The cloud bill for your AI startup is probably trying to kill you. Running inference on large language models at scale has become a game of financial Russian roulette where every token generated eats another slice of your runway. While the frontier models keep getting larger, 400B parameters is the new normal, your GPU budget isn’t. Enter extreme quantization: the engineering discipline of cramming massive models into impossibly small spaces without turning them into gibberish-producing Markov chains.
Recent breakthroughs aren’t just incremental improvements, they’re fundamental shifts in what’s computationally possible. Google’s TurboQuant just proved you can compress key-value caches to 3-bit precision with zero accuracy loss, while Flash-Moe demonstrated that a 397-billion-parameter model can run on a MacBook Pro with 48GB of RAM. The implications for distributed inference architecture aren’t subtle, they’re rewriting the cost structure of AI deployment entirely.
The Mathematics of Extreme Compression
TurboQuant isn’t your grandfather’s quantization scheme. Traditional vector quantization carries a hidden tax: calculating and storing full-precision quantization constants for every block of data adds 1-2 extra bits per number, partially defeating the purpose. Google’s approach eliminates this memory overhead entirely through a clever two-stage pipeline that combines PolarQuant and Quantized Johnson-Lindenstrauss (QJL).
First, PolarQuant rotates data vectors randomly to simplify geometry, then converts from Cartesian coordinates (X, Y, Z distances) to polar coordinates (radius + angle). Think of it as replacing “Go 3 blocks East, 4 blocks North” with “Go 5 blocks at a 37-degree angle.” Because the angle patterns are highly concentrated and predictable, the model eliminates expensive data normalization steps and the memory overhead that comes with them.
The second stage applies QJL to the residual error. QJL uses the Johnson-Lindenstrauss Transform to shrink high-dimensional data while preserving essential relationships, reducing each vector to a single sign bit (+1 or -1). This creates a “high-speed shorthand” requiring zero memory overhead. The result? 6x memory reduction (3-bit quantization) with faster runtime than the original unquantized models on H100 GPUs, up to 8x speedup for attention logits.
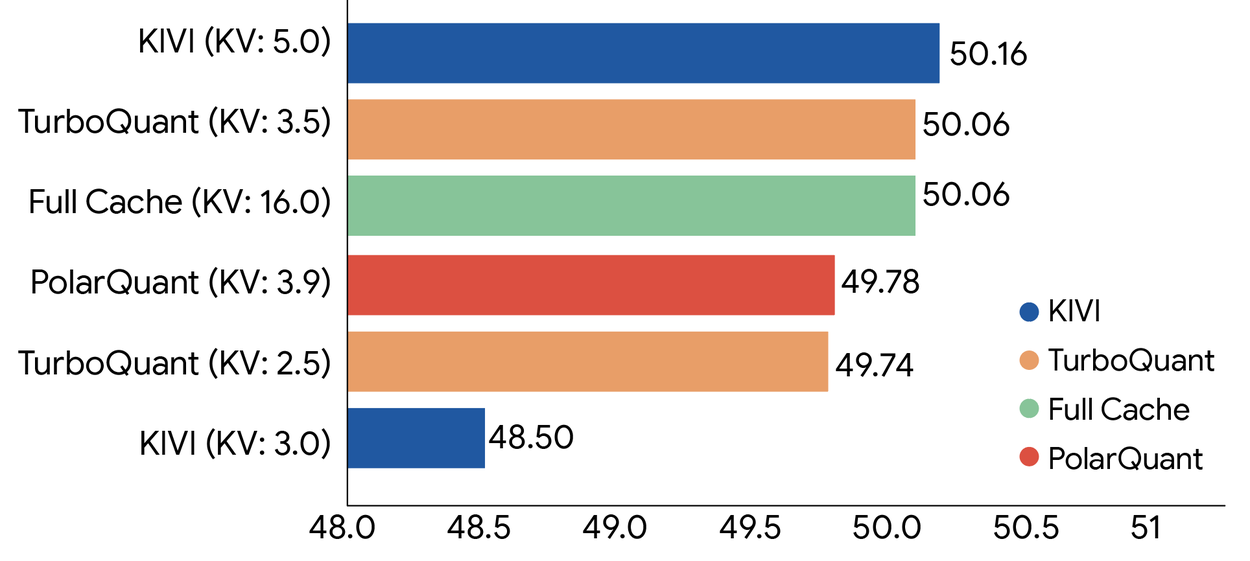
The benchmarks tell a stark story. On LongBench and Needle-in-Haystack tests using Llama-3.1-8B-Instruct, TurboQuant achieves perfect downstream results while reducing KV cache memory by a factor of six. For vector search applications, a critical component of modern RAG systems, TurboQuant achieves superior 1@k recall ratios compared to state-of-the-art methods like PQ and RabbiQ, despite those baselines using inefficient large codebooks and dataset-specific tuning.
When 397 Billion Parameters Fit in Your Lap
If TurboQuant represents the theoretical pinnacle, Flash-Moe represents the practical reality check. Released in March 2026, this pure C/Metal inference engine runs Qwen3.5-397B, a 397B parameter Mixture-of-Experts model, on consumer hardware with 48GB RAM, delivering 4.36 tokens per second with full tool-calling support.

The trick isn’t just quantization, it’s architectural violence. Flash-Moe exploits the MoE architecture’s sparse activation patterns, only 2% of weights activate per token, by pruning active experts from 512 down to 4 per token with no quality degradation. It keeps only 5.5GB of non-expert weights (embeddings, routing matrices) resident in memory-mapped RAM, while streaming the remaining expert weights from SSD on-demand via parallel pread() calls.
Each expert weighs roughly 6.75MB at 4-bit quantization. Loading 4 experts from SSD takes 2.41ms, 56% of the total layer processing time, while the macOS page cache naturally achieves a 71% hit rate for frequently accessed experts. Attempts to implement custom caching actually hurt performance by 38%, a humbling reminder that sometimes the OS knows better than your hand-optimized Metal shaders.
The economics are brutal for cloud providers. A $3,500 MacBook Pro M3 Max breaks even against cloud APIs in 18-22 months for heavy users processing 2M+ tokens daily. For high-performance architectures designed specifically for edge devices, this shifts the feasibility boundary from 70B models to 400B+ on consumer hardware.
The Quantization Fidelity Minefield
Not all bit-crushing is created equal. While Flash-Moe achieves production viability at 4-bit, the project documented 58 failed optimization attempts, including a sobering discovery: 2-bit quantization hits 5.74 tok/s (30% faster than 4-bit) but produces malformed JSON output (\name\ instead of "name"), breaking tool-calling entirely. For agentic applications requiring structured data, 2-bit is unusable despite the impressive speed numbers.
This reveals a critical tension in extreme quantization: the fidelity cliff. When evaluating quantization methods, filename conventions like “Q4_K_M” promise consistency that doesn’t exist in reality. Evaluating quantization fidelity metrics like KL divergence becomes essential, perplexity and KL divergence against the full-precision model are your only reliable friends in the GGUF wild west.
The choice between Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT) defines your strategy. PTQ is the pragmatist’s choice: calibrate on a representative dataset, compute scaling factors, deploy in minutes. It works brilliantly for large models where quantization noise averages out. But when you push below 8-bit, into the realm of 4-bit and 3-bit extremes, QAT becomes necessary. By simulating quantization noise during training using the Straight-Through Estimator (pretending rounding never happened during backprop), QAT hardens models against precision loss. The cost is significant: you need training infrastructure and time, but for extreme compression, it’s the only path to maintain accuracy.
Distributed Inference in the Quantized Era
These compression breakthroughs fundamentally alter distributed inference architecture. The traditional approach, massive centralized GPU clusters serving quantized weights to edge devices, assumes bandwidth is cheaper than compute. TurboQuant and Flash-Moe invert this assumption: when models compress by 6-10x and run efficiently on edge hardware, the latency and privacy costs of cloud round-trips become harder to justify.
For vector search and semantic indexing, TurboQuant enables building and querying billion-scale indices with minimal memory and near-zero preprocessing time. This isn’t just about saving RAM, it’s about enabling semantic search at Google’s scale without Google’s infrastructure budget.
Edge deployment strategies are evolving rapidly. Deploying compressed models directly in browsers via WebGPU is becoming viable for models that would have required server-class hardware months ago. Meanwhile, optimizing backend CUDA paths for local inference remains critical, even with perfect quantization, Flash Attention configurations can turn your local inference into a CPU-bound crawl if misconfigured.
The New Economics of Intelligence
The compression arms race has immediate implications for AI product strategy. Privacy-sensitive industries, legal, healthcare, finance, can now run frontier-class models on-premises without the cloud provider tax. The breakeven math favors local deployment at scale: 2M tokens daily makes a $3,500 workstation cheaper than APIs within two years, with the added benefit of keeping proprietary data off someone else’s computer.
But this isn’t a universal cloud-killer. Cloud APIs still offer 5-7x faster inference (20-30 tok/s vs 4.36) and higher capability for complex reasoning. The smart architecture hybridizes: use extreme quantization for high-volume, privacy-sensitive, or offline tasks, while reserving cloud APIs for variable workloads requiring maximum capability.
The “3-bit gauntlet”, achieving usable inference at 3-4 bit precision without accuracy loss, has been thrown. TurboQuant’s theoretical guarantees and Flash-Moe’s practical implementation prove that practical applications of extreme 2-bit compression are approaching, even if current 2-bit implementations remain too brittle for production. As AI becomes infrastructure rather than luxury, extreme quantization isn’t just optimizing costs, it’s democratizing access to intelligence itself.