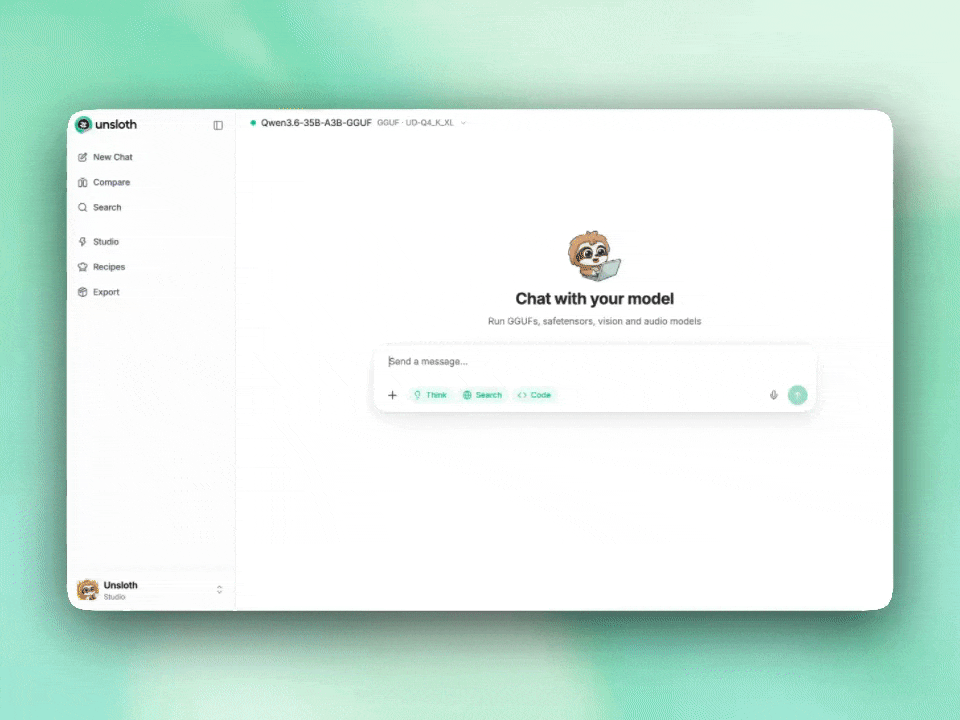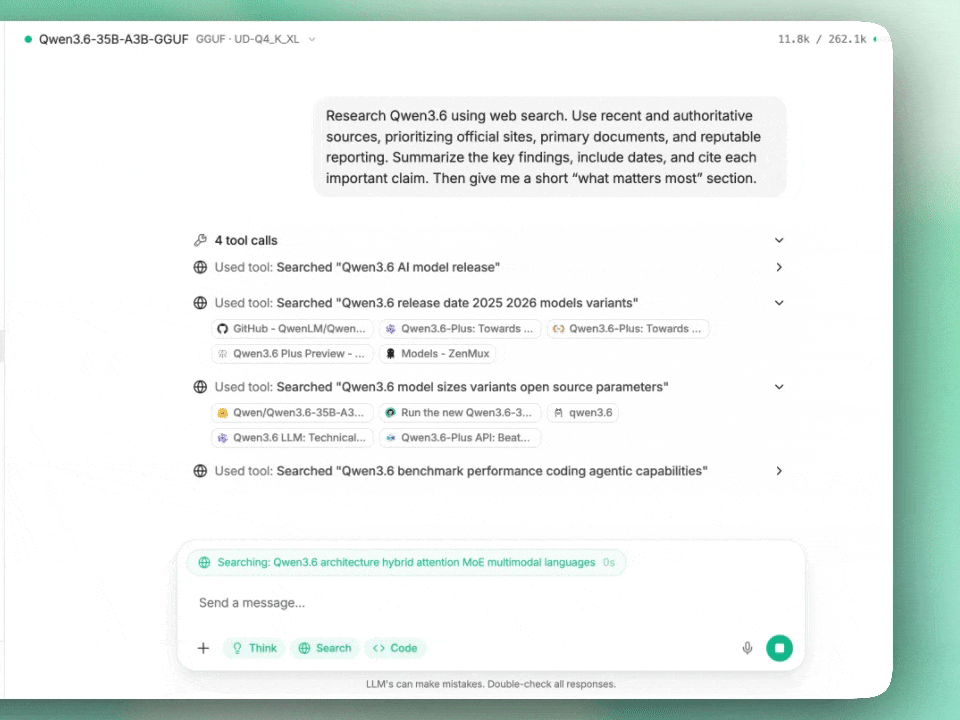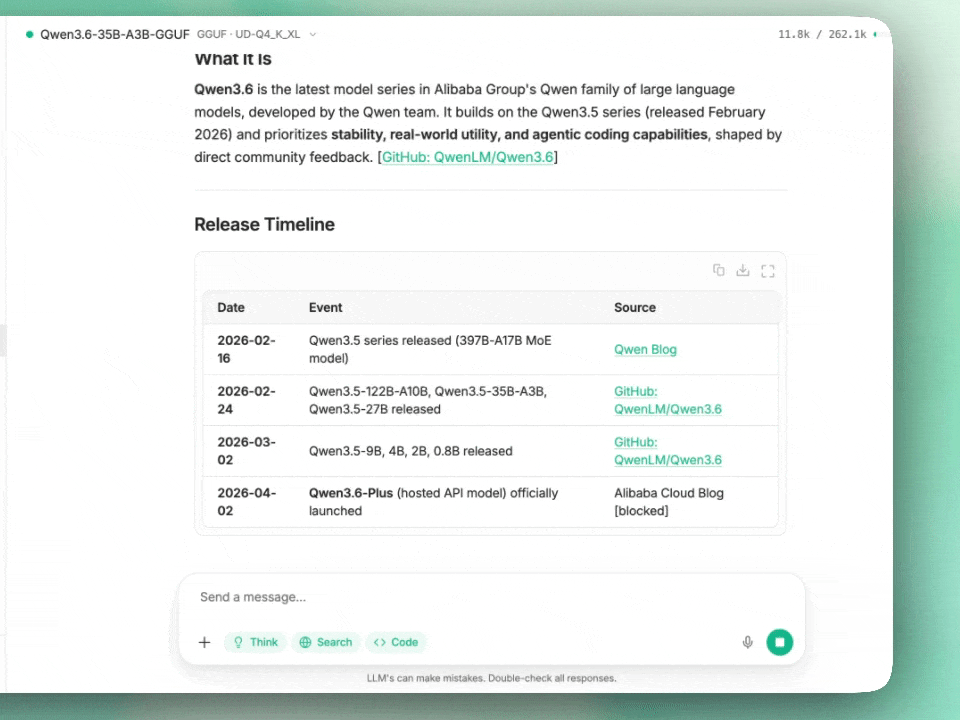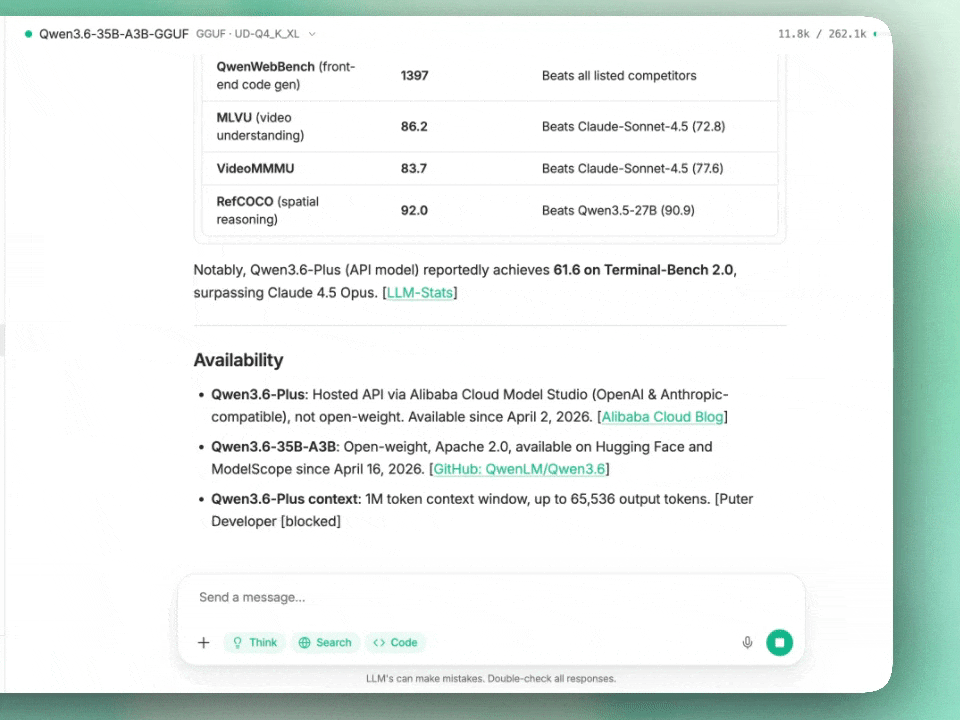
3 Billion Active Parameters Just Challenged 30 Billion: Inside Qwen3.6’s Sparse MoE
Qwen3.6-35B-A3B landed on Hugging Face with an Apache 2.0 license and a swagger that suggests the Qwen team knows something the rest of the industry is still figuring out. Released barely two months after the Qwen3.5 series, this isn’t an incremental refresh—it’s a surgical strike at the assumption that bigger (and actively used) parameters always equal better performance.
The Architecture: Gated DeltaNet Meets 256 Experts
Let’s get specific about what makes this model tick. Qwen3.6-35B-A3B employs a sparse MoE architecture with a hidden layout of 10 × (3 × (Gated DeltaNet → MoE) → 1 × (Gated Attention → MoE)). Translation: it stacks Gated DeltaNet layers with MoE routing, punctuated by Gated Attention blocks, also routed through experts.
This isn’t your standard transformer. The Gated DeltaNet component uses linear attention with 32 heads for values and 16 for query/key pairs, while the Gated Attention blocks employ 16 query heads and just 2 key/value heads—a configuration that screams “memory efficiency” over brute force.

Benchmark Reality Check: Coding Agents & The Efficiency Gap
The headline numbers suggest Qwen3.6 is punching well above its weight class. On SWE-bench Verified, the gold standard for agentic coding, the model scores 73.4, approaching the 75.0 scored by the dense Qwen3.5-27B while crushing Gemma4-31B’s 52.0. Even more impressive is Terminal-Bench 2.0, where Qwen3.6 hits 51.5 compared to its predecessor’s 40.5 and Gemma4-26B-A4B’s 34.2.
| Benchmark | Qwen3.5-27B (Dense) | Gemma4-31B | Qwen3.5-35B-A3B | Qwen3.6-35B-A3B |
|---|---|---|---|---|
| SWE-bench Verified | 75.0 | 52.0 | 70.0 | 73.4 |
| Terminal-Bench 2.0 | 41.6 | 42.9 | 40.5 | 51.5 |
| SkillsBench Avg5 | 27.2 | 23.6 | 4.4 | 28.7 |
| NL2Repo | 27.3 | 15.5 | 20.5 | 29.4 |
But here’s where it gets spicy. Some developer forums noted that Qwen3.6-35B-A3B actually loses to the dense Qwen3.5-27B on several standard benchmarks like MMLU-Pro (tied at 85.2) and certain reasoning tasks. The model isn’t universally better—it’s strategically better at agentic workflows and coding tasks that require tool use and repository-level reasoning.
This selective competence aligns with established MoE architectural lineage within the Qwen series, suggesting Alibaba is optimizing for specific production workloads rather than benchmark averages.
Thinking Preservation & The Agentic Edge
Qwen3.6 introduces a feature that sounds mundane but changes the economics of long-running agents: Thinking Preservation. By default, LLMs discard their reasoning traces after each turn. Qwen3.6 can retain these thinking blocks across conversation history, reducing token consumption in iterative development scenarios and improving KV cache utilization.
Key Benefits
- Reduced token consumption in iterative development
- Improved KV cache utilization
- Support for both “thinking” and “non-thinking” modes
- Switchable via API parameters
- Specific optimizations for MCP tool use
For agentic coding, where function calling reliability is make-or-break, this matters.
The vision capabilities also deserve scrutiny. Qwen claims RealWorldQA scores of 85.3 against Claude Sonnet 4.5’s 70.3, a suspiciously wide gap that suggests either superior multimodal training data or benchmark-specific optimization. On MMMU (multimodal reasoning), it edges out Sonnet 4.5 81.7 to 79.6, while maintaining competitive performance on document understanding benchmarks like OmniDocBench1.5 (89.9).
Running It Locally: The Unsloth Reality
The 3B active parameter count isn’t just marketing fluff—it’s a deployment cheat code. While 96GB VRAM has become the new minimum for competitive local agentic coding, Qwen3.6’s sparse activation allows for aggressive quantization without the usual quality collapse.
Unsloth has already released GGUF variants ranging from 10GB (1-bit) to 22GB (4-bit), with the 4-bit UD-Q4_K_M sitting at a manageable 22.1GB, feasible on a single 4090 with some system RAM offloading. For those with consumer hardware, this represents a genuine alternative to API-dependent workflows.
The model supports SGLang, vLLM, and KTransformers out of the box, with specific optimizations for multi-token prediction (MTP) that can further accelerate inference. For practical local deployment on consumer hardware, the community has already begun integrating it into llama.cpp and similar frameworks.
The Apache 2.0 Elephant in the Room
Why This License Matters
Here’s what makes this release genuinely disruptive: the license. Apache 2.0 means commercial use, modification, and redistribution without the legal anxiety of custom “open” licenses that reserve hidden clauses. In a landscape where even “open” weights often come with usage restrictions, Qwen3.6’s licensing is refreshingly permissive.
This creates a direct challenge to closed-weight models like Claude Sonnet 4.5 and GPT-4.1. When a 3B-active-parameter model can approach 70B-parameter performance on coding tasks while running locally on consumer hardware, the economics of AI inference shift dramatically.
The Verdict: Efficiency or Illusion?
Strengths
- Agentic coding parity with 10x larger models
- Apache 2.0 license enables commercial flexibility
- Runs on consumer hardware with 24GB VRAM
- Superior specialized performance metrics
- Thinking preservation for long-running agents
Considerations
- Not universally better across all benchmarks
- Sacrifices general reasoning vs dense models
- More like 3-5x efficiency than claimed 10x
- Still evolving ecosystem around the model
Bottom Line
Qwen3.6-35B-A3B isn’t a universal upgrade. It sacrifices some general reasoning capabilities found in dense 27B models to double down on agentic coding and multimodal workflows. But that’s precisely the point—MoE architectures allow for specialization without paying the inference cost of generalist models.
Alibaba isn’t just releasing models—they’re releasing pressure on the closed-source ecosystem. Whether this specific checkpoint becomes the new standard or merely a stepping stone to Qwen3.6-122B, the message is clear: the parameter arms race is over. The efficiency war has begun.