Nvidia’s Nemotron 3 Super dropped this week to a collective shrug from the benchmark-obsessed crowd. Trailing Alibaba’s Qwen3.5 on standard leaderboards, the 120B-parameter model seemed destined to be another footnote in the open-source LLM race. But beneath the modest benchmark scores lies an architectural blueprint designed to commoditize AI inference and cement Nvidia’s hardware dominance. With native 4-bit training, a hybrid Mamba-2 transformer backbone, and a “top-22” MoE routing strategy that essentially requires Blackwell silicon to run efficiently, this isn’t just a model release, it’s a calculated ecosystem play that could reshape how enterprises deploy AI.
The Benchmark Trap (Why 85.6% is Actually Impressive)
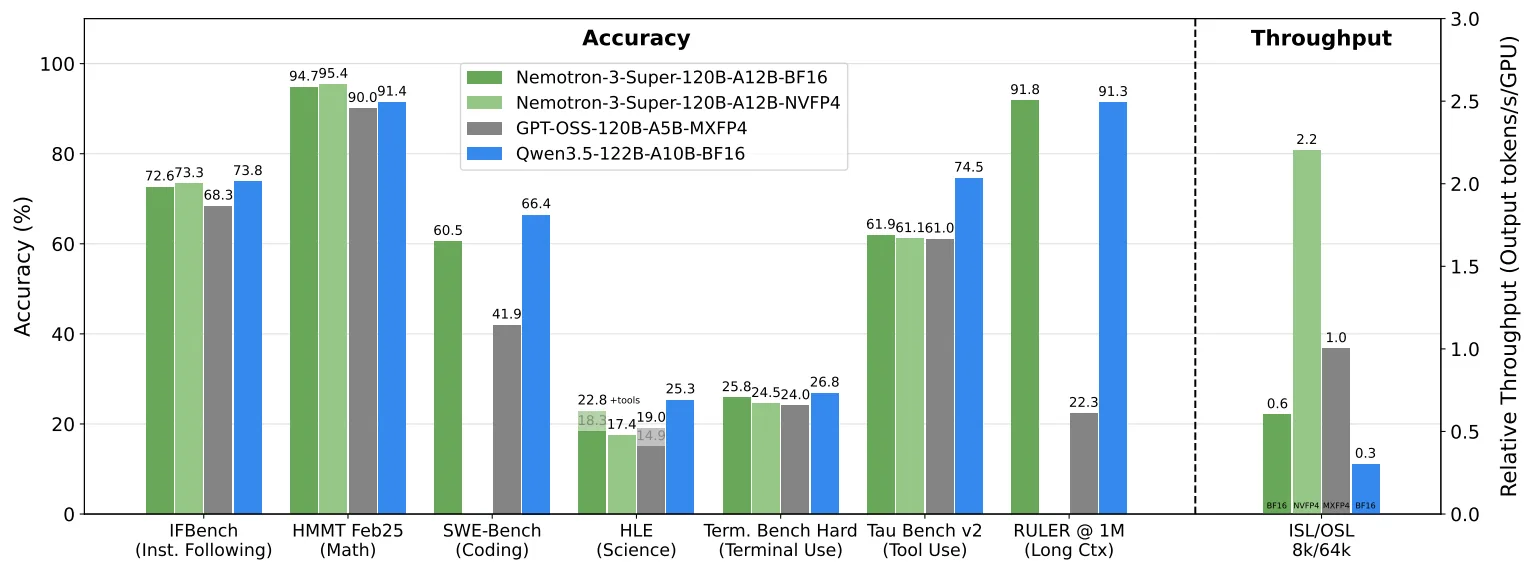
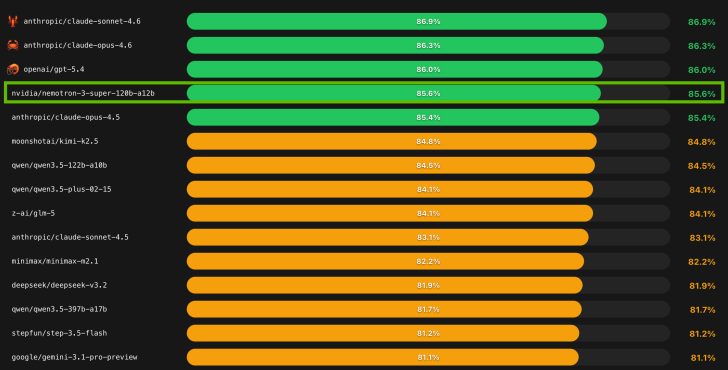
Let’s get the leaderboard anxiety out of the way first. Yes, Nemotron 3 Super trails Qwen3.5-122B-A10B on traditional benchmarks. The model ranks fourth on several standard suites, which in today’s hype cycle is practically invisible. But here’s where the narrative shifts: on PinchBench, a suite specifically designed to evaluate agentic workloads, Nemotron 3 Super scored 85.6%, surpassing Claude Opus 4.5, Kimi 2.5, and GPT-OSS 120B.
The real kicker? This performance comes with a quantization profile that should, by all rights, destroy accuracy. Nvidia pre-trained this model natively in 4-bit precision (NVFP4) on 10 trillion tokens. The degradation from the 16-bit version to 4-bit is practically nonexistent, across MMLU and long-context retrieval (RULER), the 4-bit model retains approximately 99.8% of the base model’s accuracy. In subjective evaluations like Arena-Hard-V2, the quantized version actually scored slightly higher than its full-precision sibling.
This isn’t a bug, it’s the entire point. While other labs are optimizing for leaderboard glory, Nvidia optimized for the messy reality of enterprise deployment where memory bandwidth costs money and every watt counts.
Architecture: When Three Paradigms Collide
Nemotron 3 Super isn’t just another transformer with a MoE slapped on top. It’s a Frankensteinian hybrid of three distinct architectural philosophies, each solving a specific hardware bottleneck that pure transformer architectures hit at scale.
LatentMoE: Routing in the Compression Domain
Standard Mixture of Experts models hit a memory bandwidth wall because they route tokens in their full hidden dimension (typically 4096 or 8192). Nemotron 3 Super implements LatentMoE, projecting tokens from the model dimension (d=4096) into a compressed latent space (ℓ=1024) before any routing occurs. This reduces both parameter loads and all-to-all GPU communication by a factor of four.
The result? The model scales to 512 experts with an aggressive top-22 routing strategy without the usual inference-time penalty. You’re essentially getting the capacity of a massive ensemble model while only activating 12 billion parameters per token.
The Mamba-2 Hybrid: Linear Time, Massive Context
The 88-layer backbone is built heavily upon Mamba-2 state space models, which process sequences in linear time with constant memory usage. But pure state space models struggle with exact associative recall, so Nvidia interleaves sparse self-attention layers as “global anchors” throughout the stack.
This hybrid approach enables the model to maintain a 1-million-token context window without the quadratic KV cache explosion that cripples traditional transformers. For context, that’s four times the window of Kimi 2.5, achieved with roughly half the active parameters of comparable dense models. Previous iterations like Nemotron Nano 2 hinted at this direction, but Super represents the full realization of the architecture.
Native NVFP4: Hardware-Software Co-Design
Here’s where the hardware agenda becomes undeniable. Nemotron 3 Super wasn’t just quantized post-training, it was pre-trained natively in 4-bit using Nvidia’s proprietary E2M1 format. The implementation uses a two-tier scaling system: every 16 numbers share a local E4M3 scale for detail preservation, while a high-precision FP32 global scale maintains system integrity.
To prevent gradient underflow at this precision, the training pipeline applies Random Hadamard Transforms to weight gradients, dispersing magnitude outliers that would otherwise collapse training. This is precision engineering designed specifically for Blackwell’s native FP4 execution units. Running this model on non-Nvidia hardware is technically possible, but about as efficient as using a Ferrari to tow a boat.
Multi-Token Prediction: Native Speculative Decoding
The model utilizes two Multi-Token Prediction (MTP) layers with shared parameters, trained to predict multiple future tokens in a single forward pass. Unlike external draft models that add architectural bloat and latency, this acts as “native speculative decoding”, accelerating generation for long-horizon agentic workflows without additional memory overhead.
The Workhorse Thesis: Local Inference That Doesn’t Suck
All this architectural gymnastics serves one practical goal: making large-scale inference viable on commodity hardware. Early benchmarks show the 4-bit Nemotron 3 Super maintaining approximately 62 tokens per second at a 512,000-token context window on a single RTX Pro 6000. The speed drop from 1K context to 512K context is only 11%, a feat that would require a small data center of GPUs for a traditional dense model.
API providers hosting this model are already offering 400+ TPS, placing it in the “AI Accelerator” tier typically reserved for specialized inference services. For enterprises, this changes the calculus entirely. You can now run a 120B-parameter agentic workhorse locally for the cost of a high-end workstation GPU, diverting load away from frontier API providers entirely.
This efficiency builds on the foundation laid by Nemotron-3-Nano’s surprising performance, where we saw smaller parameter counts beating larger models through architectural innovation. Super scales that philosophy to enterprise workloads.
Open Source or Open Washing?
Nvidia isn’t shy about the “open” branding here, and to their credit, they’ve released more than just weights. The package includes the full 10 trillion token pre-training datasets, 40 million post-training supervised and alignment samples, 21 RL environment configurations, and complete evaluation recipes. This drops the cost of training custom mid-tier models well within startup budgets.
However, the licensing story has been… evolving. The initial release included what the community quickly dubbed a “Rug-Pull” license, allowing Nvidia to unilaterally update terms and including aggressive patent retaliation triggers. Following community pushback, Nvidia switched to a more permissive license that removes the “may update this Agreement at any time” language. The only remaining termination clause triggers if you sue Nvidia, which is standard for open-source code licenses but still worth noting.
The prevailing sentiment among developers is cautious optimism tempered by corporate realism. Yes, you can fine-tune this on your own data using frameworks like Unsloth, but you’re still buying into an ecosystem optimized for Nvidia’s hardware roadmap.
Commoditize Your Complement (The Joel Spolsky Play)
Which brings us to the uncomfortable truth: this release makes perfect sense if you view it through the lens of Joel Spolsky’s “Commoditize Your Complement” strategy. By open-sourcing state-of-the-art training infrastructure and highly optimized 4-bit models, Nvidia is simultaneously lowering barriers to entry and fracturing the software moats of traditional model builders like OpenAI and Anthropic.
The strategy is elegant in its cynicism. Nvidia doesn’t need to own the model layer, they need to own the infrastructure layer. By making powerful models ubiquitous and cheap to run, they create demand for the one thing they truly monopolize: the silicon required to run them efficiently. It’s the classic “burying gold and selling maps” play, except the gold is open weights and the maps are RTX Pro 6000s and GB10 boxes.
This explains why Nvidia is one of the few Western companies consistently releasing competitive open models while giants like Google and OpenAI keep their weights locked away. They can afford to commoditize the software because every deployment, whether on a workstation or in a hyperscale data center, drives hardware sales. The Nano series was the proof of concept, Super is the enterprise-scale execution.
What This Means for Practitioners
For AI engineers and enterprise architects, Nemotron 3 Super represents a fork in the road. You can now deploy genuinely capable agentic systems, models that beat Opus 4.5 on agentic benchmarks, entirely on-premise for hardware costs that fit in a departmental budget. The 1M context window and efficient 4-bit inference make it viable for document analysis, code generation, and multi-step reasoning workflows that previously required API calls to closed providers.
But you’re also buying into a hardware ecosystem. The NVFP4 optimization, while delivering stunning efficiency, is a subtle form of vendor lock-in. Run this on AMD or Intel accelerators and you’ll pay a performance penalty that makes the “open” weights feel less like a gift and more like a Trojan horse.
The model is a workhorse, not a show pony. It won’t top the LMSYS leaderboard, but it will process your 500-page legal contracts at 60 tokens per second on a single GPU without phoning home to San Francisco. For many enterprises, that’s a trade worth making, even if it means writing Jensen Huang a bigger check for hardware next quarter.