A founder grabs a beer on a Saturday, fires up Claude, and by Sunday evening has a prototype that “mostly” works. He drops it in the team’s lap: “Just polish this up, shouldn’t take more than two weeks.” Three months later, the team is still untangling the mess.
In the military, this is called “getting inside your OODA loop.” The pilot who cycles through Observe, Orient, Decide, Act faster and more accurately than their opponent wins the dogfight. In software, our dogfight is against technical entropy, and right now, most of us are losing because our loops are fundamentally broken.
What Actually Is an OODA Loop (and Why You’ve Been Using It Wrong)
First, a correction. The OODA loop is not a simple four-step circle. It’s a dynamic, recursive model for decision-making under uncertainty, developed by fighter pilot John Boyd. The OODA WIKI defines its core mechanic: continuous collection of feedback and observations. This enables late commitment, a critical advantage in rapidly changing environments, and is a direct contrast to the rigid PDCA (Plan-Do-Check-Act) cycle that demands early commitment.
In software, we often mistake fast programming for a fast OODA loop. Writing code quickly is just the Act phase. The real work, and where teams spend those “two weeks”, is in the Observe and Orient phases: building the harness, the tests, the observability, and the automation that lets you actually see what you’re doing. As one analysis of AI-powered development warns, without deliberate context, you end up accelerating but not understanding, a recipe for mitigating AI-related architectural failures.
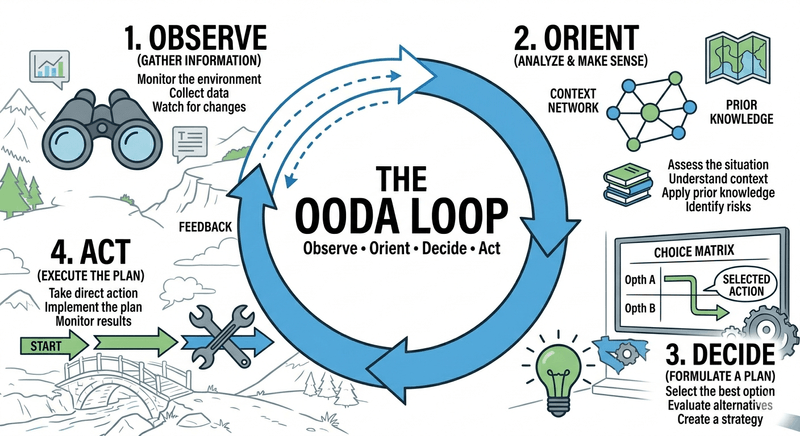
The Four Stages of an Architectural Dogfight
1. Observe: Beyond “Does It Run on My Machine?”
The military definition of Observation is “the intake of raw, unfiltered information.” In our world, raw data is your production metrics, trace logs, error rates, and dependency graphs. If all you have is a manually deployed app and a prayer, you aren’t observing the system, you’re just looking at it. Your inputs are messy, your observation is clouded.
A real-world example from developer Oskar Dudycz illustrates this perfectly. While adding OpenTelemetry to a project, he didn’t just trust unit tests. He needed to see it work in a real sample. He set up a Grafana stack via Docker Compose and manually configured it, a classic weekend “vibe.” The initial observation? It worked… once. But when he tried to repeat the process, the magic was gone. He had vibed a solution without building a repeatable, observable harness.
This is the crux of broken architectural loops. The founder Observes a working UI and assumes victory. The engineering team Observes a spaghetti-monolith of implicit dependencies, flaky integrations, and zero monitoring. These are two completely different realities.
2. Orient: The Looming LLM Trap (and How to Avoid It)
Orientation is where you filter observations through experience, culture, and technical knowledge. It’s the most critical and fragile stage.
This is where our tools betray us. As Alex Vohr notes in his analysis of OODA for complex systems, a decision should be treated as a hypothesis that only becomes true when action and feedback confirm it. LLMs now enable us to Decide and Act in seconds, generating code that looks perfect. The trap is outsourcing Orientation to the machine’s confidence. If you don’t understand how a database handles concurrent connections, your orientation of that generated SQL script will be shallow. You’ll see code that looks right, decide it’s fine, and act by merging it. You’ve skipped Orientation and paid for it in production.
3. Decide & Act: The Delusion of Deployable Speed
Decide is formulating a hypothesis based on your orientation. Act is executing it. The cliché is that this is where software slows down due to “bureaucracy.” The reality is often the opposite: we Act too quickly on poorly-formed decisions.
The problem isn’t that deployment takes time. The problem is that our Act phase now takes seconds (git push, CI runs), but our Observe phase still requires a manual weekend clicking through logs. If your CI/CD pipeline only runs unit tests, you have a fast Act and a blind Observe. You’ve optimized for the wrong part of the loop.
Teams don’t need “two weeks” to polish a founder’s code. They need that time to build the infrastructural harness, the automated Observation layer, that makes the OODA loop sustainable. They are turning a one-off vibe into a repeatable, observable, and governable system.
Building the Harness
So, how do you build a functional OODA loop for architecture? You engineer a harness. Let’s look at Dudycz’s implementation for his Emmett project observability.
He didn’t stop at a manual Docker setup. He automated the entire Observe phase. He created a Node.js test script that does the following:
- Automates Infrastructure: Spins up the full observability stack (Grafana, Prometheus, Loki, Tempo, PostgreSQL) using Docker Compose.
- Waits & Validates: Waits for all services to be ready and healthy.
- Runs the Test: Starts the application, makes HTTP requests to generate traces and metrics.
- Observes the Results: Programmatically checks that the expected metrics appear in the OpenTelemetry collector and Prometheus.
async function diagnoseCollector() {
const text = await fetch(URLS.otelCollectorMetrics)
.then((r) => r.text())
.catch(() => 'unreachable');
const emmett = text
.split('\n')
.filter((l) => l.startsWith('emmett_') && !l.startsWith('#'))
.slice(0, 5);
console.log(
emmett.length
? `\n collector /metrics (emmett lines):\n ${emmett.join('\n ')}`
: '\n collector /metrics: no emmett_* lines found',
);
}
test('OTel collector exposes Emmett metrics on port 8889', async () => {
// Send requests to generate data
for (let i = 0, i < 5, i++) {
await fetch(CART_ENDPOINT, { method: 'POST', headers: {...}, body: ADD_PRODUCT_BODY });
}
// Then wait and verify metrics appear
await waitFor(
async () => {
const res = await fetch(URLS.otelCollectorMetrics);
const text = await res.text();
const emmettLines = text.split('\n').filter((l) => l.startsWith('emmett_') && !l.startsWith('#'));
return emmettLines.length > 0;
},
{ timeout: 90_000, interval: 5_000, label: 'emmett metrics on collector :8889' }
);
});This script is the harness. It codifies the Observation criteria. It kills the weekend-beer manual verification process. It creates a fast, reliable feedback loop. Now, the Act (a code change) immediately triggers a robust Observe (the automated test suite), which informs the next Orient (did my change work as intended?).
This is the shift from architectural design to architectural constraints, a pattern explored in The Death of the Blueprint: How AI Coding Is Shifting Architecture from Design to Constraints. Your architecture isn’t a static blueprint, it’s the set of automated constraints and feedback mechanisms that keep the evolving system coherent.
Late Commitment: The Superpower for Modern Architecture
This brings us back to the OODA wiki’s key insight: late commitment. Compared to traditional, plan-heavy approaches (like PDCA), a fast OODA loop allows you to gather more information before locking in a decision. You don’t have to decide on your database schema or service boundaries on day one. You can Observe how the application scales, Orient based on real usage patterns, and Decide to refactor or split services later.
The goal is not to avoid decisions but to make them at the last responsible moment with the most possible information. This is agility in the Boydian sense, not moving fast and breaking things, but moving accurately and adapting faster than your problems evolve.
Your OODA Loop Is Probably Broken. Here’s How to Fix It.
Does this sound familiar? A “quick fix” creates a week of firefighting. A “simple feature” unravels three unrelated modules. These are symptoms of a broken loop. To fix it, you need to invest in your Observe and Orient capabilities, which often means slowing down initial Act to enable sustainable speed later.
- Instrument Everything, Automate Observation. Metrics, logs, and traces are not “nice-to-haves” for production. They are the primary data source for your architectural OODA loop. If you can’t observe the impact of a change within minutes, your loop is broken.
- Treat LLM Output as a Hypothesis, Not Code. Every LLM-generated module, script, or config is a hypothesis about what will work. Your job is to design the fastest possible test (Observe) to validate or refute it. This safeguards against AI tools lacking architectural context.
- Build Feedback Into Your Pipeline. Your CI/CD pipeline shouldn’t just “run tests.” It should run your architectural harness, the automated observation system that proves the system’s properties are intact. Move from “the build passed” to “the observability stack confirms the change behaves as expected.”.
- Orient as a Team, Not an Individual. Orientation is where experience and context live. Use tools like Architectural Decision Records (ADRs), but more importantly, cultivate a culture of rapid, blameless post-mortems and knowledge sharing. Every production incident is a failed Orientation, study it.
- Decide Based on Constraints, Not Guesses. Frame architectural decisions as choices between competing, observable constraints (e.g., latency vs. consistency, simplicity vs. flexibility). This moves the conversation away from opinion and toward measurable trade-offs.
The final, crucial step is recognizing that this is a leadership and process problem, not just a technical one. Many of the most costly recurring architectural failures stem from organizations valuing the visible Act over the invisible but critical Observe and Orient.
The next time someone asks why a simple change takes “so long”, don’t talk about polishing code. Talk about closing the loop. Talk about building the harness that turns chaotic vibing into governed evolution. In the architectural dogfight against entropy, the team with the faster, tighter OODA loop doesn’t just win, it’s the only one that survives.