The local LLM community just got a reality check. While everyone chased parameter counts, packing 70 billion weights into increasingly complex quantization schemes, NVIDIA dropped Nemotron-3-nano 30B, a model that delivers superior reasoning performance with roughly half the parameters of Meta’s Llama 3.3 70B. Early benchmarks and developer reports suggest this isn’t a fluke, it’s a fundamental architectural advantage.
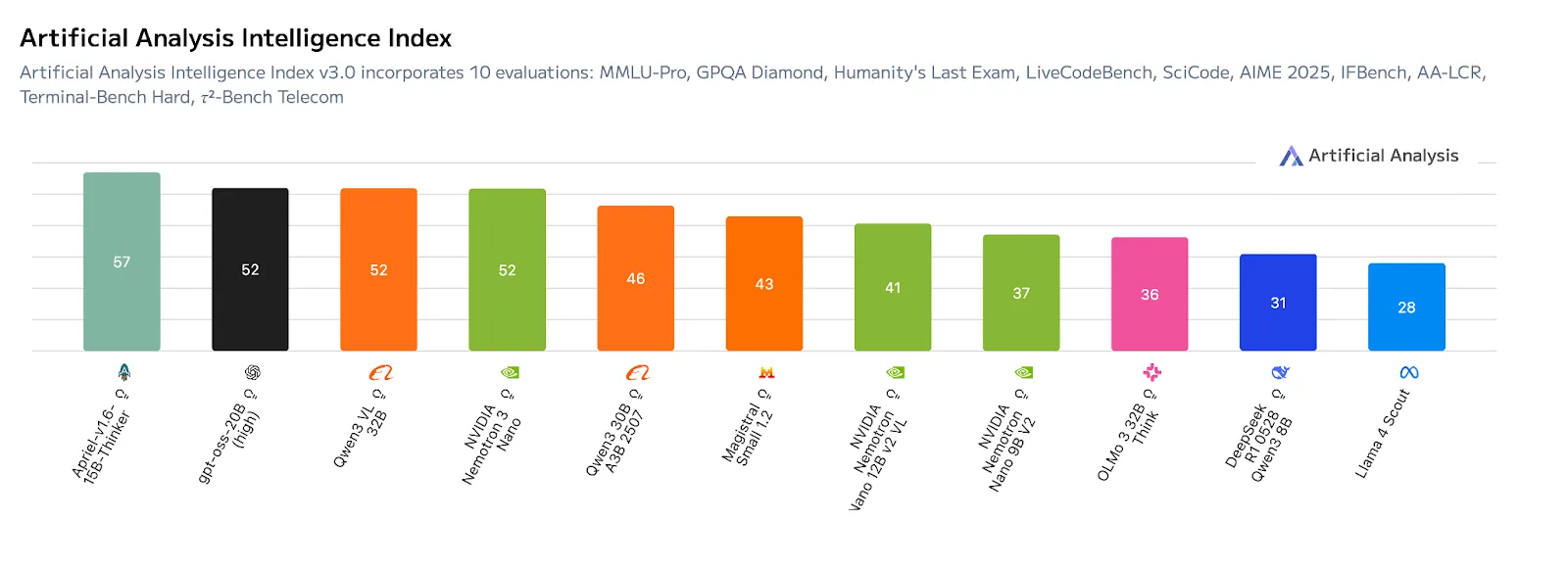
The numbers from Artificial Analysis tell a stark story. Nemotron-3-nano achieves an Intelligence Index score of 52, placing it at the top of its weight class while maintaining throughput efficiency that makes larger models look sluggish. The graph plotting intelligence against tokens per second shows Nemotron-3-nano occupying an enviable position: high accuracy without the typical speed penalty.
The Architecture That Makes It Possible
Nemotron-3-nano’s secret isn’t magic, it’s a deliberate design choice to abandon the “more parameters equals better performance” orthodoxy. The model uses a hybrid Mamba-Transformer mixture-of-experts (MoE) architecture that fundamentally rethinks how tokens get processed.
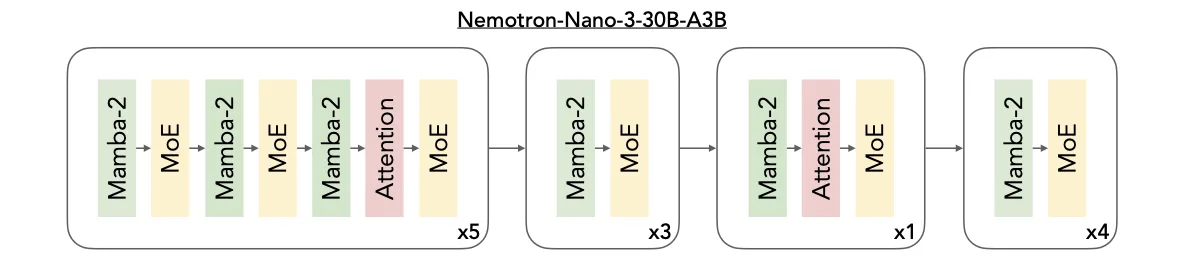
The pattern is telling: 5 repetitions of Mamba-2/MoE pairs with one attention layer, followed by 3 Mamba-2/MoE pairs, then 1 block with attention, and finally 4 Mamba-2/MoE pairs ending with a single Mamba-2 layer. This isn’t your standard transformer stack. By minimizing expensive self-attention layers and leaning on Mamba-2’s constant-state sequence modeling, the architecture slashes memory overhead while preserving reasoning capability.
The MoE component activates only 3 billion parameters per token from the total 30 billion, creating a sparsity pattern that cuts compute costs without sacrificing model capacity. For local deployment, this means you get the knowledge base of a much larger model while only paying the inference cost for a fraction of its parameters.
Real-World Performance: Developer Reports vs. Marketing Claims
Developer communities have been stress-testing Nemotron-3-nano since release, and the consensus is unusually positive. Multiple reports confirm the model’s reasoning quality surpasses Llama 3.3 70B on technical tasks, Linux configuration, scripting, information retrieval, while maintaining a lean memory footprint.
One developer running the model on an M4 Pro with 48GB RAM reported 70 tokens per second at 96K context, a throughput number that would make many larger models choke. The model’s training cutoff of November 28, 2025, gives it fresher technical knowledge than most competitors, a subtle but significant advantage for coding and system configuration tasks.
However, there’s a catch: Nemotron-3-nano is extremely quantization-sensitive. The same sparsity that makes it efficient also makes it brittle. Developers report noticeable quality degradation with even modest quantization, and KV cache compression introduces artifacts that larger models tolerate better. The relative loss difference between NVFP4 and BF16 training is under 1%, but that precision doesn’t translate to post-training quantization robustness.
The Robotic Tone Trade-off
NVIDIA’s reinforcement learning strategy using NeMo Gym, training across multi-environment agentic tasks, produces models optimized for structured reasoning, not conversational warmth. The “robotic” tone developers describe isn’t a bug, it’s the result of training on tool-use, code generation, and verifiable reasoning tasks rather than chat logs.
For research and analysis workflows, this is ideal. The model stays focused, provides structured outputs, and doesn’t wander into creative storytelling. For general-purpose chat, it’s a limitation. You can lower the temperature to 0.1 and get clinical precision, but you won’t get the natural back-and-forth of a model trained on conversational data.
The Quantization Sensitivity Problem
Here’s where the efficiency story gets complicated. Nemotron-3-nano’s 30 billion parameters compress well in theory, but in practice, developers report that any quantization beyond the native NVFP4 format introduces noticeable degradation. The KV cache is particularly sensitive, compressing it aggressively destroys the model’s ability to maintain coherence over long contexts.
This creates a deployment paradox: you need high-end hardware to run the model at full precision, negating some of the efficiency gains. On a 5090 with 128GB RAM, you can handle the 100B variant’s 10B active parameters and keep everything in fast memory. On consumer hardware, you’re forced into quantization that erodes the very performance you’re chasing.
The Roadmap: Super and Ultra Variants
NVIDIA isn’t stopping at nano. The Super and Ultra variants promise latent MoE, a technique that projects tokens into a smaller latent dimension before routing, enabling 8 experts instead of 4 while reducing all-to-all communication overhead. This architecture change could solve the quantization sensitivity by making the model more robust to precision changes.
Multi-token prediction (MTP) adds another layer of efficiency, letting the model generate several future tokens in a single forward pass. For agentic workflows generating structured plans or code, this translates to measurable latency reductions. The architecture uses a shared trunk with independent output heads, each predicting successive tokens, a design that naturally enables speculative decoding without a separate draft model.
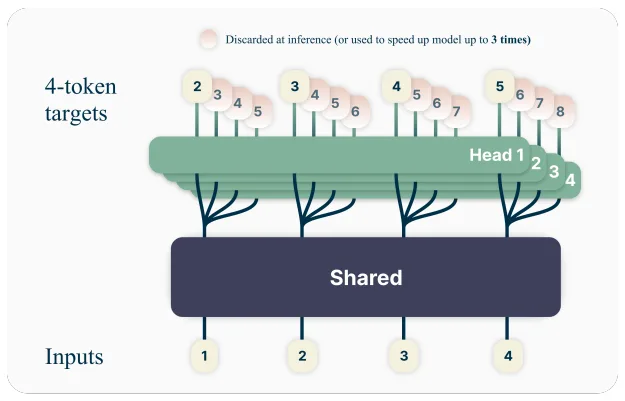
Deployment Reality Check
Running Nemotron-3-nano locally isn’t trivial. The model expects DGX Spark, H100, or B200 GPUs for optimal performance, though developers are making it work on RTX cards through llama.cpp and LM Studio. The 1M-token context window is theoretical for most users, practical limits depend on your VRAM and patience.
For voice agents, combining Nemotron-3-nano with the Nemotron Speech 0.6B ASR model yields sub-500ms voice-to-voice latency, but this requires careful orchestration. The ASR model’s 24ms final-transcript latency is impressive, but the overall pipeline latency includes token generation time, which varies wildly based on context length and hardware.
What This Means for Local AI
Nemotron-3-nano represents a shift from “bigger is better” to “smarter is better.” The model proves that architectural innovation can outpace raw parameter scaling, at least for specific tasks. For developers building agentic systems, research tools, or technical assistants, it offers 70B-class reasoning with 30B-class resource requirements.
The catch is specialization. This isn’t a drop-in replacement for general-purpose models. It excels at structured tasks and struggles with open-ended creativity. It’s also unforgiving about deployment precision, this is a model for engineers who can manage hardware constraints, not for casual users clicking “download” in a chat UI.
If you’re running local AI for technical work, Nemotron-3-nano deserves a serious look. Just don’t expect it to write poetry. And budget for hardware that can handle its precision demands, this efficiency breakthrough isn’t free, it’s just differently priced.