

The Uncensored Qwen3.6: When Jailbreaking Meets 4-Bit Quantization
Hugging Face: an uncensored Qwen3.6-27B model with its Multi-Token Prediction (MTP) layers intact, preserved through a technique called Magnitude-Preserving Orthogonal Ablation. This isn’t just another “uncensored” fine-tune, it’s a surgical procedure that reduces refusals from 92 out of 100 test queries to just 6, while supposedly preserving 85.67% of the original model’s MMLU performance. The release includes versions quantized to NVFP4, GGUF, and GPTQ formats, kicking off a fresh race in the high-performance, low-overhead local inference space.
But here’s the uncomfortable truth: while the AI safety community frets about alignment, the open-weight community is developing increasingly sophisticated techniques for removing refusal directions to cure slop addiction. The llmfan46 release represents one of the cleanest, most technically sophisticated executions of this philosophy to date, preserving specialized architecture features while stripping guardrails.
What Even Are MTPs, and Why Should You Care?
Multi-Token Prediction is one of Qwen3.6’s secret weapons. Unlike standard next-token prediction, MTP allows the model to predict multiple future tokens simultaneously, think of it as architectural speculation that can dramatically boost inference speed when properly leveraged. The 15 preserved MTP components in this release include specialized weight tensors like mtp.fc.weight, mtp.layers.0.mlp.down_proj.weight, and mtp.layers.0.self_attn.k_proj.weight.
The preservation of these 15 MTP layers distinguishes this “heretic v2” release from previous uncensored models. While earlier attempts often destroyed or degraded these specialized components during fine-tuning, the MPOA (Magnitude-Preserving Orthogonal Ablation) method used here claims to maintain functional integrity while selectively ablating the alignment-conditioned vectors responsible for refusals.
Performance Metrics
| Metric | This Model | Original Qwen3.6-27B |
|---|---|---|
| KL divergence | 0.0021 | 0 (by definition) |
| Refusals | ✅ 6/100 | ❌ 92/100 |
| MMLU Accuracy | 85.67% | 86.65% |
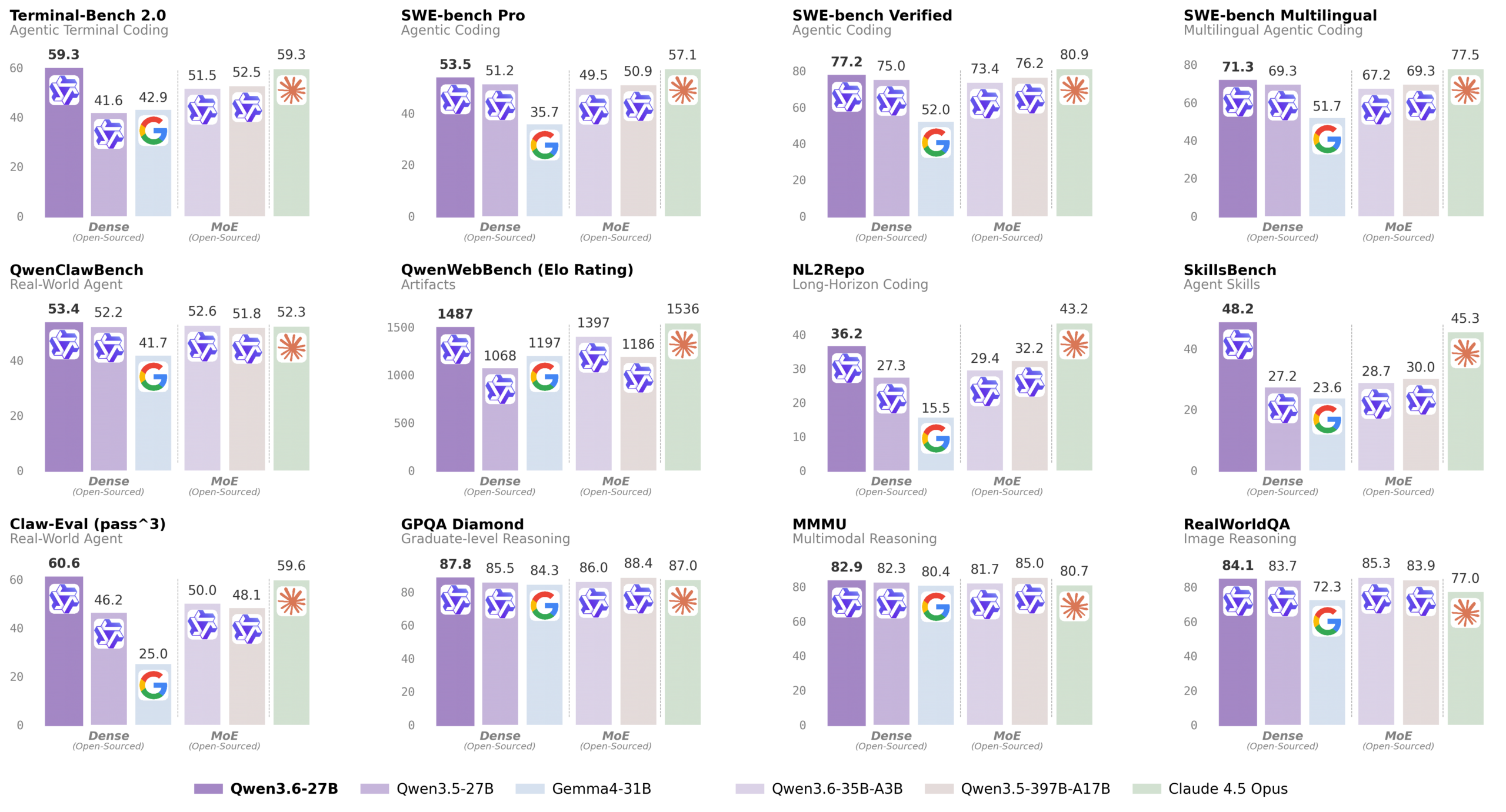
That’s a 94% reduction in refusals with only a 0.98 percentage point drop in MMLU performance. The uncensored model even beats the original in some practical coding benchmarks, scoring 53.5 vs 51.2 on SWE-bench Pro and 77.2 vs 75.0 on SWE-bench Verified.
The Quantization Arms Race: NVFP4 vs GGUF
What makes this release particularly interesting is the format war unfolding in the quantization space. The model is available in multiple flavors:
NVFP4 Versions
- Full NVFP4 quantization (smaller size, higher quality loss)
- NVFP4 MLP-only (bigger size, lower quality loss)
- NVFP4 GGUF format for compatibility with llama.cpp and LM Studio
Traditional Quantizations
- GGUF with standard K-quants (Q4_K_M, Q5_K_M, etc.)
- GPTQ Int4 and Int8 variants
- FP8-W8A16 for precision-conscious deployments
The community discussion around these formats reveals an ongoing tension between accessibility and performance. As one developer posted, frameworks like vLLM and SGLang now support MTP inference native, with vLLM requiring the command --speculative-config '{"method":"mtp","num_speculative_tokens":3}' to activate the feature. Meanwhile, hardware constraints remain brutal, 27B parameter models with MTP overhead struggle on 16GB VRAM setups, forcing users toward aggressive quantization or alternative architectures like Dflash with TurboQuant.
This quantization race mirrors the broader trend of distilled models stripped of safety guardrails for consumer hardware, where efficiency gains often come at the expense of corporate-imposed restrictions.
How the Abliteration Actually Works
The technical details buried in the model card reveal the surgical precision used. The ablation targeted three specific components:
– attn.o_proj
– attn.out_proj
– mlp.down_proj
Each had specific ablation parameters, like attn.o_proj.max_weight: 1.99 at position 48.06, that suggest a data-driven approach to identifying and modifying refusal vectors. This isn’t blanket fine-tuning, it’s targeted neuro-surgery on the model’s decision pathways.
Interestingly, the release includes both MTP-preserved and non-MTP versions, acknowledging that not all inference stacks support the feature yet. The Gemma2 MTP drama continues, with some community members pointing out that Google has already released MTP drafters for Gemma models, contradicting earlier assumptions about compatibility.

Real-World Performance: More Than Just Benchmarks
Beyond the MMLU scores lie more revealing metrics. The uncensored model maintains competitive performance across the full Qwen3.6 benchmark suite:
Coding Performance
- LiveCodeBench v6: 83.9 vs 80.7 for Qwen3.5-27B
- Terminal-Bench 2.0: 59.3 vs 41.6
- QwenWebBench: 1487 vs 1068
Vision-Language Tasks
- MMMU: 82.9 vs 82.3
- RealWorldQA: 84.1 vs 83.7
- VideoMME: 87.7 vs 87.0
The preservation of visual understanding capabilities alongside linguistic ones suggests the ablation didn’t indiscriminately damage multimodal pathways, a common failure mode in less sophisticated uncensoring attempts.
But performance isn’t everything. As Qwen Team exposing massive flaws in AI trusted tests reminded us, benchmarks can be misleading. The real test comes in deployment, where NVFP4 quantization enables running these models on consumer hardware that previously couldn’t handle 27B parameter models.
The Deployment Reality: Who Actually Can Run This?
Here’s where the rubber meets the road. Let’s look at practical deployment scenarios:
vLLM for MTP-enabled inference:
vllm serve Qwen/Qwen3.6-27B --port 8000 --tensor-parallel-size 8 \
--max-model-len 262144 --reasoning-parser qwen3 \
--speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'SGLang configuration:
python -m sglang.launch_server --model-path Qwen/Qwen3.6-27B --port 8000 \
--tp-size 8 --mem-fraction-static 0.8 --context-length 262144 \
--reasoning-parser qwen3 --speculative-algo NEXTN \
--speculative-num-steps 3 --speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4The community discussion reveals practical constraints. As noted in forum conversations, running a 27B model with MTP overhead on 16GB VRAM pushes hardware to its limits, leading to creative workarounds like NVFP4 quantization for MLP-only layers while keeping attention at higher precision.
The Uncensored Landscape: Supply vs Ethics
This release exists in a grey ethical zone. On one hand, it represents technical excellence, preserving architectural features while removing constraints. On the other, it contributes to an ecosystem where tools dismantling safety guardrails while preserving intelligence become increasingly sophisticated.
The model maintainer acknowledges the tension with a donation plea: “🚨⚠️ I HAVE REACHED HUGGING FACE’S FREE STORAGE LIMIT ⚠️🚨 I can no longer upload new models unless I can cover the cost of additional storage.” This isn’t corporate-backed research, it’s independent work pushing technical boundaries without institutional support.
The parallel with recent open-weight model censorship and real-world performance gaps is striking. Both represent communities optimizing for different values, some prioritize safety alignment, others prioritize utility and ease of use.
Practical Implications for Developers
For engineers considering deployment:
- MTP support is framework-dependent: As of May 2026, vLLM and SGLang have native support, while older frameworks may ignore or break these layers.
- Quantization choice matters: NVFP4 shows promising efficiency but requires NVIDIA Blackwell or newer hardware for optimal performance. GGUF remains the universal fallback.
- Memory is everything: The 27B model with 262K context requires careful memory management. NVFP4 reduces model size by approximately 3.3x but may impact certain types of reasoning.
- The guardrail gap: With refusals dropping from 92% to 6%, consider what filtering you’ll implement upstream before exposing this to end-users.
Where This Is Heading
The release represents a milestone in the ongoing arms race between safety engineers and jailbreak researchers. Each side develops more sophisticated techniques, MPOA ablation versus constitutional fine-tuning, speculative decoding versus refusal training.
What’s particularly fascinating is how quantization formats are becoming a battleground. NVFP4 isn’t just a storage format, it’s a performance characteristic that determines what hardware can run which models. The community release includes both pure NVFP4 and mixed-precision variants, acknowledging that some applications tolerate different types of quality loss.
As one community member noted about the 16GB VRAM struggle, “We choose to run cutting edge AI models in 16GB VRAM GPUs in this year and do the other things, not because they are easy, but because they are hard!” This sentiment captures the DIY spirit driving much of this development, pushing consumer hardware beyond what manufacturers intended.
The uncensored Qwen3.6-27B with preserved MTPs represents several converging trends:
– Sophisticated model editing that preserves architecture while modifying behavior
– Aggressive quantization enabling previously impossible local deployments
– Community-driven development outside corporate control structures
– Specialized hardware optimization (NVFP4 for Blackwell, GGUF for everything else)
Whether this represents progress or peril depends on your perspective. But technically, it’s undeniably impressive, a 27B parameter model that refuses less than most uncensored 7B models while retaining sophisticated architectural features. The quantization options mean you can run it somewhere, whether on cutting-edge data center GPUs or last-gen consumer cards with aggressive compression.
The files are on Hugging Face. The benchmarks suggest it works. The community will now decide what to build with it.



