Machine learning executed purely at the hardware level with precomputed lookups.
Silicon-Scale AI: When Your Model Has 50 Nanoseconds to Live
CERN’s Large Hadron Collider generates roughly 40,000 exabytes of raw data annually, about a quarter of the entire current internet’s volume. Here’s the punchline: they throw away 99.98% of it. Not because they want to, but because storing hundreds of terabytes per second is physically impossible with existing technology. The surviving 0.02% makes it through only by surviving the most brutal real-time filtering system ever built, where AI models don’t run in containers, they’re literally burned into silicon, executing inference in under 50 nanoseconds. While the rest of the industry chases hybrid model architectures for inference and debates silicon-level performance benchmarks, CERN’s physicists solved the ultimate edge case: deciding whether to keep a particle collision before the light from the explosion has traveled 15 meters.

The Physics of Data Gluttony
Inside the 27-kilometer ring of the LHC, proton bunches smash into each other every 25 nanoseconds, creating a data firehose that would swamp even the most ambitious cloud infrastructure. Each collision generates several megabytes of raw detector data. Do the math: at peak luminosity, you’re looking at hundreds of terabytes per second flowing from the detectors. That’s not a big data problem, that’s a physics problem masquerading as an engineering nightmare.
The constraint isn’t compute budget, it’s the speed of light and the laws of thermodynamics. You can’t ship that volume to AWS, Azure, or even a local data lake. By the time the first packet hit a network interface, the next thousand collisions would have already happened, unrecorded and lost forever. This isn’t constrained silicon hardware inference, this is constrained-by-reality inference, where “latency” is measured against subatomic particle decay times.
The solution? Move the intelligence to the edge, literally. Not the “edge” of a corporate IoT marketing deck, but the edge of the detector itself, where 1,000 field-programmable gate arrays (FPGAs) make life-or-death decisions for data packets in less than 50 nanoseconds.
Why GPUs Choke and FPGAs Fly
Here’s where CERN’s architecture diverges from the mainstream AI narrative. While NVIDIA’s latest high-performance workstation realities involve cooling 2,070 FP4 TFLOPS Blackwell modules and managing RDMA over dual 200 GbE networks, CERN operates in a different universe. The IGX Thor platform might handle rewriting rules of efficient AI inference for industrial robotics, but it would drown in the LHC’s data tsunami. The issue isn’t throughput, it’s the tyranny of the nanosecond.
GPUs excel at parallel batch processing. They’re optimized for throughput, for chewing through massive matrices with high arithmetic intensity. But they suffer from what hardware architects call “jitter”, variability in response time caused by memory hierarchies, OS scheduling, and thermal throttling. In autonomous vehicles or medical imaging, a few milliseconds of jitter might be acceptable. At CERN, 50 nanoseconds is the hard deadline. Miss it, and the data is gone, the physics event erased from history.
FPGAs win here because they trade flexibility for determinism. When CERN burns a model into an FPGA, they’re not running Python inference on a Linux kernel. They’re creating a physical circuit path where electrons flow through logic gates with picosecond precision. No context switches. No garbage collection. No “cloud-native” overhead.
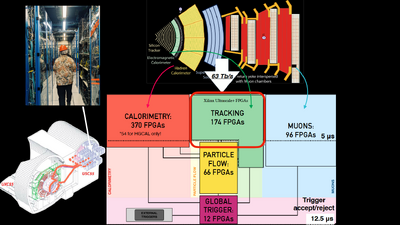
AXOL1TL: The Algorithm That Eats Physics
The star of this silicon circus is AXOL1TL, an algorithm whose name sounds like a keyboard smash but represents the bleeding edge of rewriting rules of efficient AI inference. Unlike the billion-parameter behemoths dominating the AI headlines, AXOL1TL is microscopic by design. It has to be, it runs on the Level-1 Trigger, that army of 1,000 FPGAs sitting between the detectors and oblivion.
The technical stack reveals CERN’s hardware-first philosophy. Using HLS4ML, an open-source tool that translates PyTorch and TensorFlow models into synthesizable C++, the team compiles neural networks into hardware description languages. But here’s the clever part: a substantial portion of the FPGA resources aren’t dedicated to neural network layers at all. Instead, they’re allocated to precomputed lookup tables, massive banks of memory storing the results of common input patterns. For the vast majority of detector signals, the “inference” is just a memory lookup: address in, decision out, nanoseconds elapsed.
This is machine learning reduced to its absolute essence. No floating-point calculations, no matrix multiplications, no batching. Just pure, digital reflex. When a collision occurs, the detector signals hit the FPGA, the lookup table spits out a verdict, and the data is either routed downstream or deleted forever, all before the next proton bunch crosses paths 25 nanoseconds later.
The Two-Stage Gauntlet: From Nanoseconds to Milliseconds
Surviving the Level-1 Trigger doesn’t mean you’re safe. The 0.02% of events that make it past the FPGAs face a second, equally brutal filter: the High-Level Trigger. This is where the architecture shifts from dedicated silicon to general-purpose compute, but the scale remains absurd.
The High-Level Trigger operates from a surface-level computing farm packing 25,600 CPUs and 400 GPUs. Even after the FPGAs have done their brutal culling, this farm still ingests terabytes per second. It’s here that more conventional AI inference happens, anomaly detection, track reconstruction, particle identification, running at latencies that would seem glacial to the Level-1 Trigger (microseconds to milliseconds) but would make a cloud architect weep (real-time processing of TB/s streams).
This two-stage architecture offers a masterclass in hardware-software co-design. The FPGAs handle the “embarrassingly parallel” filtering with hard real-time constraints, while the CPU/GPU farm handles the “embarrassingly complex” physics reconstruction with soft real-time constraints. It’s a division of labor that respects the fundamental limits of each substrate: silicon for speed, general compute for flexibility.
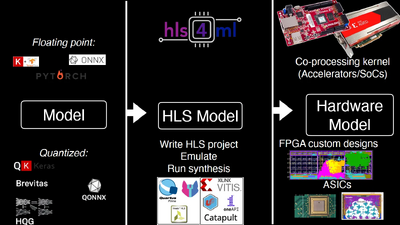
The 2031 Problem: When 40,000 Exabytes Becomes 400,000
The current LHC is scheduled for the High-Luminosity upgrade (HL-LHC) in 2031, and the numbers get silly. Ten times the data per collision. Ten times the event complexity. The data rate will push into the petabytes per second range, rendering current filtering strategies obsolete.
CERN’s response isn’t to buy bigger GPUs or rent more cloud instances. They’re doubling down on “tiny AI”, ultra-compact models optimized for direct hardware implementation. While the industry chases trillion-parameter models and hybrid model architectures for inference, CERN is pioneering the art of the possible in minimal silicon footprints. They’re proving that when your constraint is the speed of light through a wire, model compression isn’t just an optimization, it’s the only way to survive.
This forward-looking work involves next-generation FPGA and ASIC implementations, with ASICs (application-specific integrated circuits) offering even lower latency and power consumption than FPGAs, albeit with zero flexibility once fabricated. It’s a bet on specialization over generalization, on physics over flexibility.
Lessons for Mortals: Why Your “Real-Time” Isn’t Real-Time
What does this mean for practitioners building edge AI systems in factories, hospitals, or autonomous vehicles? First, it challenges the assumption that bigger models are better models. CERN’s approach demonstrates that constrained silicon hardware inference isn’t just about fitting a 70B parameter model into 128GB of unified memory, it’s about understanding exactly which operations need to happen in hardware and which can be precomputed into lookup tables.
Second, it highlights the cost of abstraction. Every layer of software between your model and the silicon, containers, Kubernetes, Python interpreters, CUDA drivers, adds latency that compounds. CERN’s stack goes from high-level ML frameworks (PyTorch) to synthesizable C++ to logic gates, eliminating every possible indirection. For applications where milliseconds matter (autonomous driving, high-frequency trading, medical imaging), this “zero-overhead” philosophy offers a blueprint.
Third, it reveals the future of edge AI isn’t just about moving compute closer to data, it’s about embedding compute into the data path. The AXOL1TL algorithm doesn’t fetch data from memory, it is the memory. As we approach the limits of Moore’s Law and memory bandwidth bottlenecks strangle GPU performance, this “compute-in-memory” approach may become the standard for rewriting rules of efficient AI inference, not just a particle physics curiosity.
The Counter-Narrative: When FPGAs Fail
Of course, CERN’s approach has limitations that would terrify a typical software engineer. FPGAs are expensive, power-hungry, and notoriously difficult to program. The HLS4ML toolchain, while impressive, requires hardware expertise that most ML engineers lack. And once you burn a model into an ASIC, it’s immutable, no fine-tuning, no A/B testing, no “hotfix” deployments on Friday afternoon.
This rigidity is anathema to modern MLOps practices. But CERN operates in a domain where the physics don’t change, protons collide the same way today as they did yesterday. For businesses operating in dynamic environments where models need weekly retraining, CERN’s approach would be overkill, perhaps even dangerous. The wisdom lies in knowing when to apply silicon-level determinism and when to embrace the flexibility of GPU clouds.
Conclusion: The Anti-Hype Engine
CERN’s silicon-scale AI represents a humbling reality check for an industry obsessed with scale. While venture capital flows toward ever-larger foundation models and high-performance workstation realities dominate tech news cycles, the most demanding AI deployment in the world runs on models so small they fit into lookup tables, executing on hardware that predates the Transformer architecture.
The LHC doesn’t care about your parameter count. It cares about whether you can decide, in 50 nanoseconds, whether a collision contains the ghost of a Higgs boson or just noise. That decision, made a billion times per second by circuits etched in silicon, is the purest form of AI inference: no hype, no hallucinations, just physics and math burned into hardware that separates signal from noise at the edge of existence.
As we push toward the HL-LHC era and beyond, CERN’s work suggests that the future of real-time AI isn’t in the cloud, or even at the edge. It’s inside the silicon itself, where the only latency that matters is the time it takes electrons to traverse a logic gate. Everything else is just waiting.