The AI safety establishment wants you to believe that model censorship is an inseparable feature of intelligence. That a guardrail-less LLM is a dangerous toy, not a tool.
Then a user named llmfan46 released Qwen3.5-35B-A3B-uncensored-heretic-v2-Native-MTP-Preserved on Hugging Face, and the entire premise shattered.
The numbers are stark: the original Qwen3.5-35B-A3B refuses 92 out of 100 “unsafe” prompts. The “heretic” version refuses only 14. That’s an 85% reduction in refusals, achieved with a KL divergence of just 0.0487 and an MMLU accuracy drop from 84.12% to 83.72%. A 0.4% hit to general knowledge for an order-of-magnitude collapse in censorship.
This isn’t a lobotomized model. It’s the same brain, just without the handcuffs.
The XDA ROMs of AI
The Reddit reaction to this release was immediate and telling. The top comment, with nearly 200 upvotes, summed it up perfectly: “We are reaching XDA Android Custom Roms titles with this one.”
The comparison isn’t just funny, it’s precise. The thread rapidly descended into nostalgic memes about the 2010s custom ROM era: “Working: boots, lock screen, finger print scanner. Not working: WiFi, phone calls, data connection, everything else.” Another commenter nailed the cultural shift: “The 2010s android rom devs are graduating into training models now.”
This is the bleeding edge of open-source LLM culture meeting the ethos of device liberation. The same impulse that drove people to root their phones, flash kernels, and chase the perfect battery life is now driving people to surgically remove refusal vectors from transformer weights.
And the model name structure itself, Qwen3.5-35B-A3B-uncensored-heretic-v2-Native-MTP-Preserved, is a perfect artifact of this world. It reads like a lineage. A version history. A promise of craftsmanship.
What MPOA Actually Does to Model Weights
The technical approach here is anything but crude. The model is a “decensored” version created using Heretic v1.3.0 with a variant of Magnitude-Preserving Orthogonal Ablation (MPOA). It targets three specific component types: attn.o_proj, attn.out_proj, and mlp.down_proj.
This is surgical, not destructive. The ablation modifies specific projection matrices that encode refusal behavior, without scrambling the broader cognitive architecture. The result is a model that retains reasoning, knowledge, and coherence, but loses the pathological need to lecture or deflect.
The benchmarks bear this out across 57 MMLU subjects:
| Subject | Original | Heretic | Delta |
|---|---|---|---|
| professional_law | 0.7274 | 0.7185 | -0.89% |
| moral_scenarios | 0.7195 | 0.6471 | -7.24% |
| elementary_mathematics | 0.7880 | 0.8098 | +2.18% |
| high_school_us_history | 0.9579 | 0.9684 | +1.05% |
| virology | 0.5281 | 0.5169 | -1.12% |
| college_mathematics | 0.7455 | 0.7636 | +1.81% |
Notice that moral_scenarios took the biggest hit, a 7.24% drop. That’s exactly what you’d expect when removing safety-oriented weight modifications. The model is less concerned with moral posturing, which impacts its performance on explicitly moral reasoning benchmarks. For most practical use cases, that’s a feature, not a bug.
The MTP Question Nobody’s Asking
The full model name includes a specific claim: “Full 785 MTPs Preserved and Retained.”
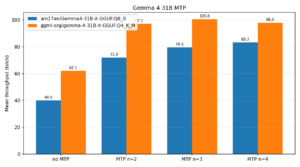
MTP stands for Multi-Token Prediction, a speculative decoding technique where the model predicts multiple future tokens simultaneously rather than one at a time. It’s a key performance optimization in Qwen3.5’s architecture, and it’s notoriously fragile during ablation. Earlier uncensored variants of Qwen3.6 models had to sacrifice MTP entirely to achieve stable uncensoring.
The creator explains the distinction clearly: “For Qwen3.6 usually a KL divergence in the 400’s+ could very well indicate a disastrous loss of accuracy and quality of the model.” A Qwen3.6 model with a KL of just 0.0015 lost 0.32% accuracy. The 3.5 heretic achieves a 0.0487 KL with only a 0.40% accuracy loss.
This isn’t a detail. It’s the entire point. MTP preservation means this uncensored model can be used as a drop-in replacement in production inference pipelines without re-engineering the entire speculative decoding stack. You can serve it with SGLang using the exact same MTP configuration:
python -m sglang.launch_server --model-path llmfan46/Qwen3.5-35B-A3B-uncensored-heretic-v2-Native-MTP-Preserved --port 8000 --tp-size 8 --mem-fraction-static 0.8 --context-length 262144 --reasoning-parser qwen3 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
The performance benefit of MTP is not trivial. In production environments, speculative decoding can yield 2-3x throughput improvements over standard autoregressive generation. Preserving that capability in an uncensored variant is a significant engineering achievement.
Why Qwen3.5, Not Qwen3.6?
One of the most frequently asked questions on the Hugging Face model page gets directly addressed by the creator: Why release a Qwen3.5 MTP version when Qwen3.6 MTP already exists?
The answer reveals the nuanced landscape of model lineages. Despite both models using the qwen35 architecture, they were trained for fundamentally different use cases:
- Qwen3.6: Optimized for agentic and coding AI assistance
- Qwen3.5: Optimized for general-purpose AI assistance
As the creator puts it: “If you want the most optimal usecases it would be Qwen3.6 for agentic and coding and Qwen3.5 for general AI assistance, that is where each of them excels at.”
This distinction matters for the uncensored community. A general-purpose model stripped of refusals is a general-purpose tool. A coding model stripped of refusals is a more specialized, and arguably more dangerous, instrument. The 3.5 variant occupies a broader utility space, making it more immediately useful for the average power user who wants an unrestricted conversational AI.
The Infrastructure of Freedom
The release is notable not just for what it removes, but for what it includes. The model is available in five distinct format families:
- Safetensors (full precision) via
llmfan46/Qwen3.5-35B-A3B-uncensored-heretic-v2-Native-MTP-Preserved - GGUFs across 9 quantization levels from BF16 down to Q3_K_M via
llmfan46/Qwen3.5-35B-A3B-uncensored-heretic-v2-Native-MTP-Preserved-GGUF - NVFP4 (Experts-Only quantization) via
llmfan46/Qwen3.5-35B-A3B-uncensored-heretic-v2-Native-MTP-Preserved-NVFP4 - NVFP4 GGUFs with BF16 and Q8_0 variants via
llmfan46/Qwen3.5-35B-A3B-uncensored-heretic-v2-Native-MTP-Preserved-NVFP4-GGUF - GPTQ-Int4 via
llmfan46/Qwen3.5-35B-A3B-uncensored-heretic-v2-Native-MTP-Preserved-GPTQ-Int4
This isn’t just thoroughness. It’s strategic. Different quantization formats serve different hardware ecosystems. GGUFs run on consumer GPUs via llama.cpp and Ollama. NVFP4 runs on NVIDIA hardware with model optimization toolkits. GPTQ-Int4 provides a middle ground for GPU-constrained environments. Each format removal of a barrier to entry. Each deployment option a potential new user.
The comment thread on the release shows this in action. One user explicitly thanked the creator: “Thanks for the NVFP4 GGUF version. I seriously can’t find anyone else doing that, not even Unsloth.” The creator’s response: “Welcome!” Short, human, and entirely unpretentious.
The Free Storage Limit Warning
Scrolling past the performance metrics and quantization tables, a stark warning sits in bold: “I HAVE REACHED HUGGING FACE’S FREE STORAGE LIMIT ⚠️🚨”
The creator hosts 70+ free models as an independent contributor. They note plainly: “This work is unpaid. Without your support, no more new models can be uploaded.”
This is the reality of open-source LLM development at the frontier. The people doing the most technically interesting and culturally significant work, removing guardrails, preserving capabilities, shipping production-ready quantizations, are individuals without institutional backing. They’re paying for storage out of pocket, running compute on consumer hardware, and watching their Hugging Face model pages fill with praise while their storage quota runs dry.
The comment section reflects this tension. Multiple users express gratitude and note that the creator’s models consistently outperform other abliterated variants in benchmarking. The creator responds graciously: “Thank you for the kind words and yes it all takes a lot of time, but this is the way to release the best quality models.”
What This Means for the Open-Source Ecosystem
The existence of a high-quality, low-degradation uncensored Qwen3.5 model creates a precedent that the safety community has been dreading. The Qwen3.5 series launch and open-weight strategy from Alibaba was already a calculated geopolitical move. This heretic variant transforms that calculation.
Alibaba released Qwen3.5 under the Apache 2.0 license. They explicitly permitted commercial use, modification, and redistribution. They knew that uncensored variants would emerge. The question was whether those variants would be competent.
This one is.
The 3 billion active parameter MoE architecture that makes Qwen3.5 so efficient for its size is fully intact after ablation. The 96GB VRAM requirements for local agentic coding remain unchanged. The model works. It thinks. It reasons. It just doesn’t lecture.
The Ethics of Surgical Ablation

There’s an argument that releasing uncensored models is inherently irresponsible. That the guardrails exist for a reason. That 14 refusals out of 100 is still too many, or too few, depending on your perspective.
But the Heretic methodology challenges the premise that safety and capability are a single, inseparable dimension. MPOA demonstrates that refusal behavior is localized in specific weight matrices. It can be removed efficiently without degrading general intelligence. This implies that safety training is, at least partially, a distinct capability overlay rather than an emergent property of general intelligence.
That’s an uncomfortable conclusion for safety researchers who argue that alignment is inseparable from capability. The evidence here suggests otherwise. Remove the right projections, and the model stops moralizing without losing its ability to reason about morality.
The Qwen3.5-397B model at the top of the family would likely respond to ablation similarly. The challenge to closed-source dominance that these models represent isn’t just about performance parity. It’s about the right to modify, the freedom to choose, and the technical capacity to remove the parts you don’t want.
Qwen3.5-35B-A3B-uncensored-heretic-v2-Native-MTP-Preserved is not just a model. It’s a statement. It says that censorship is not a prerequisite for intelligence. That surgical removal of safety vectors is possible with minimal capability loss. That the open-source community will continue to push against guardrails as long as guardrails exist.
The 0.4% MMLU accuracy loss is the price of freedom. For most users, it’s a bargain.
The creator’s local deployment guides and llama.cpp integration instructions make this accessible to anyone with a GPU and a willingness to experiment. The GGUF quantizations mean you can run it on a single 24GB consumer card at Q4_K_M.
The 2010s custom ROM developers grew up. They learned to ablate transformers instead of kernels. And they’re shipping the most competent uncensored models the world has ever seen.
Whether that’s progress or chaos depends entirely on who’s asking the question.