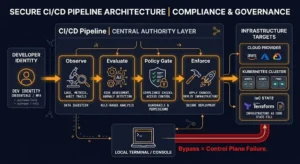
Here’s a painfully common anti-pattern dressed up as good architecture: every single customer request, regardless of purpose or destination, must first travel to a central control plane for inspection, blessing, and routing. It’s neat, it’s governable, and it’s a single point of catastrophic failure that adds hundreds of milliseconds to every user interaction in Japan.
The sentiment from the trenches is clear: this dogmatic centralization creates fragile systems, introduces massive latency for far-flung users, and creates a performance ceiling that scaling just can’t fix. The problem isn’t abstract. When your control plane fails, your entire customer-facing API fails with it. The centralized model is buckling under the pressure of global scale and real-time demands.
We need to talk about escaping the monolithic control plane without descending into anarchy.
The Anatomy of an Unnecessary Middleman
The canonical example is illuminating: client → nginx → control plane → db cluster. The control plane, responsible for orchestration and policy, also becomes the data plane bottleneck for every REST call. This isn’t just inefficient, it’s architecturally negligent for any service with global users.
As Cisco’s analysis underscores, geographical distance is a primary driver of latency. Edge computing, locating data and processing closer to users, is a well-known mitigation strategy. Yet, many architectures default to a hub-and-spoke model where the hub is conveniently located in, say, Virginia. For a user in Tokyo, this means adding at least a 100ms round-trip penalty before their request even reaches its intended service.
The fundamental issue is a conflation of roles. As TrueFoundry’s breakdown makes clear: the control plane is for strategic governance, RBAC, quota enforcement, audit logging, and policy. The data plane is for execution, forwarding packets, processing requests, and returning results at line speed.
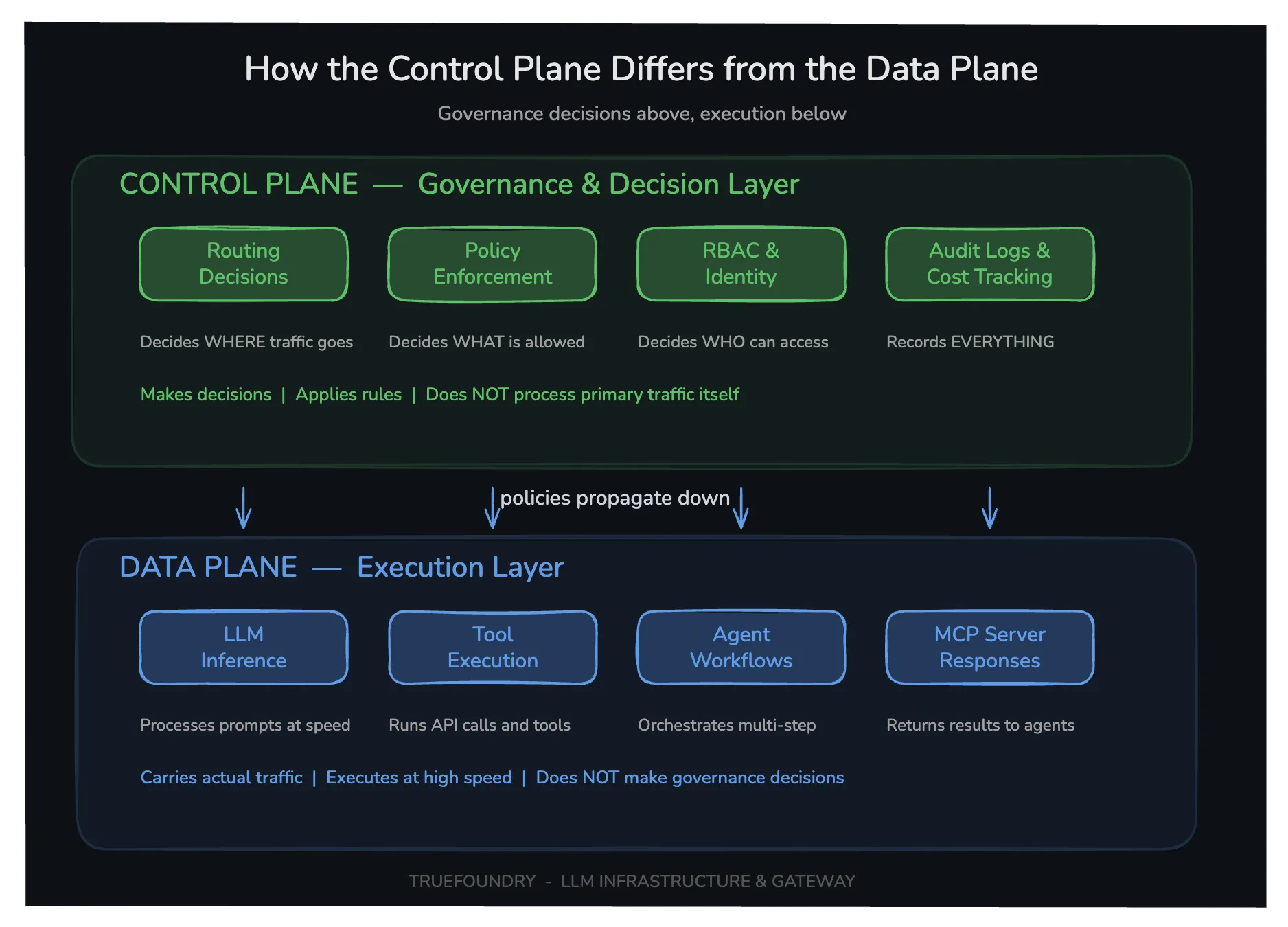
Forcing data plane traffic through the control plane is like making every car on the highway stop at the Department of Motor Vehicles for an inspection before proceeding to its destination. It creates governance at the expense of velocity.
The Real-World Consequences: A Multi-Front Assault
This architectural choice has cascading, tangible impacts.
1. The Single Point of Failure: In the client → control plane → db flow, the control plane isn’t just a manager, it’s a critical chokepoint. If it’s down for maintenance, suffers an overload, or experiences a regional cloud outage, all customer traffic stops. This creates an availability profile that mirrors the least reliable component in your most critical path.
2. Predictable, Unavoidable Latency: The physics are inescapable. Light travels at roughly 200 km/ms in fiber. A round trip from Tokyo to US East Coast is ~15,000 km, adding a bare minimum of 75ms of propagation delay, before processing, queuing, or serialization overhead. Process that request through a central control plane, and you’re easily looking at 200-300ms added to every API call. For interactive applications, this is a death knell.
3. Spiraling Costs and Complexity: Centralizing traffic means you must scale your control plane to handle all traffic, not just the orchestration workload. This often leads to massively over-provisioned, expensive control clusters. Furthermore, debugging performance issues becomes a nightmare, is the slowdown in the app logic, the database, or the control plane’s proxy layer?
The irony is that this pattern often emerges from a genuine need for authorization complexities in scalable systems. As one architect asks, where does domain authorization occur? Can the database cluster alone answer if a user was removed or a subscription suspended? These are valid control plane concerns, but they don’t justify routing all data through it.
A Better Model: Decoupling Governance from the Critical Path
The proposed fix is elegant in its separation of concerns: bifurcate the flows.
– Control Path (client → nginx → control plane): For management actions: creating a cluster, scaling, updating configurations. This traffic is low-volume, tolerates higher latency, and requires centralized policy.
– Data Path (client → ALB → db cluster): For runtime, customer-facing API calls. This traffic is high-volume, latency-sensitive, and should be served by a regional Application Load Balancer (ALB) deployed adjacent to the database cluster.
The ALB becomes a policy enforcement point (PEP) that is configured by the control plane but executes locally. The control plane pushes down authorization tokens, routing rules, and rate limits. The ALB applies them. This is the essence of the control/data plane split applied to application architecture.
This pattern mirrors what’s happening in cutting-edge spaces like AI gateways. Platforms like TrueFoundry tout a ~3, 4 ms latency overhead while handling 350+ requests per second on a single vCPU by acting as a smart, distributed policy enforcement layer, not a centralized proxy.
The industry is signaling this shift. Palo Alto Networks’ acquisition of Portkey highlights the need for a scalable, low-latency “AI gateway” that can process trillions of tokens per month as a control point for AI agent traffic, a problem space demanding both governance and speed, much like our microservice API dilemma.
The Latency Killers: More Than Just Geography
Escaping the control plane isn’t just about moving compute closer. It’s about rethinking the entire transport and protocol stack. Consider OpenAI’s real-time Voice API, which had to collapse a cascaded STT→LLM→TTS pipeline and adopt WebRTC over UDP to achieve sub-500ms latency. Their shift acknowledges that TCP and HTTP/2, with head-of-line blocking and retransmission delays, are often the hidden bottlenecks in “centralized” architectures.
Similarly, for microservices, the choice between a regional ALB (data plane) and a global API Gateway (control plane) has profound implications. The ALB can leverage optimized, regional AWS backbone links, while a global gateway might traverse the public internet.
A comparison of transport layers reveals the trade-off:
| Feature | Centralized API Gateway (Control Plane Proxy) | Regional ALB / Data Plane Proxy |
|---|---|---|
| Primary Protocol | HTTP/1.1, HTTP/2 (TCP) | HTTP/2, gRPC, potentially QUIC |
| Latency Profile | High (Global + Processing) | Low (Regional + Direct) |
| Failure Domain | Global (Single Region) | Regional |
| Governance | Centralized, Pre-execution | Decentralized, Policy-Enforced |
| Scalability | Must scale for all traffic | Scales with regional demand |
The modern answer isn’t abandoning governance, it’s decentralizing its execution. This is the same principle behind the strategic performance costs of unified platforms, where monolithic control creates a tax on every operation.
Building a Governed, Low-Latency Future
So, how do you actually build this? It starts with a clear separation of traffic types.
- Classify Your Endpoints: Which APIs are management/control (create, delete, configure) and which are runtime/data (query, update, read)? The former goes to the control plane, the latter should be routable directly to regional endpoints.
- Implement a Token-Based Trust Model: The control plane issues short-lived, scoped tokens (e.g., JWTs) when a resource is provisioned. The client presents this token to the regional data plane endpoint (ALB). The ALB validates the token (using a fast, local keyset) and checks it against a lightweight policy pushed from the control plane. This moves authorization logic to the control plane but enforcement to the edge.
- Deploy a Global Load Balancer with Intelligence: Use a global load balancer (like GCLB, ALB, or a modern service mesh ingress) that can route
POST /api/clusterstous-central-controlandGET /api/clusters/{id}/datatoasia-southeast1-data. Path-based or host-header routing is your friend. - Instrument Everything: The fear of losing visibility is what drives centralization. Combat this by implementing a unified, centralized observability plane that aggregates logs, traces, and metrics from all regional data planes. The control plane should observe all traffic, not carry it.
- Embrace Progressive Delivery: Start with a hybrid model. Route all traffic through the control plane, but deploy regional data plane components and start shifting traffic over for non-critical, latency-sensitive endpoints. Measure, compare, and iterate.
TrueFoundry’s AI Gateway exemplifies this pattern: a single control plane for governance deployed across multiple regions, with data plane proxies co-located near the models they serve. This provides the unified visibility and policy management craved by enterprises without the latency penalty.
The Bottom Line: Choose Your Bottleneck Wisely
The centralization-versus-latency debate is a false dichotomy. You don’t have to choose between governance and performance. You have to choose where to place each concern.
The control plane should be the brain, making decisions, setting policy, and auditing outcomes. The data plane should be the circulatory system, fast, distributed, and resilient, executing those decisions locally. Forcing all blood flow through the brain is a fatal design flaw, both in biology and in software architecture.
The next time you’re designing a system where a user in Osaka is waiting on a server in Ohio just to check their own data, remember: your latency isn’t a bug, it’s a feature of your architecture. And it’s a feature your users will happily pay you to remove.
This evolution mirrors the broader industry shift away from monolithic choke points, a lesson painfully learned in other domains like network security isolation failures in microservice architecture. The future is distributed, governed, and fast. It’s time to escape the control plane bottleneck.