The 24GB Reality Check
Running a 27B parameter dense model on a consumer GPU sounds like a joke until you realize Qwen 3.6 27B is outperforming previous-generation 397B MoE variants on coding benchmarks. That performance comes at a cost: every single one of those 27 billion parameters activates on every forward pass. Unlike its 35B-A3B MoE sibling, which only computes ~3B active parameters per token and runs roughly 3, 5× faster out of the box, the dense variant is a VRAM-hungry beast that punishes inefficient backends. If you are weighing Qwen3.6’s sparse MoE architecture and active parameter efficiency against the dense model, understand that the dense route demands far more from your inference stack.
The challenge is not merely fitting the weights. At Q4 quantization, model weights alone consume roughly 15, 17GB. Add a 156K context window with Q8 KV cache, flash attention, and multimodal vision projection, and suddenly your RTX 3090 is gasping for air. This is where the backend war gets bloody. On identical Linux hardware with the desktop pinned to the iGPU, one community member systematically stress-tested upstream llama.cpp, ik_llama.cpp (build 4507, commit c35189d8), BeeLlama (featuring DFlash and TurboQuant), and vLLM via the club-3090 wrapper. The results are not close.
The Benchmark: Real Prompts, Real Output
To avoid cherry-picking, the benchmark used a deliberately realistic workload: a one-shot chat completion with a ~5.9K token prompt simulating a code review over local setup files, followed by a sustained 1,024-token generation. No synthetic best-case tokens. Just sustained prefill on a medium-large prompt and long-form decode.
| Backend | Model / quant | Spec path | Context | KV cache | Prefill tok/s | Decode tok/s | Wall time | Notes |
|---|---|---|---|---|---|---|---|---|
ik_llama.cpp |
Qwen3.6-27B-MTP-IQ4_KS |
built-in MTP | 156k |
q8_0/q8_0 |
1260.95 |
72.93 |
18.79s |
best overall default profile |
llama.cpp upstream |
Qwen3.6-27B-UD-Q4_K_XL |
draft-mtp |
32k |
q4_0/q4_0 |
1247.65 |
51.20 |
24.80s |
easiest starting point |
llama.cpp upstream tuned |
Qwen3.6-27B-UD-Q4_K_XL |
draft-mtp |
32k |
q8_0/q8_0 |
1242.81 |
56.66 |
22.88s |
old-like flags helped, still slower |
beellama.cpp |
Q5_K_S + DFlash Q4_K_M |
DFlash | 122.8k |
turbo4/turbo3_tcq |
1117.66 |
36.32 |
33.55s |
text-only quickstart-style run |
The gap is brutal. At 72.93 tok/s decode, ik_llama.cpp sustains output 42% faster than tuned upstream llama.cpp and fully double BeeLlama’s default quickstart configuration. More importantly, it does this while maintaining a 156K context window, nearly five times the upstream llama.cpp ceiling of 32K in this test configuration. Prefill speeds are roughly equivalent across the top contenders, suggesting the decode phase is where backend architectures diverge.
Why ik_llama.cpp Won: Quantization Meets Architecture
The secret is not merely the fork, it is the intersection of model quantization and architectural optimizations unavailable elsewhere. The winning combination was ubergarm’s Qwen3.6-27B-MTP-IQ4_KS.gguf at 15.113 GiB (4.752 BPW), paired with aggressive but stable inference flags.
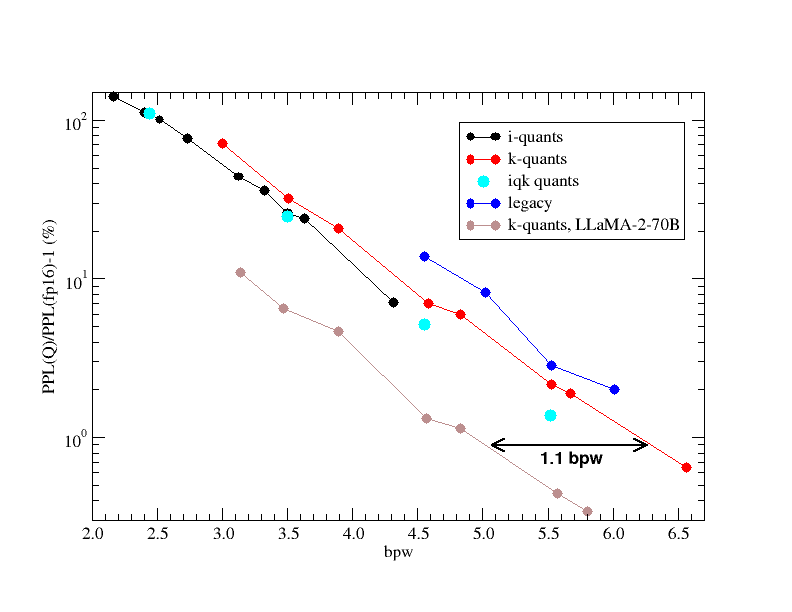
IQ4_KS is the critical variable. In quantization comparison discussions, the ik_llama.cpp maintainer measured IQ4_KS as very close to, or better than, Unsloth’s UD-Q4_K_XL, despite the latter consuming approximately 2.8 GiB more VRAM. On a 24GB card, those saved gigabytes translate directly into context length and KV cache headroom. Qwen 3.6 quantizes exceptionally well, the quantization error for IQ4_KS sits around 0.14%, effectively lossless in practice for interactive coding tasks.
The specific launch configuration that hit 72.9 tok/s decode:
--ctx-size 156000
--cache-type-k q8_0
--cache-type-v q8_0
--flash-attn on
--multi-token-prediction
--draft-max 4
--draft-p-min 0.0
--merge-qkv
--merge-up-gate-experts
--cache-ram 32768
--ctx-checkpoints 32
--reasoning on
--reasoning-format deepseek
--chat-template-kwargs '{"preserve_thinking":true}'
--no-mmproj-offload
Key architectural wins include built-in multi-token prediction (MTP), which outperformed external speculative decoding paths without requiring a separate draft model. While efficient inference architectures such as Gemma 4’s MTP drafters have explored similar territory, ik_llama.cpp’s native implementation accepted draft tokens more cleanly in this benchmark. Meanwhile, --merge-qkv and --merge-up-gate-experts reduced memory pressure, and offloading the vision projector to CPU via --no-mmproj-offload saved roughly 1.5 GiB of VRAM. Need image processing speed? Move mmproj back to GPU, but on a 24GB card, that risks an OOM cliff the moment context grows.
The Competition’s Weak Points
Upstream llama.cpp remains the easiest on-ramp, but the benchmark shows its ceiling. Even with tuned flags raising KV cache precision to Q8_0, decode topped out at 56.66 tok/s, well short of ik_llama.cpp’s profile. The 32K context limitation in the baseline run is a hard constraint for anyone needing long-document analysis.
BeeLlama, despite promising DFlash and TurboQuant technologies that theoretically compress KV cache dramatically, delivered only 36.32 tok/s decode in its quickstart configuration. When pressed on methodology, the BeeLlama author noted that strict comparisons require identical models, KV cache types, and context sizes. Fair criticism, but production environments do not wait for laboratory-perfect parity. Different forks support different quants, and users care about which complete recipe works fastest on their hardware.
After controlled reruns matching some variables, BeeLlama improved to roughly 41 tok/s decode with Q8_0 KV cache, confirming that KV precision matters, but still leaving it 44% slower than the ik_llama.cpp leader. Community analysis suggests DFlash’s speed advantages materialize primarily when the entire model lives in VRAM, any PCI-e data exchange overhead from partial offloading tends to erase theoretical gains, which aligns with these single-GPU results where every gigabyte counts.
vLLM never made it cleanly into the comparison. Preliminary runs with the club-3090 wrapper showed about 78 tok/s on responses, but high-context OOM crashes were too flaky to benchmark reliably. The repository still flags single-card long-context execution as an unresolved issue. vLLM is built for throughput across multiple users and GPUs, forcing it onto a single 24GB card with massive context is fighting the tool’s design.
The AMD and Vulkan Wildcards
Not everyone runs NVIDIA. An AMD 7900 XTX user testing llama.cpp’s Vulkan backend with MTP reported encouraging but mixed results: without MTP, generation hovered around 39, 43 tok/s. Activating MTP produced averages around 65 tok/s, with spikes to 84 tok/s on verbose HTML generation where token acceptance rates skyrocket. That is roughly a 60% improvement in favorable workloads, though prefill lagged by nearly 20%. Vulkan MTP is still in its infancy, and SOTA quants like IQ4_KS lack backend support there, most Vulkan work focuses on legacy quantization types like Q4_0 and Q4_1. AMD’s evolving AI ecosystem and RDNA validation for local inference may close the gap eventually, but today CUDA remains the only fully performant path for these specific quantization families. On the Apple side, hardware limitations affecting local LLM deployments in devices like the Mac Studio continue to push vision-heavy workloads toward explicit CPU offloading tricks identical to the --no-mmproj-offload strategy.
The Memory Economics of IQ4_KS
The choice between IQ4_KS and Unsloth’s UD-Q4_K_XL is not merely academic. The Unsloth variant needs roughly 2.8 GiB more VRAM for equivalent quality. On a 24GB card, that difference determines whether you can run 32K context or push toward 150K+. The IQ4_KS quantization family uses a non-linear mapping between stored quant values and actual weights via small lookup tables (2×16 entries for IQ4_KS), fitting neatly into SIMD registers rather than relying on massive codebooks that punish CPU and older GPU architectures.
This becomes relevant if you are weighing alternative model compression approaches like NVIDIA’s Star Elastic. Why tolerate larger quant sizes when a 4.25 BPW configuration matches or exceeds the perceptual quality of heavier formats? The answer usually involves ecosystem lock-in: IQ4_KS is native to ik_llama.cpp, and while some quant types have partial mainline support, the full performance envelope requires the fork.
Meanwhile, memory bandwidth constraints in AMD’s Strix Halo versus GPU alternatives illustrate why offloading non-critical tensors to CPU is a necessary evil on consumer hardware. GDDR6X and HBM remain king for dense forward passes, any trick that frees VRAM for active compute is worth the registry edits.
GPU Tweaks That Actually Move the Needle
The benchmark was not run on stock GPU settings. The RTX 3090 was pushed to a 330W power limit, with a memory overclock of +600 MHz and an undervolt flattening the curve at approximately 1875 MHz @ 868 mV. These are not required to replicate the configuration, but they explain why some users struggle to match published numbers on identical hardware. Local LLM benchmarking sits at the intersection of software flags and silicon lottery, ignore either at your own peril.
Optimizations That Did Not Help
Not every knob turned improved performance. --spec-autotune on ik_llama.cpp produced no meaningful gain on this workload. --mtp-requantize-output-tensor q6_K occasionally added roughly 5 tok/s in the best run, but the extra ~1 GiB of VRAM consumption made it inconsistent and not worth the tradeoff. BeeLlama’s DFlash precision quickstart loaded fine but ran significantly slower than expected.
| Backend | Quant(s) | Draft / spec mode | Key draft params | KV cache | Other notable flags |
|---|---|---|---|---|---|
ik_llama.cpp |
target IQ4_KS MTP |
built-in --multi-token-prediction |
--draft-max 4, --draft-p-min 0.0 |
q8_0/q8_0 |
--merge-qkv, --merge-up-gate-experts, --ctx-checkpoints 32, CPU mmproj |
llama.cpp upstream |
target UD-Q4_K_XL |
draft-mtp |
--spec-draft-n-max 6, --spec-draft-p-min 0.75 |
q4_0/q4_0 default, q8_0/q8_0 tuned |
--flash-attn on, --jinja |
beellama.cpp |
target Q5_K_S, draft Q4_K_M |
dflash |
--spec-dflash-cross-ctx 1024 |
turbo4/turbo3_tcq |
--kv-unified, -b 2048, -ub 256, text-only in my run |
This is the reality of local inference engineering: wins are measured in single-digit percentages and specific combinations, not magic bullets.
Verdict: What To Run Today
If you have a 24GB NVIDIA card and want to run Qwen 3.6 27B locally with maximum context and speed, the evidence points to a specific stack:
- Backend: ik_llama.cpp (tested build 4507/c35189d8)
- Model: ubergarm/Qwen3.6-27B-MTP-IQ4_KS.gguf
- Context: 156K with Q8_0 KV cache
- Key flags: built-in MTP (
--multi-token-prediction --draft-max 4 --draft-p-min 0.0), flash attention, merged QKV/up-gate experts, CPU vision offload
Is this settled science? Hardly. The BeeLlama author correctly noted that the playing field shifts weekly, their new version was scheduled for release within days of the test. ExLlamaV3 remains untested in this specific configuration. And the next mainline llama.cpp merge could invalidate current assumptions.
But right now, the data says ik_llama.cpp is the only backend consistently breaking 70 tok/s decode on Qwen 3.6 27B within a 24GB envelope while retaining six-figure context capability. In the local LLM space, that is not just a win, it is a temporary monopoly worth exploiting before the next update drops.



