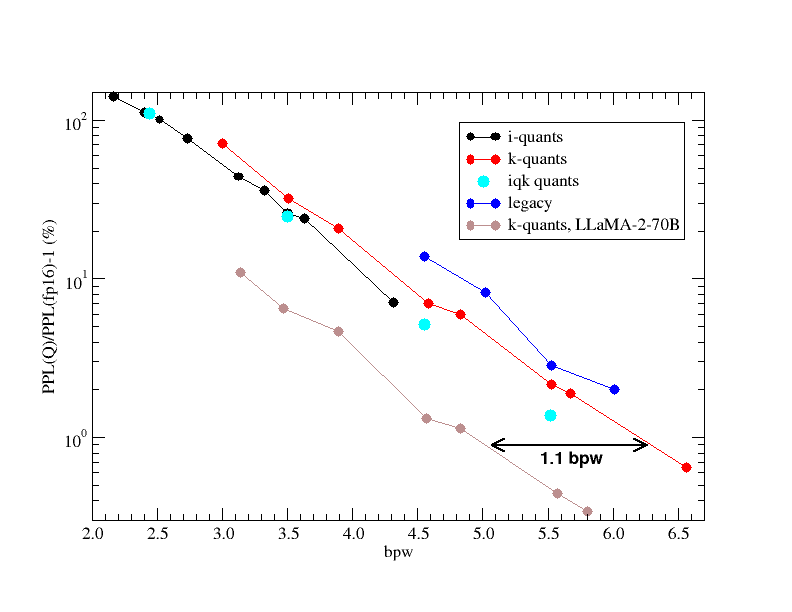
72.9 tok/s on 24GB VRAM: How ik_llama.cpp Won the Qwen 3.6 27B Backend War
A detailed technical comparison of llama.cpp, ik_llama.cpp, BeeLlama, and vLLM for running Qwen 3.6 27B on 24GB VRAM, achieving up to 72.9 tok/s decode with specific quantizations.