The narrative that NVIDIA owns AI inference is starting to crack, and it’s not because of some breakthrough paper or corporate pivot. It’s because database administrators in Germany and hardware tinkerers on Reddit are building 128GB VRAM systems with four AMD Radeon R9700 cards that cost less than a single RTX 6000 Blackwell. The performance trade-offs are real, but so are the economics, and that’s making a lot of people uncomfortable.
The 128GB Build That Started It
A database admin from Germany recently documented a build that should make any AI hardware strategist pause: four ASRock Radeon AI PRO R9700 cards (32GB each) on a Threadripper PRO 9955WX platform, totaling 128GB of VRAM for under €10,000. After a 50% digitalization subsidy from their municipality, the out-of-pocket cost dropped to roughly €4,900.
The motivation was straightforward: run 120B+ parameter models locally for data privacy. The kicker? They originally considered NVIDIA but couldn’t justify the VRAM-per-dollar equation. Four R9700s delivered 128GB VRAM while leaving budget for a proper server-grade platform.
Benchmark results from this build tell a nuanced story:
| Model | Size | Quant | Prompt t/s | Gen t/s |
|---|---|---|---|---|
| Meta-Llama-3.1-8B-Instruct | 8B | Q4_K_M | 3169.16 | 81.01 |
| Qwen2.5-32B-Instruct | 32B | Q4_K_M | 848.68 | 25.14 |
| Meta-Llama-3.1-70B-Instruct | 70B | Q4_K_M | 399.03 | 12.66 |
| MiniMax-M2.1 | ~230B | Q4_K_M | 938.89 | 32.12 |
The prompt processing numbers are particularly striking. At 3169 tokens/second for Llama 3.1 8B, the R9700 is punching well above its weight class. But the generation speeds, 81 tokens/second, reveal the architectural difference from NVIDIA’s tensor cores.
The VRAM Controversy Nobody Asked For
Here’s where the story gets spicy. That “32GB” R9700? It’s actually 30,576 MB in ROCm. A Level1Techs forum thread exploded when a user noticed lmstudio reporting only 29GB available on their Sapphire R9700. The community initially cried foul, suspecting marketing deception.
The real explanation is more technical, and more concerning for enterprise buyers. The discrepancy comes from ECC memory overhead (6.25-7% of total VRAM) reserved for error correction, plus driver-level page table allocations. For the AI PRO series, ECC is enabled by default, a feature AMD markets as essential for long-running training and inference.
The math is brutal:
– Physical VRAM: 32,768 MB (32 × 2³⁰)
– Usable in ROCm: 30,576 MB
– “Missing” memory: ~2,192 MB (6.7% overhead)
Users can disable ECC via kernel parameters (amdgpu.ras_enable=0) to reclaim the full capacity, but that defeats the purpose of buying a “Pro” card. As one forum member noted: “The way computers count: 1 GB = 2³⁰ = 1,073,741,824 bytes. The way marketing counts: 1 GB = 10⁹ = 1,000,000,000 bytes. We’re seeing both lies at once.”
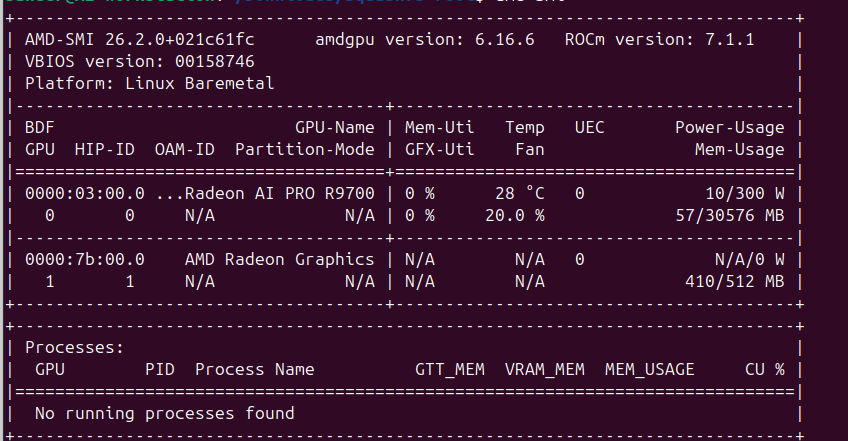
ROCm Maturity: From “Almost Works” to “Actually Works”
The llama.cpp GitHub discussion #15021 serves as a real-time pulse check for AMD’s ROCm ecosystem. With 46 comments and 79 replies, it’s a goldmine of community-validated performance data. The consensus? ROCm 7.1+ with HIP is production-ready for inference, though not without quirks.
Key findings from the community benchmark data:
- Single R9700: 4773 tokens/second (prompt) / 97 tokens/second (gen) on Llama 2 7B Q4_0
- Flash Attention impact: ~10% prompt processing boost, minimal generation impact
- PCIe 5.0 x16 enables Pipeline Parallelism to outperform Tensor Parallelism by 45% for single-user workloads
One user’s multi-GPU testing revealed that for 7B models fitting in a single GPU, layer splitting across cards actually reduces performance due to synchronization overhead. But for 70B+ models, the scaling becomes essential, and that’s where the R9700’s 32GB-per-card density shines.
The ROCm scoreboard shows the R9700 trading blows with NVIDIA’s RTX 7900 series, but the real story is in the total cost of ownership. Four R9700s at ~$1,300 each ($5,200 total) deliver 128GB VRAM. A single RTX 6000 Blackwell with 96GB costs $6,800+, and you’d need two for 128GB.
The PCIe 5.0 Advantage Nobody’s Talking About
The German build’s most overlooked finding: PCIe 5.0 x16 bandwidth changes the multi-GPU game. With all four cards running at full PCIe 5.0 x16 on a WRX90 motherboard, standard Pipeline Parallelism (layer split) was ~97 tokens/second compared to ~67 tokens/second with Tensor Parallelism/Row Split.
This isn’t theoretical. The user explicitly tested both modes, and the results contradict conventional wisdom that tensor parallelism is always better. For single-user, high-context workloads, the lower latency of pipeline parallelism on PCIe 5.0 wins.
The implication: AMD’s platform advantage isn’t just in VRAM density, it’s in platform I/O bandwidth. Threadripper PRO’s 128 PCIe 5.0 lanes enable configurations that are simply impossible on consumer Intel platforms.
When It Doesn’t Work: The Caveats
Before you sell your NVIDIA stock, the community has documented clear limitations:
- Vulkan backend is still second-class: ROCm consistently outperforms Vulkan on prompt processing, sometimes by 2-3x. Vulkan’s generation speeds can be competitive, but the overall experience feels less optimized.
- Small model inefficiency: For 7B models that fit in one GPU, multi-GPU setups add overhead. One user noted: “Layer split is faster at longer contexts (8192+ tokens) but slower at 512 tokens. Row split is just terrible, 6x slower.”
- Driver sensitivity: ROCm 6.4.x has known regressions with Llama 3 8B prompt processing. ROCm 7.0+ resolves many issues but requires careful kernel compatibility.
- Quantization limitations: The 230B MiniMax-M2.1 model in Q8_0 quantization repeatedly threw HIP errors and took 2 hours to load from external storage. This isn’t a polished experience.
The Economics Are Brutal For NVIDIA
Let’s talk numbers that procurement departments actually care about. The German build’s total cost was €9,800 before subsidy. For that price, you get:
– 128GB VRAM (4 × 30.5GB usable)
– Threadripper PRO 9955WX (16 cores)
– 128GB DDR5 5600MHz
– 2× 2TB PCIe 4.0 SSDs
A comparable NVIDIA build would require:
– 2× RTX 6000 Blackwell (96GB each) = $13,600+
– Or 4× RTX 4090 (24GB each) = $7,600+ but with 96GB total and no ECC
Even accounting for the R9700’s 5-10% generation speed deficit, the VRAM-per-dollar ratio is 2.5x better than NVIDIA’s current generation. For inference workloads that are memory-bound rather than compute-bound, that’s a decisive advantage.
What This Means For The Ecosystem
The R9700’s emergence as a viable alternative signals a maturation point for AMD’s ROCm ecosystem. It’s no longer “can it run?” but “how well does it run?”, and the answer is “well enough to save thousands of dollars.”
For local LLM enthusiasts, this democratizes access to 100B+ parameter models. For enterprise architects, it introduces negotiating leverage against NVIDIA’s premium pricing. For software developers, it means writing ROCm-compatible code is no longer a niche skill, it’s a career advantage.
The community has already moved from “does it work?” to “how do we optimize it?”, discussions now focus on rocWMMA library integration, flash attention tuning, and kernel parameter tweaking. That’s the sign of a healthy, self-sustaining ecosystem.
The Bottom Line
AMD’s R9700 isn’t perfect. It’s not going to beat an H100 in raw throughput. But it’s good enough at a price point that makes NVIDIA’s consumer and prosumer cards look exploitative. The 128GB VRAM build isn’t just a flex, it’s a practical solution for running 120B+ models locally with acceptable latency.
The real controversy isn’t the VRAM overhead or the ROCm quirks. It’s that NVIDIA’s dominance has been so complete for so long that we stopped questioning the cost. The R9700 forces that question back into the conversation.
If you’re planning a local AI workstation in 2026, the math is clear: AMD lets you buy VRAM in bulk, while NVIDIA sells it in luxury packaging. For many use cases, that’s a trade-off worth making.
Ready to build your own? Start with the llama.cpp ROCm installation guide and join the GitHub performance discussion to share your benchmarks. Just remember to check your ECC settings before you benchmark, those 2GB matter more than you’d think.