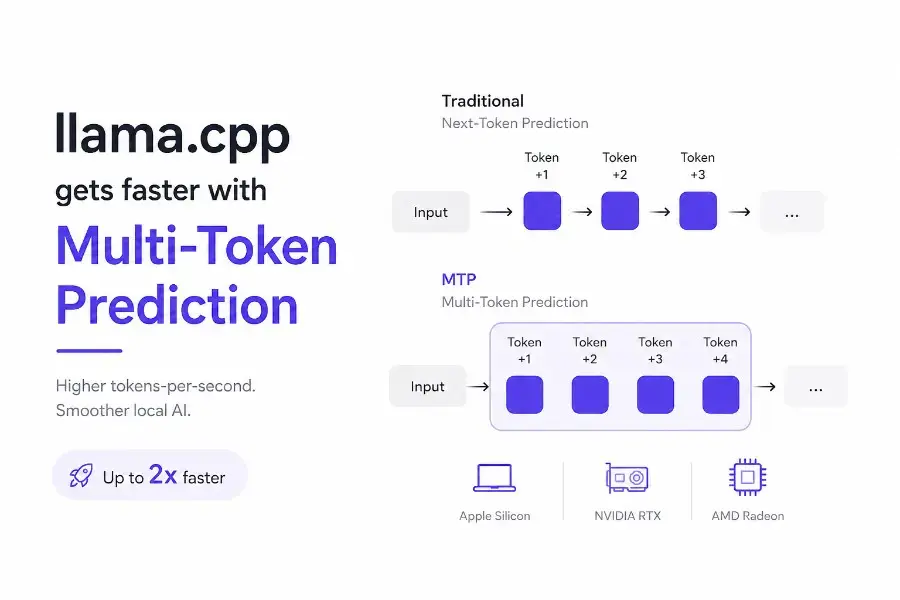
Multi-Token Prediction Lands in llama.cpp: Nearly 2× Faster Generation, but Prompt Processing Is Paying the Price
MTP support is now in llama.cpp mainline, delivering up to 71% faster token generation for local models. We break down the benchmarks, the prompt processing trade-offs, and how to actually enable it.