128 supernode at Apsara signals vertical integration at hyperscale. It changes Alibaba’s unit economics, it does not change your ability to download a GGUF today.
The Hardware Hunger Games: Dense vs. MoE vs. Your Sad VRAM
Here is where the rubber meets the silicon for practitioners. The Qwen 3.6 generation already shattered the axiom that bigger means better. The Qwen3.6-27B dense model outperforming MoE architectures proved that a disciplined 27-billion-parameter dense architecture could beat MoE variants ten times its active size on coding and reasoning tasks. Community benchmarks consistently showed the 3.6 27B pulling ahead of the 35B-A3B in math and software benchmarks, occasionally outperforming 122B MoE configurations on specific tasks.
But there is a catch: dense 27B models are memory-hungry. On a 24GB card, you are living in quantization territory. The Qwen 3.6 27B backend performance on consumer GPUs already pushed llama.cpp and MLX to their limits, and that was the current generation.
For developers running more modest setups, think 16GB VRAM paired with 64GB, 96GB of system RAM, the 35B-A3B MoE has been the accessibility hero. Qwen3.6 sparse MoE architecture and active parameter efficiency, activating only 3 billion parameters per token, lets the model run at Q6_K_L quantization with hybrid CPU/GPU inference. Practitioners report 20, 30 tokens per second under these constraints, using llama.cpp server with context lengths pushed to 131K and Flash Attention enabled:
llama-server -hf bartowski/Qwen_Qwen3.6-35B-A3B-GGUF:Q6_K_L \
-c 131072 --jinja --temp 0.9 --top-p 0.95 --min-p 0.01 --top-k 40 \
--flash-attn on --cache-type-k q8_0 --cache-type-v q8_0 \
--parallel 1
A critical finding from the community: forcing --n-gpu-layers 99 can paradoxically degrade performance by choking the VRAM bus. Letting llama.cpp auto-manage layer offloading frequently doubles throughput. Others have fine-tuned further, explicitly pushing expert layers into CPU RAM while keeping attention matrices on GPU, yielding approximately 400 tokens per second in prompt processing and 30, 40 tok/s in generation.
Expected VRAM footprints for Qwen 3.7, extrapolated from 3.6 behavior, land around 15, 16 GiB for the 27B dense at Q4_K_M, and 18, 22 GiB for the 35B-A3B at Q4. Neither is confirmed, but both are close enough to plan a build around.
So when the community clamors for a Qwen 3.7 35B-A3B, it is not model-collector hoarding. It is a genuine infrastructure need. Local 27B models challenging cloud AI services only works if the models can actually fit on the hardware developers already own.
What Is Real, What Is Preview, and What Is Wishful Thinking
If you are trying to separate signal from vapor, the landscape as of May 20, 2026 looks like this:
| Artifact | Status |
|---|---|
| Qwen 3.7-Max-Preview (text) | Live on chat.qwen.ai and Arena AI since ~May 14 |
| Qwen 3.7-Plus-Preview (vision) | Live on chat.qwen.ai and Arena AI |
| Qwen 3.7-Max stable API | Rolling out on Alibaba Cloud Model Studio, pricing unannounced |
| Hugging Face open weights | Not released. Only Qwen 3.5 / 3.6 repos exist |
| Exact parameter counts | Unverified, treat “dual 72B” rumors as speculation |
| Standardized benchmarks (SWE-bench, GPQA, etc.) | Not published by Alibaba |
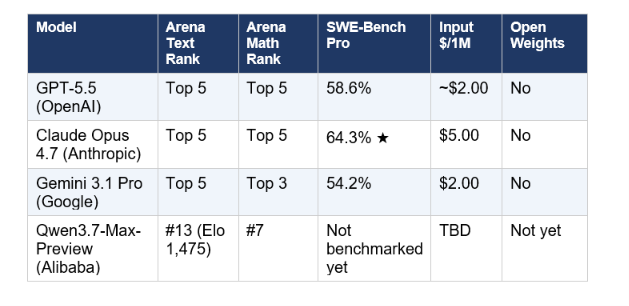
The vendor-reported claims from the Apsara keynote include a 35-hour sustained autonomous run without degradation and 1,000+ tool calls per session, optimized for frameworks like OpenClaw and Claude Code. These are interesting directional signals about agentic reliability, but they are currently unfalsifiable from the outside. The reproducible data lives in Arena’s neutral preference rankings, and those place Qwen 3.7 firmly in the second tier of closed flagships, competitive on math and software specialties, but trailing the absolute frontier on general-purpose chat.
For local AI practitioners, the guidance is uncomplicated: if you are shipping production code this month, keep running uncensored Qwen3.6-27B variant and quantization techniques or the 3.6 35B-A3B. The stack is mature, Qwen3.5 context window challenges for local inference have largely been solved in the 3.6 generation, and there is no reason to leave working performance on the table for a rumored release window. If you are evaluating vision pipelines, Qwen 3.7-Plus-Preview is worth a look today, Alibaba landing at #5 globally in vision represents a genuine narrowing of the multimodal gap.
When the Weights Drop: What to Actually Watch For
Assuming Alibaba follows the 3.6 cadence, expect mid-tier open weights within 2, 6 weeks of the Max announcement, with GGUF builds appearing 24, 72 hours after that via community quantizers like Bartowski and Unsloth. But five unknowns will determine whether the drop is practically useful:
- Local inference parity. Until weights ship, zero benchmarks are possible. Anyone publishing local performance numbers today is either repackaging API data or guessing.
- MTP layer availability. Multi-Token Prediction training for 3.7 variants is unconfirmed. If Alibaba skips it, the community would need to train MTP layers post-release to replicate the 60 tok/s speeds Qwen 3.6 hit on RTX 3090 hardware.
- DFlash / EAGLE3 compatibility. Speculative decoding depends on draft models that do not exist yet.
- MoE configuration. Whether the 35B retains the A3B ratio or shifts architecture entirely is pure speculation.
- License terms. Apache 2.0 is the historical default, but the pattern could change.
InsiderLLM has committed to a day-zero analysis when weights ship, followed by RTX 3090 plus RTX 3060 benches within 24 hours. That is the kind of coverage that matters, because Qwen 3.5 vs Gemma 4 long-context performance on 24GB VRAM debates are academic until someone verifies whether the new model actually runs on the hardware sitting on your desk.
The Verdict
Qwen 3.7 Max Preview is legitimately competitive. A #7 Math ranking on Arena is no accident, and Alibaba cracking the top 5 in vision represents a real shift in the multimodal race. But for the LocalLLaMA crowd, “preview” is just another word for “promised.” The 27B dense and 35B MoE variants are the products that will actually change how developers build, and until they are sitting on Hugging Face with Apache 2.0 licenses and verified SHA checksums, the “new king” remains a crown floating solely in Alibaba’s cloud.
If you are holding off on a hardware purchase waiting for 3.7, stop. A 24GB card handles the 3.6 family beautifully today, and any rig that runs 3.6 will run 3.7 when it eventually materializes. Qwen3.5 vs GPT-OSS-120b for local agentic coding already proved that the open-weights ecosystem moves fast, sometimes faster than the labs feeding it. The moment Alibaba flips the switch, the community will know whether Qwen 3.7 deserves the throne or merely another polite golf clap from the preview gallery.
Until then, keep your llamas sharp and your VRAM free. The models that run today still beat the models that benchmark tomorrow.



