The wait is over: PR #22673 has merged multi-token prediction (MTP) into llama.cpp master, giving local LLM inference a generational speed boost without requiring new silicon. Early benchmarks show Qwen3.6-27B jumping from roughly 38 to 65 tokens per second on consumer RTX 3090s, a 1.71× throughput gain, with no hardware swaps and no trickier quantization. But the celebration comes with caveats. Prompt processing speeds are taking a measurable hit, maximum context windows are shrinking, and llama-bench still has no idea MTP exists. Here is exactly what merged, how to enable it, and where the skeletons are buried.
the-merge-that-changed-the-decoding-math”>The Merge That Changed the Decoding Math
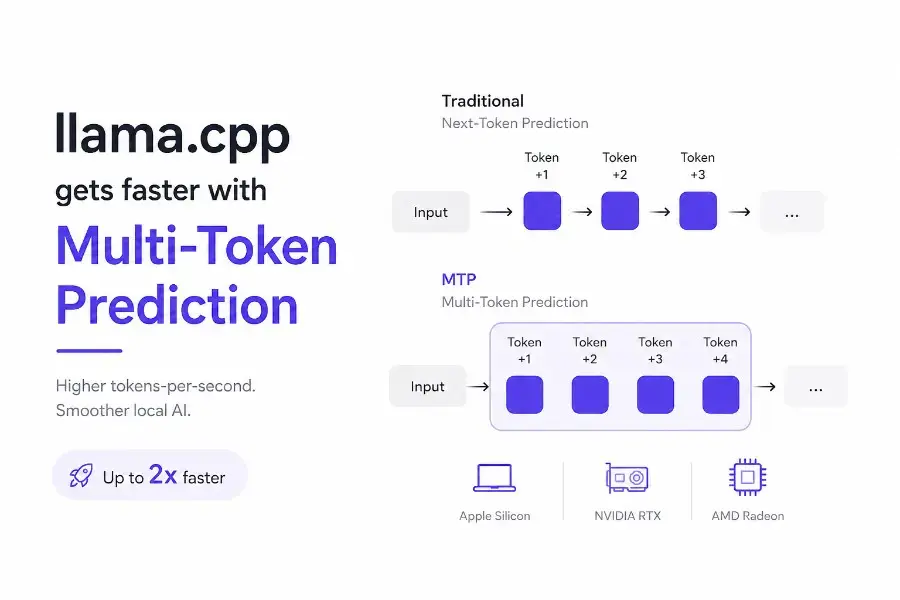
For years, the standard local inference pipeline has been brutally serial: predict one token, append it to the context, predict the next. Even on powerful GPUs, decoding latency piles up because memory bandwidth, not raw compute, is the bottleneck. MTP breaks that sequential lock by adding extra prediction heads to the model architecture itself. During a single forward pass, these heads forecast not just token +1, but tokens +2, +3, and +4. The main model then verifies those drafts in parallel, keeping the ones that match and falling back instantly on the first miss.
This is speculative decoding, but without the logistical headache of managing a separate draft model. Traditional speculative setups force you to juggle two GGUF files, keep vocabularies aligned, and burn extra VRAM on a secondary weights bundle. MTP folds the drafting capability into the same checkpoint. In the case of Qwen3.6, you point llama-server at one GGUF and you are done, there is no second mmap, no assistant model to warm up, and no topology mismatch to debug. That deployment simplicity is a big reason the architecture power shift via MTP drafters in Gemma 4 attracted so much attention before this merge even happened.

real-benchmarks-not-marketing-numbers”>Real Benchmarks, Not Marketing Numbers
Hype around inference speedups usually deflates the moment you try it on real hardware. MTP in llama.cpp is different because the gains are already reproducible on consumer cards.
A controlled DataCamp tutorial benchmarked Qwen3.6-27B Q4_K_M on a RunPod RTX 3090. Baseline generation sat at 38.86 tokens per second. After flipping on MTP with --spec-draft-n-max 3, throughput climbed to roughly 65 tokens per second. That is a 1.71× speedup, or about 71% higher generation throughput, with identical quantization and no TurboQuant patches layered on top.
Community testers are seeing similar deltas. One user running Unsloth’s MTP-enabled Qwen3.6-27B quant on a 22 GB RTX 2080 Ti reported generation doubling from 23 tok/s to 47 tok/s, again, purely from enabling the built-in MTP heads. Another fork, atomic-llama-cpp-turboquant, clocked +24, 36% tps on Qwen 3.6 35B-A3B MoE using NextN speculative decoding, and +5, 7% on the 27B dense variant. These are not cherry-picked peaks, they are sustained generation numbers on actual consumer hardware.
the-hidden-tax-on-prompt-processing”>The Hidden Tax on Prompt Processing
Token generation is only half the inference story. The other half is prompt processing (PP), the initial prefill pass that ingests your system prompt, chat history, and retrieved documents. And this is where MTP gets controversial.
The same merged implementation that accelerates decoding can slow down PP. Early feedback is already measurable: one tester saw PP drop from 1,100 tok/s to roughly 550 tok/s on an RTX 3090. On older silicon like the Tesla P40, the regression was from 250 tok/s down to 170 tok/s. Context capacity is also squeezed, some users report effective maximum context falling from around 150k tokens to roughly 110k before out-of-memory errors start biting.
For chatbots and short-prompt agents, that trade-off is invisible. But for coding copilots and RAG pipelines that routinely ingest 14k-token system prompts plus repository context, PP is often the dominant latency. LLM Studio and related wrappers will need to surface this clearly, because a 2× faster generation rate means little if you spend ten seconds stuck in prefill. The prevailing sentiment among local-AI developers is that the community has obsessed over token generation while under-investing in prompt processing speed. MTP unfortunately does not solve that problem, in some configurations, it makes it worse.
VRAM usage is also slightly higher. MTP-augmented models carry additional prediction heads, so the checkpoint is marginally larger and runtime memory pressure ticks up. If you are already riding the edge of your GPU’s capacity with a Q4_K_M quant and a massive KV cache, expect tighter margins.
what-you-actually-need-to-run-it”>What You Actually Need to Run It
Despite the complexity under the hood, enabling MTP on llama.cpp requires exactly two new flags appended to your normal server or CLI invocation:
./llama-server \
-m /path/to/Qwen3.6-27B-Q4_K_M-mtp.gguf \
--spec-type mtp \
--spec-draft-n-max 3 \
-ngl 99 \
-c 100000 \
--cache-type-k q8_0 \
--cache-type-v q8_0
The --spec-type mtp switch tells the engine to use the model’s own MTP layers for speculative drafting. --spec-draft-n-max 3 caps the draft lookahead at three tokens, which is the sweet spot for Qwen3.6 in early testing. You do not need a separate draft model, the same weights serve both target and drafter roles.
Model support is currently led by the Qwen3.6 family, with purpose-built MTP GGUFs already on Hugging Face. An uncensored Qwen3.6 model with MTP layers preserved via orthogonal ablation has also surfaced, proving the technique survives community fine-tuning. Gemma support is not yet in mainline llama.cpp at the time of writing, though community expectations point to it arriving soon, vLLM already handles Gemma MTP if you need it today.
Vision input, tensor parallelism, and pipeline parallelism are all compatible with this merge, and the implementation even functions with CPU offloading. Developers have confirmed decent gains on CPU-only or partially-offloaded setups because the speedup targets memory-bandwidth-constrained decoding, which affects integrated and discrete silicon alike.
One tooling gap remains: Issue #22947 notes that llama-bench does not yet recognize the --spec-type or --spec-draft-n-max flags. If you want rigorous A/B testing today, you will need custom scripts or llama-server metrics endpoints rather than the built-in benchmarking binary.
stacking-optimizations-and-the-road-ahead”>Stacking Optimizations and the Road Ahead
Where things get spicy is layering. The community has already started combining MTP with TurboQuant and other KV-cache compression schemes to claw back the VRAM lost to those extra prediction heads. One warning buried in the advanced configuration docs flags the combination of MTP and ngram-* speculative modes as experimental, particularly on NVIDIA CUDA systems, because accuracy and stability can degrade when two drafting mechanisms fight for the same verification pipeline.
This merge also unblocks work that was sitting behind it. The Eagle3 PR, another speculative-decoding architecture promising even larger speedups, was on hold pending this MTP refactor. With the underlying speculative-parallel plumbing now in master, Eagle3 is expected to merge quickly, which means the 1.7× gain we see today may be a floor, not a ceiling.
The broader context is that pure runtime optimization, quantization, Flash Attention, custom CUDA kernels, is no longer enough. The models themselves are being redesigned for inference efficiency. That trend is exactly why llama.cpp MTP beta bridging the gap with vLLM via Medusa-style support matters so much: the gap between “easy local deployment” and “production-grade speed” is collapsing into a single binary.
reality-check-mtp-is-not-magic”>Reality Check: MTP Is Not Magic
Acceptance rates matter. MTP only accelerates output when the drafted tokens pass verification. Highly repetitive, structured workloads, code generation, JSON templating, predictable prose, see the best acceptance rates and therefore the highest speedups. Free-form creative writing with high entropy will see slimmer gains because drafts get rejected earlier.
And while Ollama users on tight 8 GB cards like the RTX 4060 are reporting that MTP helps maximize limited VRAM bandwidth, the physical memory ceiling does not disappear. A 27B parameter model running at Q4_K_M still needs to fit. If your workflow relies on 150k+ context windows, the current memory and PP regressions may push you toward smaller quants or shorter prompts.
MTP in llama.cpp is a genuine inflection point for local inference. Generation speed gains of 70% or more, on existing hardware, using two command-line flags, are not common. For interactive chat, coding assistants, and low-concurrency agent workloads, the responsiveness improvement is immediate and tangible.
But treat it as a scalpel, not a hammer. Measure your prompt processing latency before and after. Watch your peak context length. Verify that your chosen model actually ships MTP heads, otherwise those flags do nothing, and keep an eye on upstream as Eagle3 and expanded Gemma support arrive. Local AI just took a major step forward, just make sure your workflow is in the generation-heavy camp before you celebrate.



