
The 4B Model That Eats GPT-4’s Lunch: How Qwen 3.5 Rewrote the Edge AI Playbook

Small language models used to be the consolation prize for developers who couldn’t afford H100 clusters. You’d settle for a quantized 7B model that hallucinated like a sleep-deprived intern, pat yourself on the back for “local AI”, and quietly switch back to GPT-4 when nobody was looking.
Qwen 3.5 changes the calculus entirely. Its 4B parameter variant doesn’t just match last generation’s 9B models, it obliterates them while running at 60 tokens per second on a smartphone. Thanks to architectural innovations like Gated Delta Networks and Unsloth’s Dynamic 2.0 quantization, we’re witnessing the first true “edge-first” AI revolution that doesn’t require a data center in your pocket.
The End of the Parameter Arms Race
For years, the AI industry operated on a simple assumption: intelligence scales with size. If you wanted better reasoning, you stacked more layers. If you wanted multimodal understanding, you bolted on bigger vision encoders. The result? Models so bloated they require $30,000 GPU setups to run inference, turning “local AI” into a hobby for the financially blessed.

Qwen 3.5’s small series, 0.8B, 2B, 4B, and 9B parameters, represents a fundamentally different approach. Instead of compressing a large model until it fits, Alibaba’s team re-engineered from the ground up using a hybrid architecture that combines Gated Delta Networks with sparse Mixture-of-Experts (MoE). The 35B-A3B variant, for instance, contains 35 billion total parameters but activates only 3 billion at inference time. That’s not a typo, you get 35B model quality with 3B memory footprint.
The technical specs reveal how they pulled this off. The 2B model runs 24 transformer layers with a hidden size of 2048, but crucially includes a native context window of 262,144 tokens, extensible up to 1,010,000 tokens using RoPE scaling techniques like YaRN. For context, that’s larger than most “frontier” models could handle six months ago, now running on hardware that fits in your backpack.
When Your Phone Becomes the Data Center
Community Validation: Developers report that the 4B model consistently outperforms 9B models from just two years ago, particularly when running through optimized inference stacks.
Multimodal Reasoning: One developer running the UD-Q4_K_XL quant via PocketPal on an iPhone 17 Pro Max noted the model’s multimodal reasoning was “scary smart” for its size, capable of identifying obscure locations from photos and reasoning through complex visual puzzles.
This isn’t just about raw parameter efficiency. Qwen 3.5 employs early-fusion multimodal training, meaning the vision encoder and language model train jointly on multimodal tokens rather than the traditional approach of freezing a text model and grafting on visual capabilities. The result? Even the 4B variant handles visual question answering, document OCR, and spatial reasoning without the performance cliff typically seen in lightweight vision-language models.
The benchmarks tell a stark story. On MMLU-Pro, Qwen 3.5’s 35B-A3B scores 85.3, edging out GPT-5-mini at 83.7 and approaching GPT-OSS-120B’s 80.8. But the real shock comes from the coding benchmarks: SWE-bench Verified scores of 69.2% and Terminal Bench 2 at 40.5% put these “small” models firmly in territory previously occupied by 100B+ parameter behemoths.
The Unsloth Multiplier: Quantization That Doesn’t Suck
Raw architecture only gets you halfway. The other half is quantization that doesn’t turn your model into a dice roll.
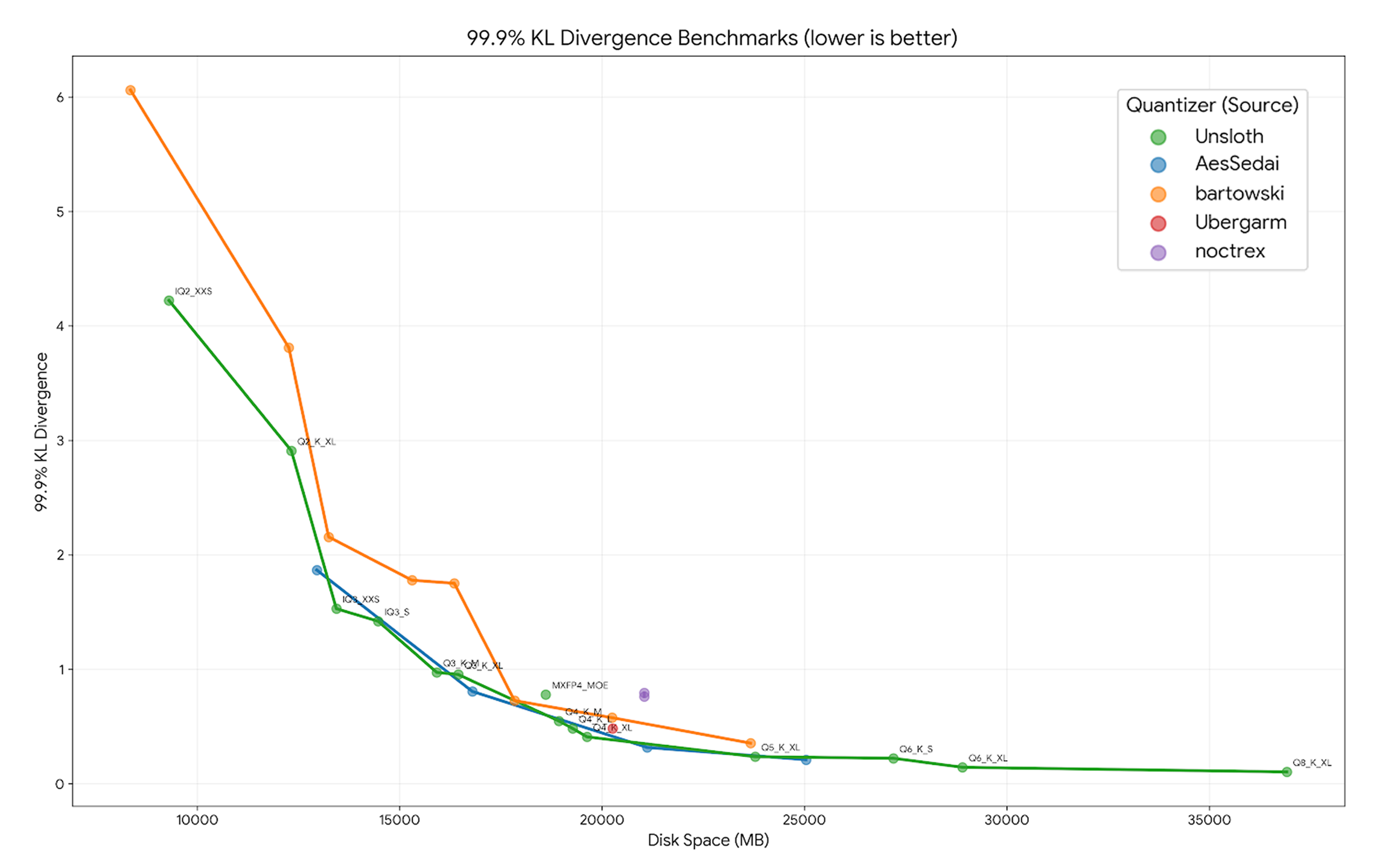
Unsloth’s Dynamic 2.0 GGUFs represent a generational leap in how we compress models for edge deployment. Traditional quantization applies uniform bit-rates across all layers, treating attention heads and feed-forward networks identically. Dynamic 2.0 analyzes each layer individually, assigning specific quantization types based on sensitivity analysis. Some layers get Q8_K, others Q4_K, others Q5_K, depending on which tensors can tolerate compression without affecting output distribution.
The technical results validate the approach. Unsloth benchmarks show their Dynamic 2.0 quants achieve lower KL Divergence (measuring distribution fidelity to the original model) than both standard imatrix quants and Quantization-Aware Training (QAT) approaches across Llama 4, Gemma 3, and Qwen 3.5. For the Qwen 3.5 35B-A3B specifically, the UD-Q4_K_XL quant hits 0.4097 KLD at 99.9% percentile, significantly better than competing quants that often sacrifice critical tensors like attention gates or SSM parameters.
Community testing has pushed these optimizations to extremes. One user reported running Qwen 3.5 35B-A3B at Q4 quantization with 200K context at 62.98 tokens per second on a local RTX 5080 16GB. Another achieved 122 t/s with the UD-MXFP4_MOE variant on a single 4090. These aren’t theoretical benchmarks, they’re production speeds for models that previously required cloud API calls.
The MoE Trick: Sparse is the New Dense
Total Parameters
35B
Active in model weights
Active Per Token
3B
During inference runtime
Experts Total
256
In MoE architecture
Experts Active
9
(8 routed + 1 shared)
The Mixture-of-Experts architecture is what makes this memory efficiency possible, but it requires rethinking how we approach model serving. In Qwen 3.5’s MoE setup, 256 experts exist in total, but only 8 routed plus 1 shared expert activate per token. This sparsity means that while the model contains 35B parameters, inference only touches 3B at any given moment.
For edge deployment, this is transformative. Using llama.cpp with partial offloading, you can run models that theoretically require 70GB+ of VRAM on systems with 16GB of GPU memory and 32GB of system RAM. The inactive experts simply page to system memory, and because MoE routing tends to cluster similar tasks to similar experts, you often end up with hot subsets that stay resident in VRAM while cold experts swap in as needed.
--ctx-size 262144 --n-gpu-layers 999 --flash-attn auto --jinja --temp 0.6 --top-p 0.90 --top-k 20For tool-calling workflows (which Qwen 3.5 handles natively), you’ll want the Unsloth-refined GGUFs that fixed early issues with function calling. The UD-Q8_K_XL variant provides near-full-precision accuracy at roughly half the memory footprint of BF16, making it viable for leveraging NPUs for embedded inference on compatible hardware.
Real-World Battle Testing
The skepticism around small models is warranted, historically, “4B” meant “4 billion reasons to check its work.” But Qwen 3.5’s reinforcement learning pipeline, scaled across million-agent environments with progressively complex task distributions, produces models that generalize surprisingly well to real-world coding and research tasks.
Hallucination Warning
That said, the hallucination problem hasn’t disappeared. Community testing revealed the 0.8B model confidently stating that an Airbus A320-200 is powered by a CFM LEAP-1A turbojet (it’s a turbofan, and the engine choice was wrong anyway). The lesson: these models excel at reasoning and tool use, but you still shouldn’t trust them for obscure factual retrieval without verification.
One developer tested the 35B-A3B model on a complex remote desktop troubleshooting scenario, requiring the model to research Wayland compatibility issues across Fedora 43, KDE, and various RDP implementations. The model processed nearly 30K tokens of context, performed 14 web searches via tool calling, and generated a comprehensive technical report matching the quality of frontier cloud models, all while maintaining 25-30 t/s generation speeds locally.
The Context Crisis, Solved
For developers building AI coding assistants, context windows have been the invisible ceiling. You’d load a codebase, hit the token limit by page three, and watch your assistant forget the architectural constraints from page one. Qwen 3.5’s 262K native window, combined with addressing context limitations in developer workflows, changes what’s possible in local development.
The 4B model can ingest entire codebases, documentation, and conversation history without external chunking. When extended via YaRN scaling to 1M tokens, it handles hour-long video analysis and multi-document research synthesis. One user reported using 128K context lengths for crossover fiction writing and HTML game development, allowing the model to track complex state across multiple implementation attempts.
Running It Yourself
If you’re ready to ditch the API bills, the stack is surprisingly mature. For mobile, PocketPal on iOS provides a clean interface for running the UD-Q4_K_XL quants locally, no network connection required. For desktop, you have options:
Via SGLang
(recommended for multi-GPU)
python -m sglang.launch_server --model-path Qwen/Qwen3.5-35B-A3B --port 8000 --tp-size 8 --context-length 262144 --reasoning-parser qwen3Via vLLM
(with tool calling)
vllm serve Qwen/Qwen3.5-35B-A3B --port 8000 --tensor-parallel-size 8 --max-model-len 262144 --reasoning-parser qwen3 --enable-auto-tool-choice --tool-call-parser qwen3_coderVia llama.cpp
(for single-GPU or CPU-GPU hybrid)
./llama-cli -m Qwen3.5-35B-A3B-UD-Q4_K_XL.gguf --ctx-size 262144 -ngl 999 --flash-attnThe Unsloth GGUFs are available on Hugging Face under the unsloth/ namespace. For the small models (0.8B-9B), even the Q4 quants run comfortably on devices with 8GB VRAM, while the Q8 variants suit 12-16GB setups.
The Democratization Dividend
Who Benefits Most?
- The “GPU poor” – developers running inference on consumer hardware
- Researchers in resource-constrained environments
- Privacy-conscious users who refuse to ship their data to cloud APIs
What makes this release significant isn’t just the benchmarks, it’s the accessibility. The “GPU poor”, developers running inference on consumer hardware, researchers in resource-constrained environments, and privacy-conscious users who refuse to ship their data to cloud APIs, now have access to models that rival commercial APIs from six months ago.
The 4B model’s ability to process 128K contexts at 60 tokens per second on modest hardware, combined with genuine multimodal understanding and robust tool use, represents a tipping point. We’re moving from “local AI as compromise” to “local AI as preference”, where the edge deployment isn’t just private and cost-effective, but actually superior for latency-sensitive applications.
Qwen 3.5 doesn’t just reshape small model expectations, it obliterates the category distinction entirely. When your phone can run a 4B model that codes better than last year’s 30B models, the conversation stops being about parameter counts and starts being about what you actually want to build.



