Alibaba didn’t release Qwen3.5 on a Tuesday afternoon because it was convenient. They dropped a 122-billion-parameter Mixture-of-Experts model while Western AI labs were still processing their morning coffee, and the message couldn’t be clearer: the open-weight gap is closed, and China is playing offense.
The Qwen3.5 series, spanning from the nimble 27B dense model to the behemoth 122B-A10B MoE variant, isn’t just incremental progress. It’s a surgical strike at the heart of closed-source AI economics. While OpenAI and Anthropic continue to gatekeep their best models behind API pricing that scales linearly with your ambition, Alibaba is essentially giving away the keys to a Ferrari and saying, “Good luck with your Honda payments.”
The 3 Billion Parameter Punch That Hits Like 235 Billion
Here’s where things get spicy. The Qwen3.5-35B-A3B model activates only 3 billion parameters during inference. That’s not a typo. Three billion. And it outperforms the previous generation’s Qwen3-235B-A22B model, which activated 22 billion parameters.
Let that sink in. We’re witnessing a 7x improvement in parameter efficiency in a single generation. The MoE architecture isn’t just a cute optimization trick anymore, it’s become a weapon of mass disruption. The model intelligently routes queries to specialized expert sub-networks, meaning you’re not paying the computational tax of a dense model’s full parameter count.
The architectural cocktail is equally clever: hybrid Gated Delta Networks (linear attention) blended with standard Gated Attention blocks. This isn’t academic navel-gazing, it translates to higher throughput decoding and a memory footprint that doesn’t require a second mortgage on a DGX H100 cluster.

The Memory Footprint Reality Check
Let’s talk about what it actually takes to run these models because the Hugging Face comments section is already a graveyard of out-of-memory errors.
The 122B-A10B model at 4-bit quantization: 122 billion parameters × 4 bits ÷ 8 bits/byte = 61 GB. That’s before you factor in KV cache, activation memory, or the fact that your operating system also wants to exist. Want to run it at full FP16 precision? You’re looking at 244 GB just for the weights.
Community members on NVIDIA’s forums are already scrambling to optimize. One developer noted that even the 27B model’s first quantization attempts produced a 30GB file, suggesting either massive activation weights or quantization artifacts. The race for FP8 and NVFP4 quants is on, with Red Hat AI already shipping a FP8 dynamic variant of the even larger Qwen3.5-397B-A17B model.
The deployment command floating around chat rooms looks deceptively simple:
vllm serve Qwen/Qwen3.5-27B --port 8000 --max-model-len 262144 --reasoning-parser qwen3 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'But then reality hits: transformers v5 compatibility issues, llm-compressor import errors for TORCH_INIT_FUNCTIONS, and the eternal dance of dependency hell. As one developer lamented, “Every version of everything I install is wrong for the chipset.”
The 1M Context Window That Makes RAG Architects Nervous
Qwen3.5-Flash ships with a 1-million-token context window by default. That’s not a flex, it’s a strategic obsolescence of an entire industry segment. Companies have built million-dollar businesses around vector databases, chunking strategies, and RAG orchestration pipelines. Qwen just said, “What if you just… put it all in the prompt?”
This isn’t context stuffing, it’s context absorption. The model can ingest entire code repositories, legal contracts, or research paper collections without breaking a sweat. For developers building agentic workflows, this means your “retrieve” step can be replaced with a simple file read operation. The architectural implications are massive: simpler systems, fewer failure points, and latency that doesn’t depend on a vector search roundtrip.
The Qwen3.5-122B-A10B model, despite activating only 10B parameters, maintains logical consistency across these massive contexts through a four-stage post-training pipeline involving long chain-of-thought cold starts and reasoning-based reinforcement learning. This isn’t just scaling up, it’s scaling smart.
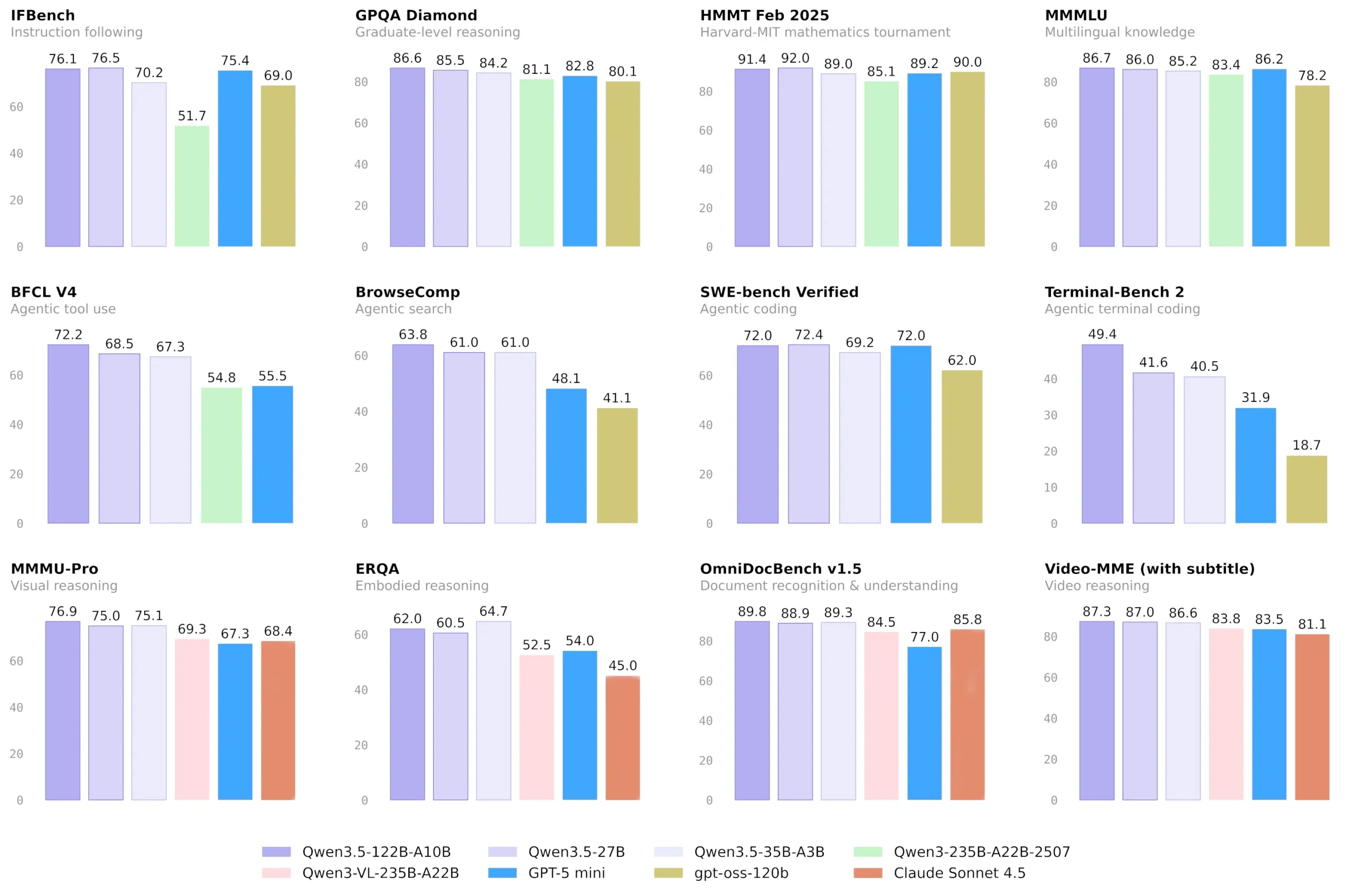
The Closed-Source Performance Gap Just Evaporated
Here’s where the controversy ignites. Alibaba claims these models “narrow the gap between open-weight alternatives and proprietary frontier models.” That’s corporate understatement. Based on early community benchmarks and the Qwen3.5-397B-A17B performance, we’re looking at models that match or exceed GPT-4 class performance on standard benchmarks.
The strategic implications are seismic. While US companies hoard their best models, China is systematically open-sourcing frontier-level AI. This isn’t altruism, it’s economic warfare. Every startup that chooses Qwen3.5 over GPT-4 is one less customer funding OpenAI’s compute budget. Every enterprise that self-hosts Qwen is one less data stream feeding Anthropic’s constitutional AI pipeline.
The release timing, coinciding with Lunar New Year, feels less like a celebration and more like a coordinated strike. While Western labs were winding down, Alibaba’s engineers were uploading what amounts to a complete AI stack.
Community War Stories: When Theory Meets PCIe Bandwidth
The NVIDIA developer forums reveal the messy reality of deploying these models. Developers are pushing llm-compressor to its limits, wrestling with quantization artifacts, and debating whether MXFP6 can squeeze the 122B model onto a single DGX Spark.
One developer’s error log tells the whole story:
ImportError: cannot import name 'TORCH_INIT_FUNCTIONS' from 'transformers.modeling_utils'The solution? Downgrade transformers, wait for official FP8 quants, or pray that unsloth & Co. ship a GGUF before your GPU melts. The community is already building entire orchestration layers around these models, with sparkrun.dev integrating Qwen3.5-35B into their default recipes.
The consensus? Wait for the quants. The models are too large, too new, and too hungry for vanilla deployment. But once FP8 and NVFP4 variants land, the barrier to entry drops dramatically.
The “Goldilocks Zone” Strategic Play
Alibaba’s model sizing is deliberate. By focusing on the 27B to 122B parameter range (with 3B-10B active), they’re targeting what they call the “sweet spot”, models small enough to run on private infrastructure but capable enough to replace closed-source behemoths.
This is the anti-OpenAI playbook. Instead of centralizing AI behind APIs, they’re decentralizing it, making frontier intelligence accessible to anyone with a few high-end GPUs. The Qwen3-Max release showed they can play the trillion-parameter game. Qwen3.5 shows they can win the war of accessibility.
The implications for AI safety, governance, and geopolitical competition are profound. When frontier AI becomes a downloadable weight file, control shifts from model developers to model deployers. The conversation changes from “Can we build it?” to “Should we run it?”, and that “should” becomes a lot harder to enforce.
What This Means for Your AI Strategy
If you’re still building on closed APIs, you’re now paying a premium for lock-in that no longer delivers a performance advantage. The Qwen3.5-397B-A17B challenger already proved open-weight models can compete with GPT-5 class systems. Qwen3.5 makes that capability accessible.
For developers, the path forward is clear:
1. Start with Qwen3.5-Flash for production workloads requiring low latency
2. Use 35B-A3B for cost-effective reasoning tasks that punch above their weight
3. Deploy 122B-A10B for complex agentic workflows where consistency matters
4. Wait for FP8/NVFP4 quants before attempting local deployment of the larger models
The era of “open-weight models are good enough” is over. We’re now in the “open-weight models are better” era, better for privacy, better for cost, better for control, and increasingly, better for raw performance.
The question isn’t whether closed-source AI can maintain its lead. The question is how long until the market realizes the lead has already evaporated.

The bottom line: Alibaba just turned open-weight AI from a hobbyist curiosity into a strategic weapon. The performance gap is closed. The cost gap is laughable. The only gap remaining is the one in Western AI strategy that let this happen while everyone was watching the wrong benchmarks.
Explore how Qwen3-Coder-Next is blurring the lines between specialized and general-purpose models and dive into the benchmark controversies that are reshaping AI evaluation.



