The “AMD doesn’t work for AI” narrative deserved its three-year runtime. ROCm was a ghost town next to CUDA’s bustling metropolis, and getting a local LLM to run on Radeon hardware required the technical equivalent of a Flat Earth Society membership card, a triumph of belief over evidence. In April 2026, that expired.
A quiet but seismic shift is happening outside NVIDIA’s walled garden. New tools like llmfit and Hipfire are providing the scaffolding for a genuine, native RDNA AI ecosystem, not just “CUDA compatibility.” They signal a move from painful workarounds to purpose-built validation and optimization for AMD hardware, reshaping what’s possible for local AI on a budget.
Why NVIDIA’s Hegemony Was Good (For NVIDIA)
For years, local LLM inference equated to two things: llama.cpp and CUDA. The pairing was symbiotic and exclusive. NVIDIA’s architecture dictated the optimization pathways, the memory hierarchies, and even the accepted trade-offs. Tools and frameworks, wanting the widest adoption, targeted CUDA first and treated alternatives as ports or afterthoughts.
AMD’s response, ROCm, languished. It was a moving target, inconsistent across OS versions, missing key kernels, and often requiring manual, arcane environment variable overrides (HSA_OVERRIDE_GFX_VERSION, anyone?). The community verdict was swift and brutal: if you’re serious about local AI, you buy NVIDIA.
This created a self-fulfilling prophecy. Fewer developers used ROCm, so fewer tools supported it, making it even less attractive. It was less a technical gap and more an ecosystem collapse.
Hipfire: A Thesis in Rust and HIP
Enter hipfire, a project that embodies the new, unapologetic approach. Its developer’s thesis is revealing: “rebuilding from zero targeting AMD silicon directly via custom HIP will always beat CUDA-shaped code that targets… not AMD”.
This is a fundamental rejection of the old paradigm. Instead of forcing CUDA-centric code through a ROCm translator and hoping for the best, hipfire starts with AMD’s Heterogeneous Interface for Portability (HIP). It’s a Rust-based, single-binary, Ollama-style LLM inference engine built from the ground up for RDNA architectures, from the initial 5700 XT through the latest Strix Halo and RDNA 4 Pro (R9700).
The practical results? Initial user reports are promising. One developer testing Qwen models on a 6800 XT reported getting “1.5 to 2 times higher t/s and x10 on prefill” compared to existing ROCm backends in llama.cpp. Another, running a Qwen3.6-35B MoE model on a 9070 XT, achieved 30-35 tokens/sec at the start of a fresh context. These aren’t theoretical benchmarks from a press deck, they’re early indicators from the trenches, suggesting the “write for the metal” thesis holds water.
Community Validation: Benchmarks Without the Marketing Filters
The real-world performance story for AMD hardware is being written not by corporate slides, but in GitHub Discussions and community tracking tools. The llmfit project is pivotal here.
Originally a hardware-aware LLM recommendation tool, llmfit has evolved into a community-powered benchmark database. Its “Community Benchmarks” feature (b in the TUI) pulls real-world performance data, tok/s, TTFT, VRAM usage, from localmaxxing.com and other sources. This crowdsourced data is a game-changer for cutting through vendor-specific marketing.
You can now query how a Qwen3.5-35B-A3B model actually performs on an RX 7900 XTX versus an RTX 3090, based on aggregated user submissions. This democratizes hardware validation, moving the conversation from “NVIDIA is faster” to “Here’s the exact performance delta, on this specific workload, and here’s what it costs.”
The narrative emerging is one of raw value. The Compute Market analysis notes that while the RX 7900 XTX at ~$899 delivers ~80% of the RTX 4090’s tokens/sec on Q4 inference for ~50% of the price. For memory-bandwidth-bound inference tasks, that’s a compelling financial argument. The playing field isn’t level, but the cost-benefit analysis is finally becoming a real calculation.
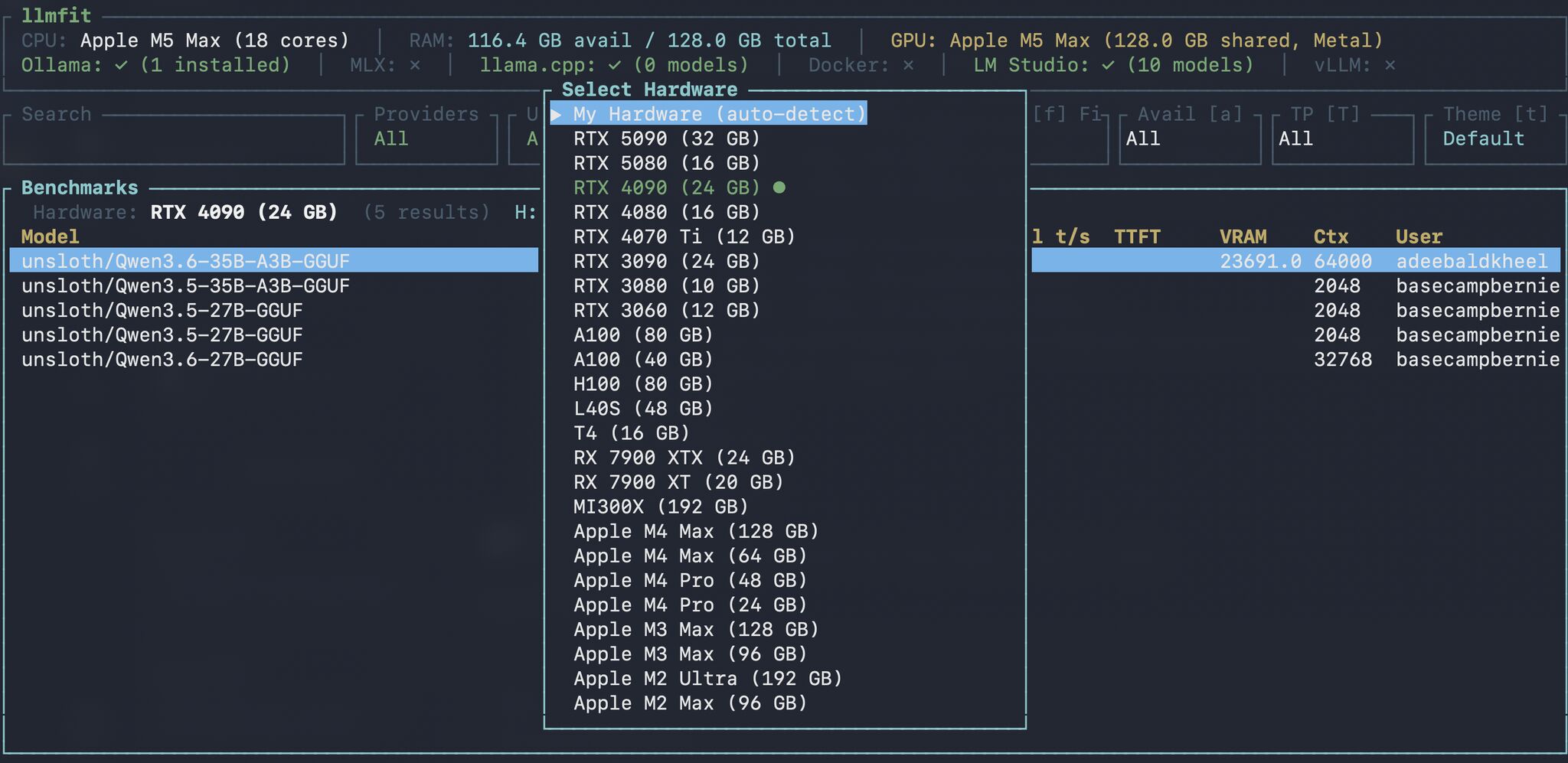
Screenshot of llmfit’s community benchmark view, showing real user data across hardware.
The Vulkan Backend: A Surprise Contender
One of the most significant revelations from the recent benchmarking surge is the unexpected viability of Vulkan. The longstanding assumption was that ROCm was the only “serious” path for AMD AI workloads. However, detailed benchmarks posted in llama.cpp discussions tell a different story.
A user running a Qwen3-30B-A3B MoE model on an AMD Radeon AI PRO R9700 (RDNA4) with the Vulkan backend reported 183 tokens/sec decode and 3,033 tokens/sec prefill. Crucially, they noted that in their specific tests, the Vulkan backend was faster than ROCm HIP on the R9700: ~183 tokens/s (Vulkan) vs ~150 tokens/s (ROCm HIP) for decode.
This performance, achieved using KHR_cooperative_matrix extensions for RDNA4 matrix cores, underscores a critical point: ultimate performance depends as much on kernel optimization for a given API as on the API itself. For Windows users or those seeking a simpler setup, Vulkan (which “just works” with standard GPU drivers) is no longer a second-class citizen but a legitimate, high-performance option for local inference.
The Hardware Simulation Revolution
One of the more clever features in llmfit is its hardware simulation mode (press S). This allows you to answer a fundamental question: “What if?” What if I had 48GB of VRAM instead of 24? What if my system RAM was 128GB? The tool instantly recalculates which models fit, their estimated performance, and optimal quantization levels against your simulated specs.
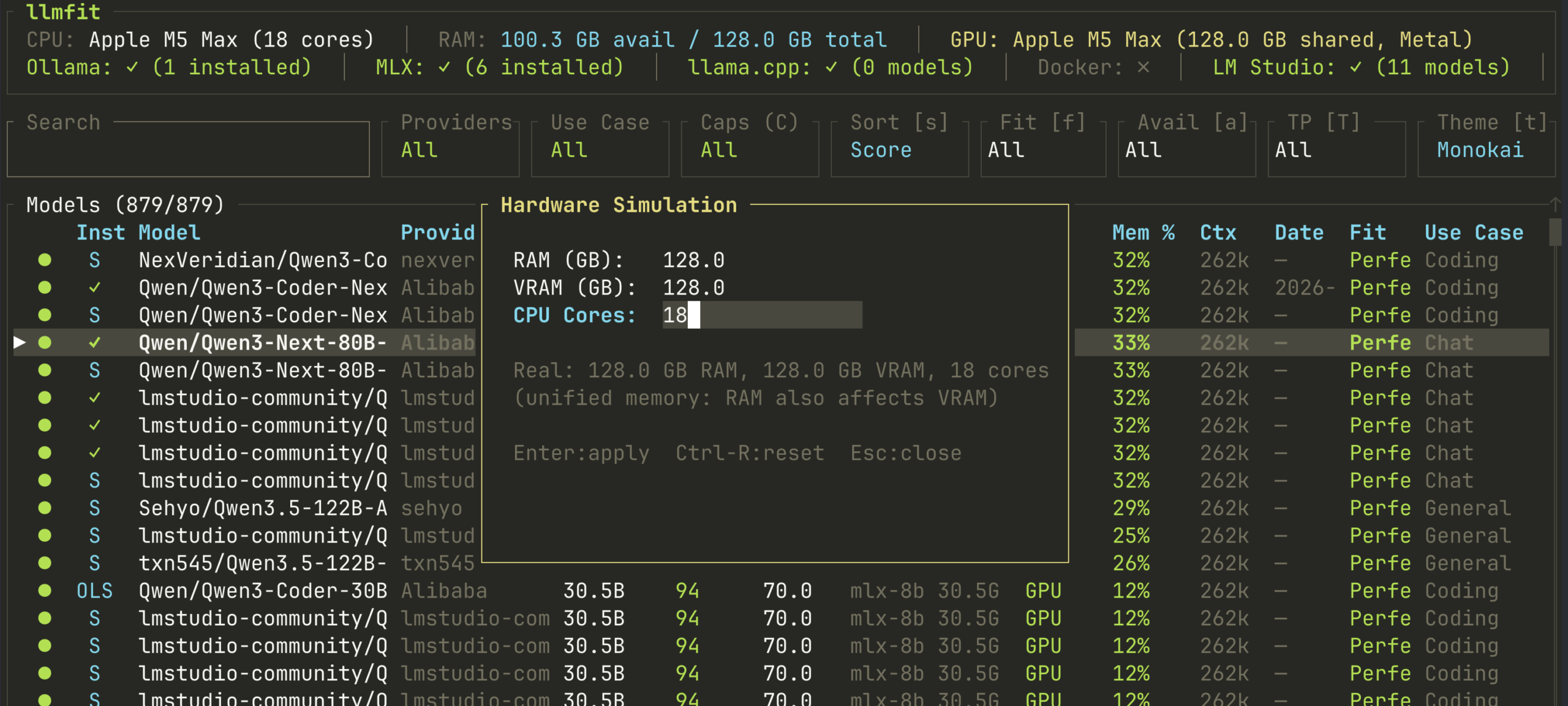
llmfit’s hardware simulation UI lets you stress-test model fit against hypothetical hardware.
This is more than a neat party trick. It’s a powerful validation and planning tool specifically for the AMD landscape, where VRAM configurations are often the primary constraint. It enables prospective buyers to model their upgrade path precisely: does moving from an RX 7900 XTX (24GB) to a Strix Halo system with 96GB of unified memory unlock the 120B MoE model I want to run? The simulation gives a data-driven answer before a single dollar is spent.
This focus on optimizing AI inference on consumer-grade GPU hardware is critical for the AMD value proposition. Since brute-force compute per dollar often favors NVIDIA, the AMD play must be smarter allocation, maximizing what you can actually run on a given memory budget.
The Strix Halo Wildcard and the Unified Memory Gambit
Perhaps the most disruptive AMD offering isn’t a discrete GPU at all. The upcoming Strix Halo (Ryzen AI Max+) APU represents a different axis of competition: unified memory.
With the ability to allocate up to 96GB of a 128GB LPDDR5X pool directly to the iGPU, Strix Halo systems bypass the discrete VRAM ceiling entirely. This enables a mini PC to host models like Llama 3 70B Q4 with massive context headroom or even 120B MoE models that simply cannot fit on any consumer GPU.
This isn’t about winning on tokens/sec against a 4090. It’s about winning on the question: “Can it run the model at all?” For certain research, development, or long-context workflows, the ability to load a massive model at all trumps generating its tokens marginally faster.
It’s a classic AMD maneuver, competing on a different battlefield. While NVIDIA refines the CUDA fortress, AMD is building a bridge over the moat.
The New Toolchain: No More Praying to the Compatibility Gods
The emergent RDNA-native stack is crystallizing:
1. Native Compilation: Tools like hipfire and ROCm-optimized forks of llama.cpp (-DGGML_HIP=ON).
2. Community Validation: Benchmarks in llmfit and discussions aggregating real-world data, shifting the performance narrative from marketing to measurement.
3. Simplified Deployment: Official ROCm wheels for PyTorch and vLLM, and native detection in Ollama containers (HSA_OVERRIDE_GFX_VERSION is now often optional).
4. Hardware-Aware Planning: Simulation tools to plan purchases and model deployments based on actual memory constraints, not spec sheet hopes.
This toolchain is what turns “AMD can work for AI” into “AMD works well for my specific AI use case.”
What This Means for Builders and Buyers
The implications are practical:
- For Developers: The barrier to entry for targeting AMD hardware is dropping. HIP is a more accessible target than ever, and the performance payoff for native development is becoming clear. Contributing to or leveraging projects like llmfit helps everyone by expanding the dataset of what works.
- For Enthusiasts: You finally have a legitimate, data-backed alternative. The choice is no longer just “NVIDIA or vastly inferior.” It’s a trade-off between peak performance (NVIDIA) and compelling price-to-VRAM ratios with a rapidly maturing software story (AMD). The single-node local compute revolution for AI workloads is being fought on multiple fronts.
- For the Market: Real competition is the best validation suite of all. NVIDIA’s dominance has bred complacency in pricing. AMD’s growing viability, especially in the lucrative local/edge AI inference space, applies necessary pressure. Look at the burgeoning discussion around global AI chip competition and NVIDIA alternatives, viable competition changes everything.
Beyond the Hype Cycle
It’s crucial to temper enthusiasm with reality. CUDA’s decade-plus lead in optimization, library support (cuBLAS, cuDNN), and developer mindshare isn’t erased overnight. Fine-tuning large models, using esoteric research frameworks, or deploying complex multi-GPU training pipelines is still significantly smoother on NVIDIA.
However, for the core local AI use case, running quantized inference of popular open-weight models, AMD’s gap is now measured in manageable percentage points, not orders of magnitude. The new RDNA-native tooling provides the metrics to prove it and the frameworks to exploit it.
The message from the community is shifting from “Does it work?” to “How well does it work on this model with this quant?” That’s the sign of a maturing platform. AMD isn’t just joining the local AI fray, it’s finally bringing its own weapons to the fight. The validation suite is no longer just a list of compatible software, it’s a growing portfolio of real user results, native tools, and strategic hardware that makes the “Why would I buy AMD for AI?” question have multiple, legitimate answers.
The next time someone tells you “AMD is broken for AI”, point them to the validation metrics like KL Divergence and Perplexity from the new GGUF quants optimized for RDNA, the data validation pipeline resource optimization happening in community tools, or the extreme local AI inference on minimal hardware projects pushing boundaries. The narrative is being rewritten, one benchmark at a time.