For years, the dominant logic in local LLMs has been a simple trade: you want quality, you pay in parameters, memory bandwidth, and sheer bulk. Then Qwen 3.6-27B dropped and casually invalidated that entire rulebook. A dense 27-billion-parameter model, designed to run on hardware you already own, not only beats its own previous-generation colossus, the 397-billion-parameter Qwen3.5-397B-A17B MoE model, but also goes toe-to-toe with Claude 4.5 Opus in key coding tasks.
The community’s reaction was captured succinctly by one observer: “WTF why is this so good?” The bluntness is justified. Let’s unpack why this isn’t just another model release, but a potential turning point for accessible, high-performance AI.
The Numbers Don’t Lie: Benchmark Shock Therapy
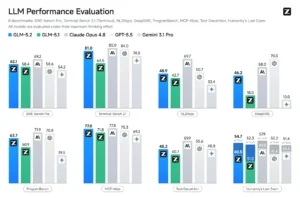
The performance claims are not modest. According to Alibaba’s own benchmarks, the dense Qwen3.6-27B beats its predecessor, the massive Qwen3.5-397B-A17B (a 397B total / 17B active MoE model), on 10 out of 12 major coding benchmarks. Let that sink in: a model with roughly 1/15th the total parameters is outperforming it. It “bitchslaps and floor mops” Gemma4-31B, as one developer bluntly put it, and even scores narrow wins against the proprietary Claude Opus.
The most telling victories are in coding agent tasks, which is where many users feel the real-world utility of a model.
Here are the raw, head-to-head results pulled from the Hugging Face spec sheet:
- SWE-bench Verified: Qwen3.6-27B scores 77.2, beating Qwen3.5-397B (76.2) and Gemma4-31B (52.0), and getting within striking distance of Claude Opus (80.9).
- Terminal-Bench 2.0: It ties Claude Opus at 59.3, a massive 18-point leap from its 3.5 predecessor (41.6).
- SkillsBench Avg5: It scores a staggering 48.2, nearly doubling its 3.5-27B score (27.2) and almost matching Claude’s 45.3.
This performance leap isn’t just evolutionary, it’s architectural. The traditional wisdom was that Mixture-of-Experts (MoE) models, with their conditional activation of parameters, were inherently more efficient and powerful for a given compute budget. Dense models were the blunt, heavy hammers. Qwen3.6-27B suggests that perhaps the training data, algorithm, and architectural tweaks matter more than the sheer parameter count.
The Anatomy of a Surprise Contender
So how does a 27B dense model pull this off? The official Hugging Face model card reveals some of the technical foundations that set the stage for this upset.
The model employs a hybrid architecture that blends Gated Attention and Gated DeltaNet layers, which likely allows for a more balanced distribution of compute between reasoning (attention-heavy) and recall/pattern-matching (state-space model-like) tasks. It natively supports a context window of 262,144 tokens, extensible to over 1 million with YaRN scaling, providing the runway needed for complex, multi-file agentic coding tasks.
Perhaps the most significant upgrade is the formalization of Thinking Preservation. Unlike earlier “chain-of-thought” models, Qwen3.6-27B can be configured to retain the reasoning traces (“) from previous messages in its context window. This isn’t just a display feature, it reduces redundant thinking in iterative agent loops, potentially lowering overall token consumption during long-running tasks and improving KV cache utilization.
This aligns with a broader strategic shift in the open-source community, where efficiency and real-world utility are being prioritized over raw parameter scaling. For deeper context on how these design choices are reshaping the competitive landscape, see our analysis on broader strategic shifts toward open-weight model dominance.
The Hardware Gets Realistic: “Getting So Close to Opus Levels with 2 3090s”
The practical implications are what sparked the 1,500+ upvotes on the Reddit thread. This isn’t a theoretical improvement.
The BF16 version weighs in at around 53.8 GB. However, quantization is where the magic happens for local deployment. The Unsloth team released Q4_K_M quants of ~16.8 GB almost concurrently with the base model’s release, allowing it to run on a single RTX 4090 or 3090. Developers immediately began testing it.
Simon Willison documented his experience running the quantized model via llama.cpp. Using a Q4 quant, he tasked the model with generating an SVG of “a pelican riding a bicycle.” The resulting image, complete with “weirdly bent legs that touch the pedals”, was surprisingly coherent and creative for a model of this size running locally. He noted generation speeds of about 25-26 tokens/second on modest hardware, confirming its viability.
This radically changes the calculus for developers. As one commenter put it: “I can’t believe we’re getting so close to opus 4.5 levels with 2 3090s.” This local parity with cloud giants has profound implications. No API limits, no data privacy concerns, and a total cost of ownership that is predictable after the hardware investment.
The Devil in the Local Details: Unfurled Prompts and Ominous Loops
Every powerful tool has its quirks. Early adopters have reported that Qwen3.6-27B, in its default “thinking mode”, can sometimes get stuck in thinking loops, generating endless “ sequences. This echoes the community feedback, users on quantized versions noted it “gets lost in crazy loops.”

Example of SVG generation by Qwen3.6-27B via Simon Willison.
The official documentation recommends specific sampling parameters to mitigate this:
* General tasks: temperature=1.0, top_p=0.95, top_k=20
* Precise coding: temperature=0.6, top_p=0.95, top_k=20
* Non-thinking mode: temperature=0.7, top_p=0.80, presence_penalty=1.5
Disabling thinking mode entirely requires an API flag (enable_thinking: False), something that may not be easily accessible in all frontends. This highlights the constraints often faced during local inference contexts, where model quirks become your problem to solve, not the API provider’s.
The model’s architecture also brings a practical constraint: its larger hidden layers (5120 vs. its predecessor) make each quantized version about 20% larger than equivalent ones for Qwen3.5-27B. As one user lamented, this means a user with a 12 GB GPU might be forced to use a lower-precision quant (like IQ3) compared to what they used before, potentially affecting quality.
The Verdict: A New Phase for Local Coding Agents
What does Qwen3.6-27B represent?
- Efficiency Over Architecture Dogma: It proves that sheer parameter count isn’t everything. A well-trained, densely connected model can exceed the performance of a far larger, sparsely-activated one, reversing the recent trend towards ever-larger MoE models.
- Local Agent Viability: With scores rivaling Claude Opus on Terminal-Bench and SWE-bench, and official support for agent frameworks like Qwen-Agent and Qwen Code, it’s a first-class citizen for autonomous coding tasks, and it runs on your own hardware.
- The Democratization of Frontier AI: The barrier to entry for running state-of-the-art coding assistants just plummeted. You no longer need a multi-GPU server or a cloud API subscription. For a deeper exploration of this evolving landscape, check out our previous analysis on the efficiency gains observed in agentic coding workflows.
The release is also a clear signal to Western labs. Alibaba is not just participating in the open-weight race, for a specific, critical use case (coding), it’s setting the pace. As one developer noted, “I’m glad Alibaba is picking up the torches after META dropped the balls.”
Qwen3.6-27B isn’t perfect. Its thinking loops are a known quirk, and its hardware appetite, while reasonable, is not trivial. But its impact is undeniable. It has shattered the expectation that high-caliber coding assistance requires a massive, complex MoE model or a fat monthly cloud bill. The dense underdog has delivered a knockout punch, and for developers who value performance, privacy, and control, the local LLM game just got a lot more interesting.