The AI inference world has a new speed demon, and it didn’t come from a startup with a wafer-scale chip or a billion-dollar custom ASIC. Xiaomi, in collaboration with the TileRT systems team, just dropped MiMo-V2.5-Pro-UltraSpeed, a 1-trillion-parameter model that cranks out over 1000 tokens per second. On eight standard GPUs.
Let that sink in. A trillion parameters. A thousand tokens per second. Commodity hardware.

This isn’t just a benchmark flex. It’s a fundamental rethinking of how you push a model that big, that fast, through silicon that wasn’t designed for it. The industry’s usual playbook for extreme speed, Cerebras’s wafer-scale integration or Groq’s SRAM-only compute, involves building your own hardware. Xiaomi and TileRT took a different path: they bent the software and model architecture until the hardware had no choice but to comply.
The Three Pillars of the Impossible
Hitting 1000 TPS on a 1T MoE model isn’t one breakthrough. It’s three breakthroughs stacked on top of each other, each one solving a bottleneck that would otherwise cap throughput at a fraction of this speed.
1. FP4 Quantization: Squeezing the Model Until It Fits
The first problem with a trillion-parameter model is simple physics: those parameters take up a lot of memory. Even at FP8, a 1T model requires roughly 1 TB of memory just for the weights. Moving that much data across the PCIe bus and through the memory hierarchy is the dominant bottleneck in inference.
The obvious answer is to use fewer bits per parameter. FP4 (MXFP4 format) cuts the memory footprint in half compared to FP8. The not-so-obvious answer is that applying FP4 uniformly across the entire model destroys accuracy, especially on complex reasoning and code generation tasks.
Xiaomi’s insight was beautifully pragmatic: don’t quantize everything. In a Mixture of Experts architecture, the experts account for the vast majority of parameters (and are the most tolerant to reduced precision). So they quantized only the MoE experts to FP4, leaving everything else, attention mechanisms, projections, the works, at higher precision.
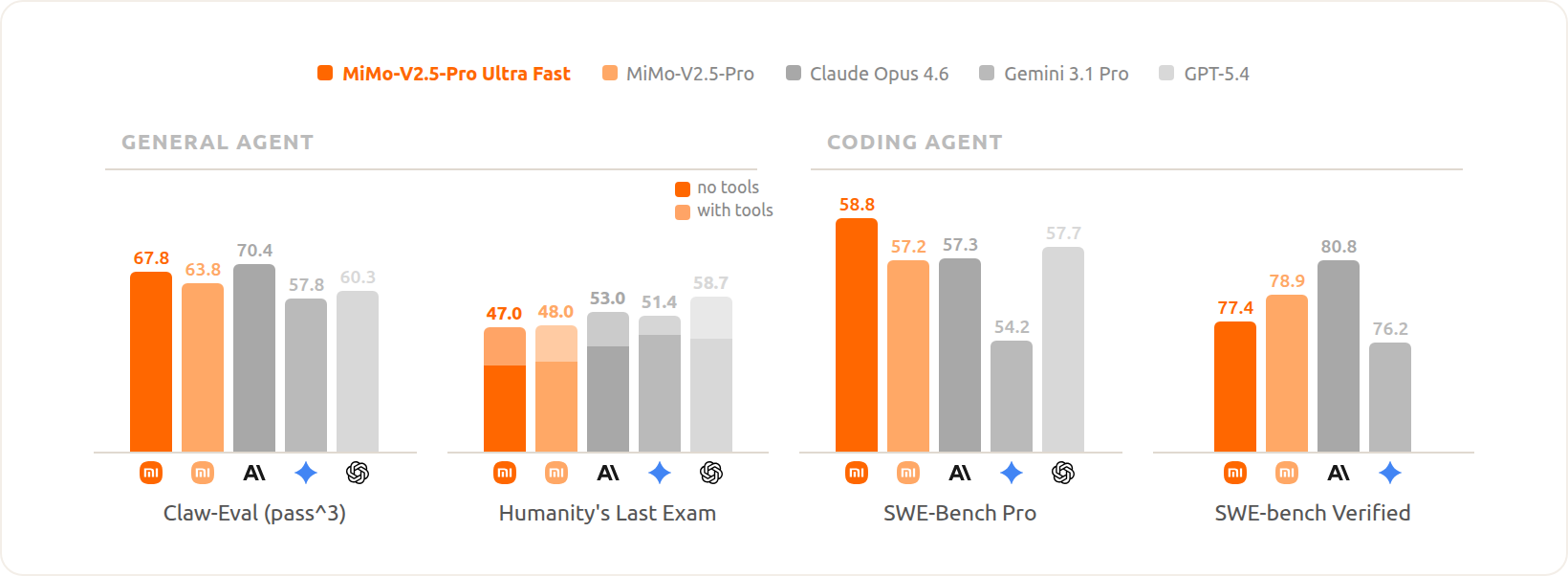
The results are almost too good to believe. On SWE-Bench Verified, the FP4-quantized model actually improved over the FP8 baseline (77.4% vs 78.9%, a minor dip, but essentially on par). On Claw-Eval (pass@3), it jumped from 63.8 to 67.8. The quantization-aware training (QAT) process squeezed the model down without squeezing out its intelligence.
The key takeaway here: mixed-precision quantization isn’t just about saving bits. It’s about understanding which parts of your architecture are resilient to compression and which aren’t. The MoE experts, with their specialized knowledge distributions, turn out to be remarkably robust to 4-bit quantization.
2. DFlash Speculative Decoding: Breaking the Autoregressive Bottleneck
FP4 solved the memory bandwidth problem, but even with the weights loaded faster, autoregressive decoding still generates one token at a time. Each forward pass produces a single token, then you shift the window and do it again. At 1000 TPS, that means each token is generated in 1 millisecond, but the serial nature of the process means you’re constantly waiting on the next compute cycle.
Traditional speculative decoding tackles this by using a lightweight “draft” model to guess several tokens ahead, then having the large model verify them in parallel. The problem is that the draft model’s quality determines the acceptance rate, and improving the draft model increases its compute cost, a fundamental tension.
DFlash, the approach Xiaomi adopted, breaks this trade-off entirely. Instead of generating tokens autoregressively, the draft model fills an entire block of masked positions in a single forward pass. This eliminates the serial constraint of drafting entirely.
The real engineering magic, though, is how they optimized this for a 1T MoE model at scale:
-
Sliding Window Attention (SWA): The draft model exclusively uses SWA, which aligns perfectly with the MiMo-V2 series architecture. This eliminates the dependency on full context prefixes, reducing per-prediction compute from linear-in-context-length to constant. Massive win for long-context scenarios.
-
Localized training signals: During training, mask-signal sampling is pushed down to GPU-local shards. A single sequence can produce tens of thousands of independent training signals covering diverse context positions, all without cross-device communication.
The acceptance lengths tell the real story:
| Scenario | Acceptance Length |
|---|---|
| Coding | 6.30 |
| Math / Reasoning | 5.56 |
| Agent | 4.29 |
In coding scenarios, the model accepts 6-7 out of every 8 draft tokens. That means the large model verifies almost an entire block in one shot, effectively multiplying throughput by 6x in practice. The block size is capped at 8 to keep verification overhead low, but the acceptance rates mean those 8 slots are almost fully utilized.
3. TileRT: The Microsecond-Level Execution Engine
FP4 and DFlash are necessary conditions, but they aren’t sufficient. To hit 1000 TPS, you need an inference runtime that doesn’t waste a single microsecond.
At this frequency, each operator’s lifecycle is measured in microseconds. The traditional inference engine model, launch an operator, wait for synchronization, move data, launch the next operator, fractures the execution flow at exactly the wrong granularity. Those “operator boundaries” become the bottleneck, exposing visible “Execution Gaps” where the GPU sits idle.
TileRT’s solution is a paradigm shift in runtime architecture:
-
Persistent Engine Kernel: Instead of launching operators one at a time, the entire compute pipeline remains resident in the GPU. While the current Tile is computing on Tensor Cores, subsequent data is already flowing through the memory hierarchy. Full-pipeline continuous prefetching, all the time.
-
Warp Specialization: Different warps (thread groups) handle communication, data movement, and tensor computation independently but in precise coordination. The GPU becomes a continuously flowing heterogeneous execution system rather than a homogenous lock-stepped compute array.
This is deep hardware-software co-design. The TileRT team didn’t just optimize a runtime, they fundamentally rethought how a GPU’s execution model should work for low-latency inference. The result is an engine that can sustain 1000 TPS because it never waits for anything.
The Economics: 3x the Cost for 10x the Speed
Xiaomi is making this available as an API, with a pricing model that’s refreshingly honest: 3x the cost of standard MiMo-V2.5-Pro, for approximately 10x the generation speed.
This is the kind of math that changes how you think about inference spend. If you’re running a coding agent that generates 100,000 tokens per session, the standard API costs you $X. The UltraSpeed API costs $3X but finishes in one-tenth the time. For agentic workflows where latency directly impacts user experience and iteration speed, that trade-off is an absolute no-brainer.
The catch is availability. Due to limited high-speed inference resources, access is application-based and time-limited (June 9-23, 2026, Beijing Time). Approved users get free chat access within that window, with a 30-minute session cap and 5-minute idle timeout. This is clearly a beta-grade deployment, but the technology behind it is production-ready.
Why This Matters More Than the Number
A thousand tokens per second on a 1T model isn’t just a speed record. It changes what’s possible with large models:
-
Real-time reasoning chains: At 1000 TPS, you can run multiple reasoning paths in parallel within the same wall-clock time it would normally take to get one answer. Best-of-N search, tree-of-thought, automatic self-correction, all become practically feasible at scale.
-
Coding agents that don’t feel like agents: The latency bottleneck that makes AI coding assistants feel sluggish disappears. Code generation becomes truly interactive, not “wait-and-see.”
-
Trillion-parameter models in time-critical loops: High-frequency trading, instant fraud detection, real-time bidding, surgical decision support, scenarios where milliseconds matter can now leverage flagship model quality.
As the Xiaomi team noted, in life-or-death situations like surgical assistance, “every second AI saves in completing lesion analysis and risk prediction gives the surgeon one more degree of freedom.” Speed stops being a metric and becomes a moral imperative.
The Open Source Payout
Xiaomi has open-sourced the MiMo-V2.5-Pro-FP4-DFlash checkpoint on Hugging Face. If you want to poke at the internals, the weights and DFlash model parameters are available for download.
The SGLang deployment example in the model card is worth studying. It reveals the parallelism topology: tensor parallelism of 16, expert parallelism of 16, data parallelism of 2, with DP-attention and DP-lm-head enabled. This is serious distributed inference engineering, and Xiaomi is giving it away.
For teams running large-scale model serving infrastructure, understanding the control plane implications of this approach is critical. TileRT’s persistent execution model essentially eliminates the traditional control plane overhead that plagues most distributed inference systems.
The Verdict
Xiaomi and TileRT didn’t invent new hardware to hit 1000 TPS on a 1T model. They did something harder: they forced existing hardware to behave like it was purpose-built for the task. Through a combination of selective FP4 quantization, block-level speculative decoding, and a ground-up rethinking of the GPU execution model, they achieved what most in the industry thought required custom silicon.
The broader lesson here is about architectural constraints. The industry has been chasing specialized hardware as the answer to inference at scale. Xiaomi’s achievement proves that deep software-model co-design can extract performance that wasn’t thought possible on commodity GPUs. For every team running a large model in production, this should be a wake-up call: you’re probably leaving performance on the table because you’re not willing to fundamentally rethink your architecture.
The latency that feels like a fact of life is actually a choice. And sometimes, the right choice is to bend the software until the hardware has no choice but to obey.
Try the UltraSpeed API at platform.xiaomimimo.com/ultraspeed (application-based, limited window June 9-23). The open-source checkpoint is at huggingface.co/XiaomiMiMo/MiMo-V2.5-Pro-FP4-DFlash.
For more on the scalability implications of this approach, check out our analysis of control plane bottlenecks in distributed architectures and scalability traps in real-time aggregation systems.


