The tension between data freshness and system performance defines modern dashboard architecture. While real-time aggregation promises live insights, it often collapses under read load, turning your database into a bottleneck that costs you millions in architectural scaling mistakes.
This post examines event-driven alternatives, specifically CQRS with event sourcing, outbox patterns, and projection-based read models, that decouple write operations from analytical queries. We explore the four layers of idempotency required for production reliability, the mechanics of rebuilding projections when business logic changes, and the specific scenarios where pre-computed aggregates outperform on-the-fly calculations.
The $50,000 Query Problem
Every dashboard starts innocently enough. A SELECT with some GROUP BY clauses, maybe a few joins. At 1,000 users, it hums. At 100,000 users, it groans. At 1,000,000 users, your database CPU graph looks like a vertical cliff and your on-call engineer starts updating their LinkedIn profile.
The traditional approach, computing aggregations directly on transactional data, creates a fundamental conflict. Your write-optimized OLTP schema is being tortured by read-heavy analytical queries that scan millions of rows to calculate “total revenue this week.” Meanwhile, your actual business transactions are queuing up like angry commuters at a broken turnstile.
The Escalation Curve:
- 1,000 Users: System hums comfortably.
- 100,000 Users: Performance noticeably degrades.
- 1,000,000 Users: Database CPU becomes a vertical cliff; on-call engineers panic.
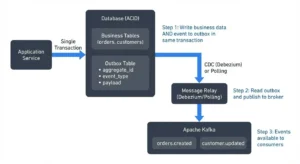
Event-driven architectures offer an escape hatch, but they come with their own complexity tax. The pattern typically involves: domain services persisting data, writing events to an outbox table, publishing those events via Kafka, and maintaining separate read models (projections) optimized for specific queries. Developers evaluating similar setups often question whether this constitutes overengineering for systems that haven’t yet reached massive scale, particularly when simpler ETL approaches might suffice for less demanding workloads.
CQRS Isn’t Just “Separate Read and Write Databases”
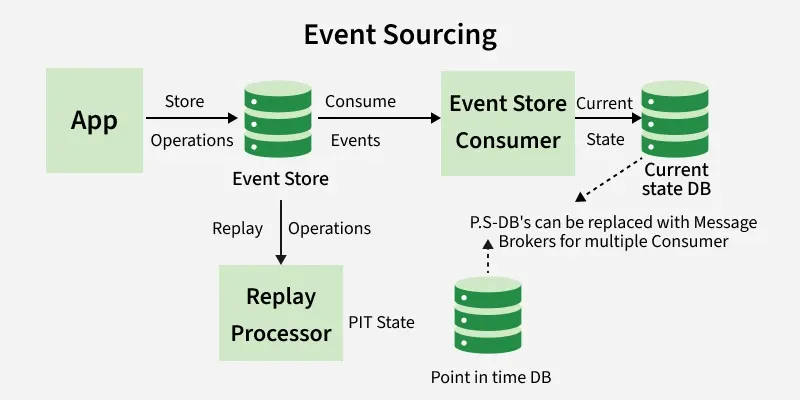
Command Query Responsibility Segregation (CQRS) gets thrown around like architectural confetti, but in the context of event sourcing, it has a specific meaning. Instead of storing just the current state, you store every change as an immutable event. The current state, the projection, is obtained by replaying these events in sequence.
As outlined in event sourcing fundamentals, this means your “database” is actually an append-only log of facts. An account balance isn’t a column you update, it’s the sum of AccountCredited and AccountDebited events since account creation. This provides a complete audit trail and the ability to reconstruct historical states, but it also means you can’t query by arbitrary criteria without building specific read models.
The catch? You can’t just slap a WHERE clause on an event stream. If you need to find “all expenses over $500 submitted by contractors in the last quarter”, you need a projection that maintains that specific denormalized view. This is where database schema design becomes critical, event sourcing shifts the complexity from the transactional schema to the query models.
The Outbox Pattern: Atomicity or Anxiety
The dual-write problem haunts distributed systems. If you save data to PostgreSQL and then publish to Kafka, a crash between the two leaves your systems inconsistent. Reverse the order, and you might publish events for transactions that eventually roll back. The outbox pattern solves this without requiring two-phase commit coordination.
The implementation is elegant in its simplicity: in the same database transaction where you save your event, you also write it to a dedicated outbox table. A separate worker polls this table and publishes to Kafka, marking rows as sent upon confirmation.
CREATE TABLE outbox (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
event_type VARCHAR(100) NOT NULL,
payload JSONB NOT NULL,
published BOOLEAN DEFAULT FALSE,
created_at TIMESTAMPTZ DEFAULT NOW(),
published_at TIMESTAMPTZ
);The Go implementation from production systems demonstrates the atomicity requirement:
func (s *Store) SaveEventAndOutbox(ctx context.Context, tx *sqlx.Tx, event Event) error {
// 1. Save the event in the event store
if err := s.saveEvent(ctx, tx, event), err != nil {
return err
}
// 2. Write to the outbox, same transaction, same commit or same rollback
_, err := tx.ExecContext(ctx,
`INSERT INTO outbox (event_type, payload) VALUES ($1, $2)`,
event.Type,
event.Payload,
)
return err
}The worker runs on a ticker (typically 100ms) or uses PostgreSQL’s LISTEN/NOTIFY for immediate triggering:
func (w *OutboxWorker) publishPending(ctx context.Context) error {
rows, err := w.db.QueryContext(ctx,
`SELECT id, event_type, payload FROM outbox
WHERE published = FALSE
ORDER BY created_at
LIMIT 100`,
)
// ... publish to Kafka and mark as sent
}This guarantees at-least-once delivery. The worker may crash after publishing to Kafka but before marking the row, leading to duplicate messages. Which brings us to the next requirement: idempotency everywhere.
The Four Layers of Idempotency
In HTTP, idempotency is straightforward: store the key, return the cache. In a CQRS/Event Sourcing system, it’s more subtle. The command may be idempotent, but what about the event it generates? The projection consuming it? Idempotency must cross the entire stack to prevent duplicate payments, double-counted metrics, or inconsistent dashboard states.
Layer 1: Command Idempotency
Store processed commands with their idempotency keys:
CREATE TABLE processed_commands (
idempotency_key UUID PRIMARY KEY,
aggregate_id UUID NOT NULL,
command_type VARCHAR(100) NOT NULL,
result_event_id UUID,
processed_at TIMESTAMPTZ DEFAULT NOW()
);The handler checks this table before processing, and the save must be atomic with event persistence.
Layer 2: Optimistic Locking
Prevent concurrent commands on the same aggregate from corrupting state:
CREATE TABLE account_events (
id UUID PRIMARY KEY,
aggregate_id UUID NOT NULL,
version INT NOT NULL,
event_type VARCHAR(100) NOT NULL,
payload JSONB NOT NULL,
created_at TIMESTAMPTZ DEFAULT NOW(),
UNIQUE(aggregate_id, version) -- key constraint
);The UNIQUE(aggregate_id, version) constraint ensures that if two concurrent commands try to write version 5 of the same aggregate, PostgreSQL rejects the second with a uniqueness violation.
Layer 3: Idempotent Projections
Since Kafka provides at-least-once delivery, projections must handle duplicate events gracefully. Two approaches exist:
Checkpoint tracking:
CREATE TABLE projection_checkpoints (
projection_name VARCHAR(100) PRIMARY KEY,
last_event_id UUID NOT NULL,
updated_at TIMESTAMPTZ DEFAULT NOW()
);Idempotent upserts:
INSERT INTO account_balances (account_id, balance, last_event_id)
VALUES ($1, $2, $3)
ON CONFLICT (account_id) DO UPDATE
SET balance = EXCLUDED.balance,
last_event_id = EXCLUDED.last_event_id
WHERE account_balances.last_event_id < EXCLUDED.last_event_id;The WHERE clause prevents stale events from overwriting newer state when processing out-of-order messages from multiple Kafka partitions.
Layer 4: Outbox Guarantees
The outbox pattern itself provides the fourth layer, ensuring events are never lost between the database and the message broker.
| Problem | Solution |
|---|---|
| Command received twice (client retry) | Idempotency key in processed_commands |
| Two concurrent commands on same aggregate | Optimistic locking (UNIQUE constraint on version) |
| Event published twice by broker | Idempotent projection (checkpoint or upsert) |
| Crash between save and publish | Outbox pattern (atomicity via transaction) |
Building Projections: More Than Just Caching
Projections are read models created from the event stream, optimized for specific query patterns. Unlike materialized views in a relational database, these are application-level constructs that can evolve independently of your transactional schema.
Consider an expense tracking system implemented in F#. The events form a discriminated union:
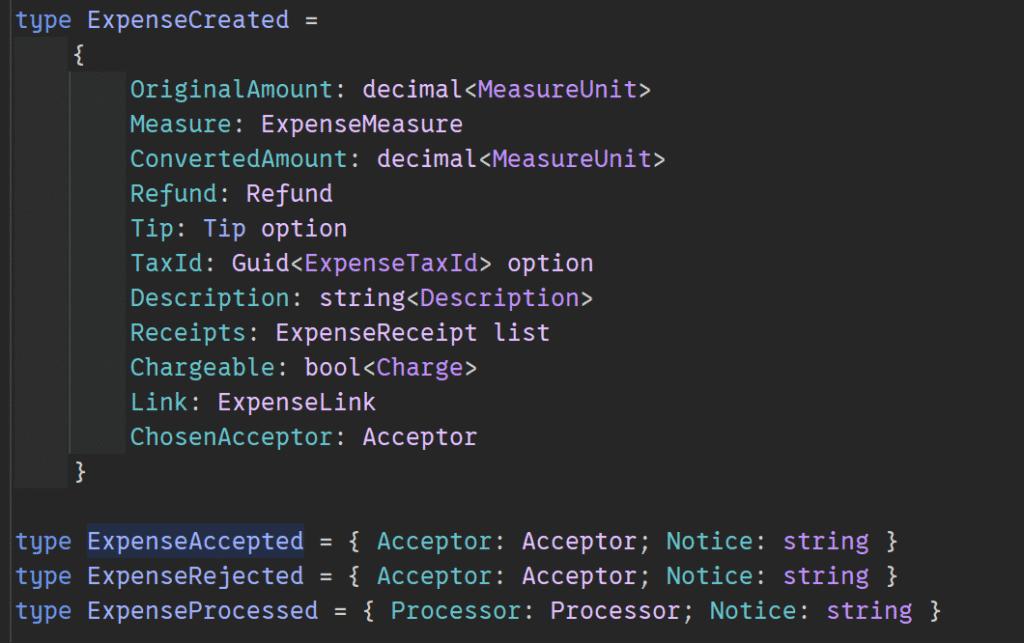
The projection logic defines how each event transforms the read model. For an expense dashboard showing current status, you might project events into a table with columns for current_status, last_updated, and total_amount. The key insight from production implementations: simple projections that replay all events work fine until you hit long event streams or CPU-heavy calculations (like manipulating tree structures). At that point, you need snapshots or partitioned read models.
Reprocessing: When Business Logic Changes
The ability to rebuild projections isn’t just for disaster recovery—it’s a feature. When business logic changes (e.g., “we now calculate VAT differently for expenses over €1,000”), you can reprocess events by scope to rebuild your dashboards without touching the source events.
This requires careful versioning. Your projection code must handle events from different schema versions, or you must upcast old events to new formats during the replay. The outbox pattern helps here too: by reprocessing historical events through new projection logic and writing to a new read model, you can A/B test new dashboard calculations against historical data before switching over.
Decision Matrix: When to Project vs. Calculate Real-Time
Use Real-Time Aggregation When:
- Data volume is low (< 100k events/day)
- Query patterns are ad-hoc and unpredictable
- Eventual consistency (even seconds of delay) is unacceptable
- You need the flexibility of SQL for exploratory analysis
Use Projections When:
- Read load significantly exceeds write load
- Query patterns are stable and well-defined (e.g., “monthly revenue by region”)
- You can tolerate eventual consistency (seconds to minutes of lag)
- You need to scale reads independently of writes
The “overengineering” threshold isn’t about company size, it’s about query complexity. If your dashboard requires joining six tables and calculating running totals across millions of rows, you’ve already crossed into projection territory, whether you admit it or not.
The Operational Reality
Event-driven dashboards with projections aren’t free. They require monitoring checkpoint lag, handling poison pills in Kafka streams, and maintaining projection code that must stay in sync with event schemas. But the alternative, watching your transactional database melt under analytical load, is often more expensive in terms of hardware costs and engineering firefighting.
The patterns described here, outbox tables, optimistic locking, idempotent upserts, aren’t theoretical. They’re the baseline for financial systems and high-volume SaaS platforms where “duplicate payment” tickets are unacceptable. Start with simple projections, add idempotency layers before you need them, and remember that in distributed systems, retries aren’t edge cases, they’re Tuesday.