
Armed with an RTX 5090 laptop and Qwen3.6-27B running via llama.cpp, they stated they’d be cancelling their cloud subscriptions. Their reasoning? The model “passed all my tool call and data science benchmarks” for PySpark and Python debugging tasks, performing “basically perfect” for their professional workflow.
This isn’t an isolated case. It’s a trend powered by bleeding-edge software optimization, specifically, speculative decoding, collapsing the speed gap between local inference and cloud API calls. The logical endgame is a fraction of the infrastructure cost and zero data egress, understanding the extremes of silicon-scale AI constraints but applied to your desktop.
The Speed Breakthrough: N-Gram Speculative Decoding
ngram-mod.
The concept is devilishly simple: instead of using a small, separate “draft” model to guess the next few tokens, the system learns from the model’s own recent output. It creates a lightweight hash pool of common n-gram (e.g., 24-token) sequences. During generation, it predicts the next token based on this learned cache and verifies it with the full model in a batch. If the draft tokens are correct, you skip several sequential forward passes.
One tester using ngram-mod with a 40GB VRAM setup (RTX 3090 + RTX 4060 Ti) documented a performance climb from 13.60 tokens/sec to a staggering 136.75 tokens/sec during a single, iterative coding session. Their command-line flag for this magic bullet? A single line: --spec-type ngram-mod --spec-ngram-size-n 24 --draft-min 12 --draft-max 48.
This isn’t a theoretical lab benchmark. It’s a practical, reproducible configuration shift demonstrating that closing the functional gap between offline models and cloud browsing is now paired with raw throughput gains. The associated pull request shows why: this method is “lightweight (~16 MB), constant memory and complexity”, and shares its cache across all server slots, meaning different requests can benefit from each other’s patterns.
The Hardware Reality: 3090s, Not H100s
Consider the quest for an “overnight stack” for Qwen3.6-27B on a single RTX 3090. One developer documented a journey to achieve 85 tokens/sec with a 125K context window. The solution involved a custom vLLM stack, multi-token prediction (MTP), TurboQuant KV cache quantization, and a specific CUDA patch to avoid “Cannot copy between CPU and CUDA tensors during CUDA graph capture” errors.
Their final Docker configuration is telling. It’s not a simple one-liner, it’s a carefully orchestrated symphony of performance hacks (--kv-cache-dtype turboquant_3bit_nc, --speculative-config '{"method":"mtp","num_speculative_tokens":3}'). This level of technical depth is now required to unlock consumer-hardware performance, balancing local control against emerging cloud dependencies.
The MoE Caveat: Not All Models Are Equal
A recent, rigorous benchmark on GitHub tested every llama.cpp speculative decode mode, ngram-cache, ngram-mod, and classic draft with a vocab-matched Qwen3.5-0.8B draft model, on a Qwen3.6-35B-A3B model running on an RTX 3090.
The result was unambiguous: “None of the spec-decode modes achieves net speedup over baseline.” Mean decode performance dropped 3-12%, with a severe bimodal tail dragging performance down to 59-67 tokens/sec on reasoning and code prompts, despite achieving 100% draft acceptance rates.
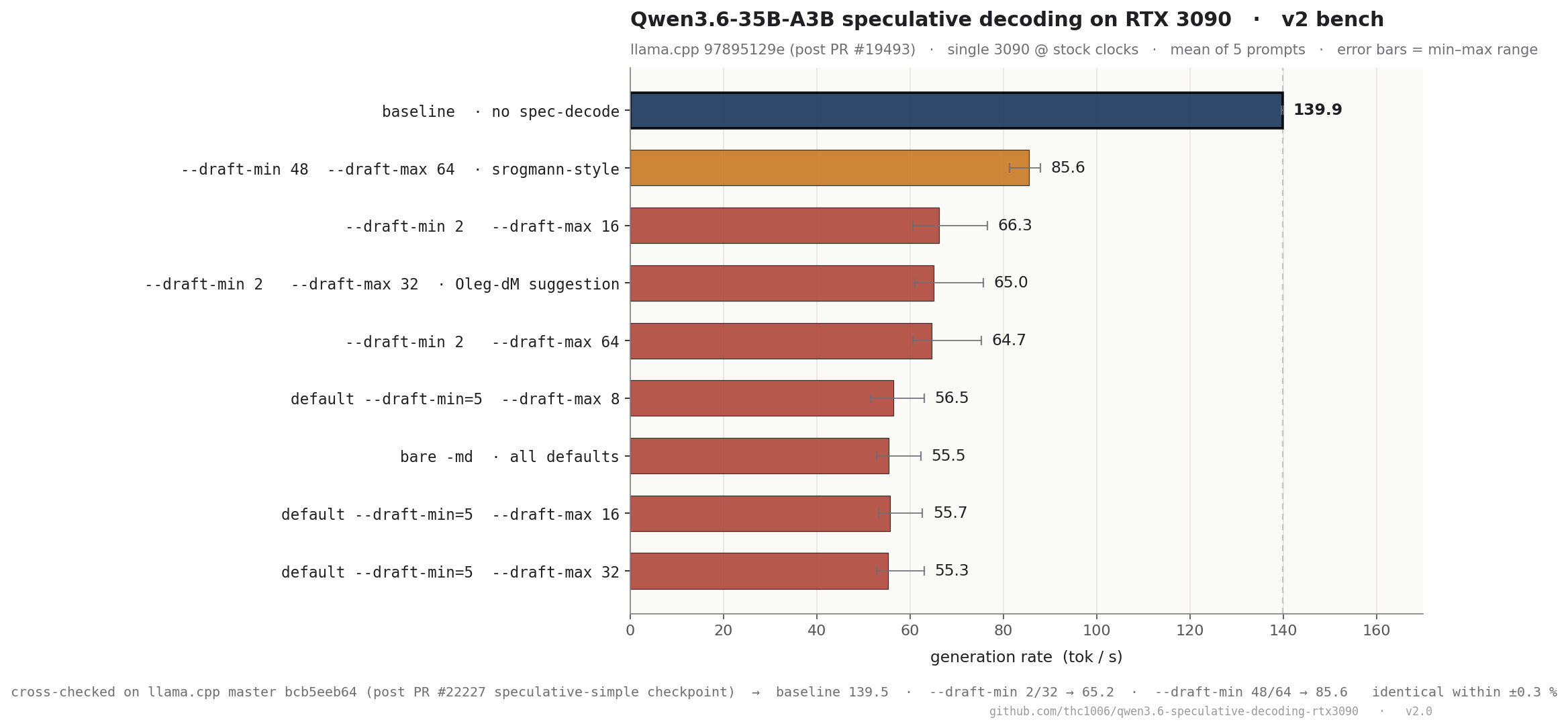
The benchmark’s conclusion is rooted in academic research like MoESD (arXiv 2505.19645). For an A3B model (only 3B active parameters routed from a 256-expert pool), the expert-saturation threshold is high (~94 tokens). With speculative draft sizes (K) far below this, each drafted token likely fetches a fresh, unique set of experts. On memory-bandwidth-limited consumer hardware like a 3090, the overhead of loading these expert slices for verification outweighs the savings from skipping token generation. Even perfect acceptance can’t save you.
This explains the paradox: while Qwen3.6-27B (a dense model) shines with speculative decoding, its MoE-based 35B sibling currently does not on the same hardware. It’s a critical nuance for anyone enabling local cloud-like API access through open-source tooling, model architecture dictates the viability of acceleration techniques.
The Deployment Matrix: It’s Not Just llama.cpp
ngram-mod is a flagship, but it’s not the only option.
vLLM offers a production-ready path. The official Qwen3.5 & Qwen3.6 Usage Guide provides optimized commands. For throughput, they recommend expert parallelism and the FP8 quant for the 397B-A17B model:
vllm serve Qwen/Qwen3.5-397B-A17B-FP8 \
-dp 8 \
--enable-expert-parallel \
--language-model-only \
--reasoning-parser qwen3 \
--enable-prefix-cachingFor latency-sensitive tasks, they suggest enabling MTP-1 speculative decoding: --speculative-config '{"method": "mtp", "num_speculative_tokens": 1}'.
SGLang offers another route, as shown on Qwen’s official GitHub: python -m sglang.launch_server --model-path Qwen/Qwen3.6-35B-A3B --port 8000 --tp-size 4 --context-length 262144 --reasoning-parser qwen3.
The message is clear: whether you need the raw speed of n-gram caching in llama.cpp or the robust serving features of vLLM, there’s a rapidly maturing toolchain ready to replace a cloud endpoint.
The Economic Calculus: Subscription Cancellation is the ROI
Running Qwen3.6-27B locally has a fixed, upfront cost: the GPU. An RTX 3090 can be had for under $800 second-hand. Even a new RTX 5090 laptop represents a one-time capital expenditure. After that, the incremental cost of inference is measured in pennies per hour of electricity, not dollars per API call.
This is the true “death” for Cloud AI SaaS: not an immediate extinction, but a growing economic irrelevance for a significant segment of users, specifically, developers, researchers, and privacy-conscious enterprises for whom latency, cost, and data control are paramount. It provides clear clues into why cloud-first architectures are collapsing under their own weight and cost structure.
The Horizon: What’s Next?
1. Better Draft Models: The community is eagerly awaiting integrated solutions like
z-lab/DFlash drafters and more efficient speculative techniques that can better handle MoE overhead.2. Hardware Consolidation: Multi-GPU consumer setups (like a 3090 paired with a 5070 Ti) are becoming more common, enabling tensor parallelism and larger model batches.
3. Tooling Maturation: Projects like Ollama, LM Studio, and continued improvements to llama.cpp are making these powerful optimizations accessible beyond the command-line elite.
The narrative that “bigger models require bigger clouds” is being rewritten, line by line, in open-source repositories and Reddit threads. The 27B parameter class, armed with speculative decoding and running on a last-generation gaming GPU, isn’t just a toy. It’s a viable, powerful, and economically superior alternative for a growing number of real-world tasks.
Cloud AI isn’t dead. But its monopoly on high-performance inference is looking increasingly terminal. The future isn’t just hybrid, it’s overwhelmingly local, and it’s running on hardware you already own.


