
Academic disputes usually stay buried in peer review comments or terse footnotes. But when Jianyang Gao, first author of the RaBitQ papers, dropped a 534-upvote technical manifesto on r/LocalLLaMA last week, he didn’t just challenge a paper, he accused Google Research of running a sophisticated credibility heist. The target was TurboQuant, an ICLR 2026 spotlight paper promising 6x+ KV cache compression and 8x attention speedups on H100s. The allegation? That Google’s “novel” contribution was built on RaBitQ’s foundation while systematically obscuring that lineage through incomplete descriptions, unsupported theoretical claims, and benchmarking that compared their GPU implementation against a deliberately handicapped CPU baseline.
This isn’t just a catfight over citation counts. It cuts to the heart of how we evaluate quantization fidelity benchmarking metrics and the ethics of how extreme quantization reshapes AI economics. When the authors of a major Google Research blog post stand accused of academic misrepresentation, practitioners need to know whether the 3-bit compression they’re about to deploy is built on solid ground or sand.
The Three Accusations: Method, Theory, and Benchmark
Gao’s critique, delivered with the precision of someone who has spent years proving asymptotic bounds, breaks down into three specific failures of academic rigor. These aren’t vague complaints about “similar ideas”, they’re technical indictments backed by email timestamps and version control.
The CPU vs GPU Smoking Gun
Let’s be blunt about what “single CPU with multiprocessing disabled” means in the context of vector quantization benchmarks. It means the baseline was kneecapped. RaBitQ’s original implementation is highly optimized C++ designed for parallel execution. Running it on a single CPU core isn’t just slower, it’s a fundamentally different computational regime that ignores the algorithm’s architectural strengths.
When you compare that to TurboQuant running on an A100, you’re not measuring algorithmic efficiency, you’re measuring whether GPUs are faster than a single CPU core. The community reaction was swift and unforgiving. Developers who have faced similar benchmarking shenanigans in their own publication cycles noted that this particular methodological choice should have been fatal during peer review. Inequitable experimental environments don’t just skew results, they invalidate the entire empirical contribution.
The timeline makes this worse. These concerns were raised in May 2025, before the ICLR submission deadline. The authors had months to correct the record or provide comparable hardware benchmarks. Instead, when formally notified again on March 26, 2026, they agreed to fix only part of the issues, and only after the ICLR conference concluded. They also refused to acknowledge the structural similarity regarding the Johnson-Lindenstrauss transformation.
Technical Distinction or Distraction?
Despite the academic mudslinging, TurboQuant does introduce specific technical variations that its proponents argue justify the paper’s existence. The method combines PolarQuant, a polar coordinate transformation that eliminates per-block normalization overhead, with QJL (Quantized Johnson-Lindenstrauss), a 1-bit residual correction technique.
PolarQuant works by randomly rotating vectors so coordinates follow a concentrated distribution, then grouping pairs into radii and angles. Because the angle distribution is highly concentrated in high dimensions, it can be quantized aggressively without the expensive normalization steps that plague traditional Product Quantization. QJL then handles the residual error using a 1-bit unbiased inner-product estimator.
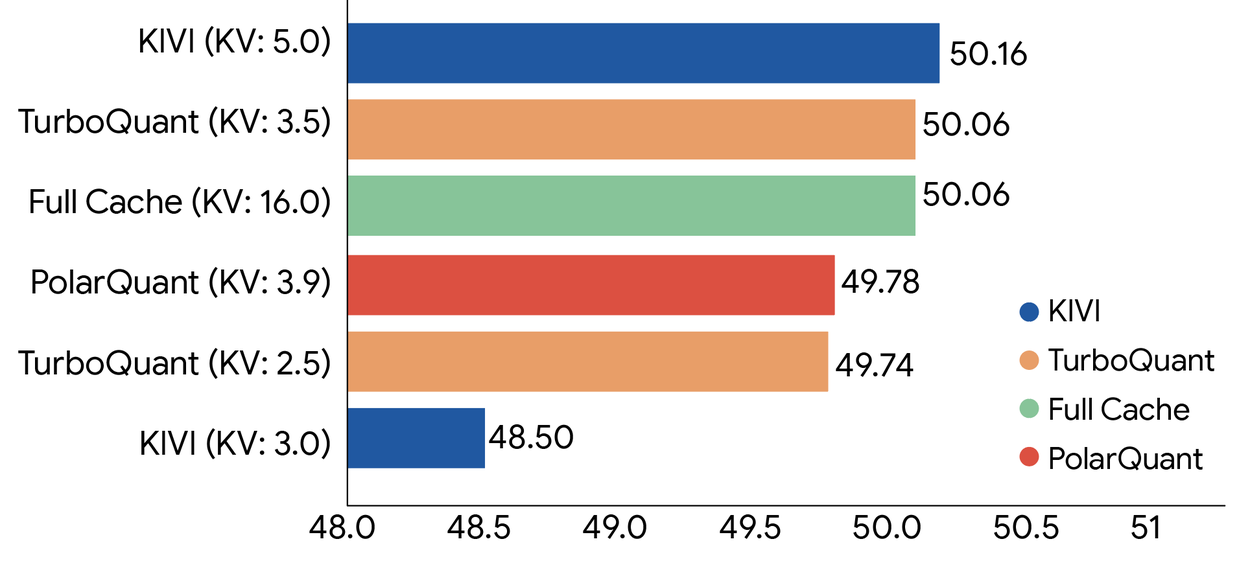
The independent implementation by developer Pidtom (unaffiliated with either research team) validates that this combination actually works in practice. Testing across Apple Silicon (M1-M5), NVIDIA (RTX 3080 Ti through DGX Spark Blackwell), and AMD hardware, the community has confirmed asymmetric q8_0-K + turbo4-V configurations achieve effectively lossless performance (+0.0-0.2% perplexity) across Llama, Qwen, Mistral, Gemma, Phi, and ChatGLM families. Real-world deployments show 4.57x KV memory compression with turbo3, turning an 8GB MacBook Air from an 800-token paperweight into a 4000-token capable machine.
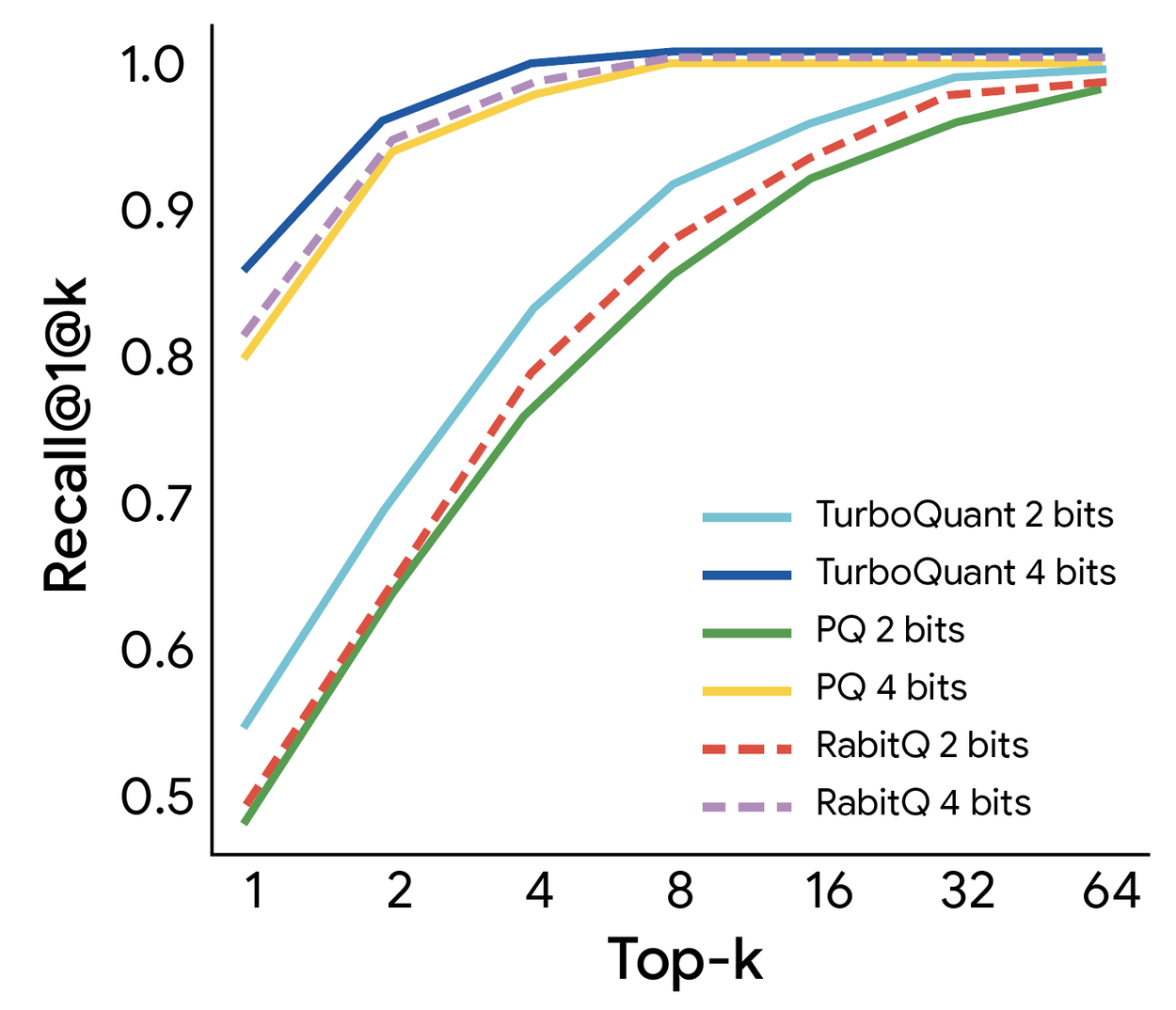
But here’s the uncomfortable question: are PolarQuant and QJL sufficient differentiators when the underlying rotation-and-quantize architecture matches RaBitQ’s approach? The GitHub repository for an independent TurboQuant implementation (0xSero/turboquant) reveals the core algorithm: random orthogonal rotation, Lloyd-Max optimal scalar quantization on Beta-distributed values, and QJL projection for residual sign bits. The combined estimator is provably unbiased, which is genuinely valuable. But the lineage is undeniable, TurboQuant stands on RaBitQ’s shoulders, and the accusation is that it refuses to admit how much weight it’s actually carrying.
What Practitioners Should Actually Care About
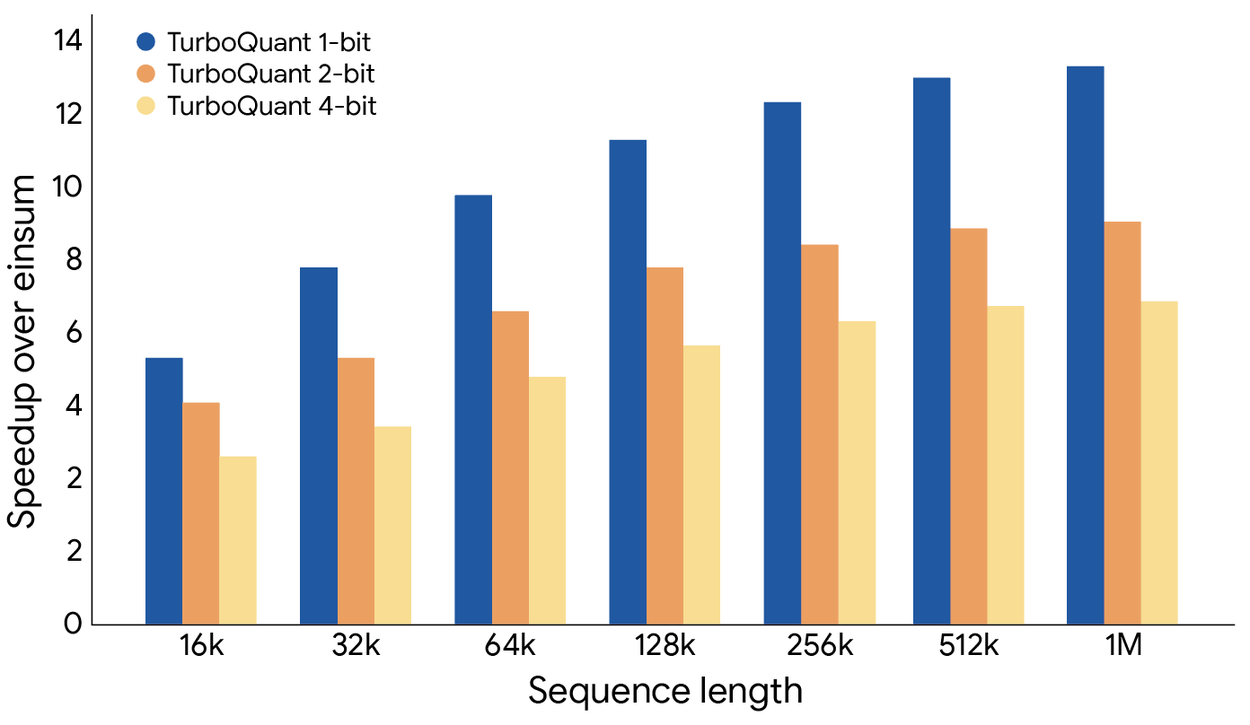
If you’re running inference on local LLMs, this controversy creates a practical dilemma. The technique works, the community has validated the 8x speedups on H100s and the 3-bit compression ratios. But the academic foundation is cracked. Do you adopt a method that might have ethical baggage attached?
The answer depends on your risk tolerance. The underlying mathematics of random rotation plus Lloyd-Max quantization is robust and well-established, predating both papers with roots in Hadamard transform work. The implementation details, specifically the polar coordinate transformation and 1-bit residual handling, are what make TurboQuant deployable at scale. An adversarial audit of the open-source implementation found that while claims of “5.1x compression” are slightly misleading (closer to 4.6x when accounting for overhead matrices), the method genuinely approaches the information-theoretic lower bound for quantization distortion.
For production systems, the hardware comparison issue is moot, you’ll be running either method on GPUs. The independent benchmarks show TurboQuant achieving 30.9% KV cache savings on MoE models and up to 77% (4.4x compression) on dense transformers. On an RTX 5090, this translates to freeing 30GB of VRAM and doubling context capacity from 457K to 914K tokens.
But the controversy serves as a reminder to verify the provenance of your quantization methods. When evaluating quantization fidelity benchmarking metrics, look for implementations that disclose their hardware baselines and normalization procedures. The RaBitQ team has requested that TurboQuant authors publicly clarify the method-level relationship between the two approaches, the theory comparison, and the exact experimental conditions underlying the reported RaBitQ baseline. Until that happens, practitioners should treat the original TurboQuant paper’s empirical claims with appropriate skepticism, even as they embrace the underlying technical innovations that the open-source community has already validated.
The broader lesson is about how extreme quantization reshapes AI economics. When a single bit of compression can determine whether your model runs on a $0.50/hour cloud instance or requires a $30,000 GPU cluster, the incentives to obscure prior art and claim novelty become immense. The TurboQuant controversy reminds us that in the race to minimize memory footprints, academic integrity is often the first thing to get compressed.



