Who Needs a GPU Cluster? The Bare-Knuckle Reality of Training LLMs on a Single Card
The narrative has been locked in for years: serious AI model training belongs in the cloud, on racks of A100s or H100s, paid for with venture capital. But there’s a counter-narrative being written in bedrooms and home labs, powered by consumer-grade GPUs and free weekends. It’s not about fine-tuning a pre-trained behemoth. It’s about starting from scratch, raw text, a stack of PyTorch files, and a single GPU, and ending up with a model that’s yours, from byte to behavior.
The barrier isn’t just a technical challenge, it’s a psychological one. We’ve been conditioned to believe that building a language model from the ground up requires resources only tech giants possess. But what if the real bottleneck was never the hardware alone, but the assumption that you need to use it the same way they do?
This isn’t theoretical. Projects are already proving the point.
The One-GPU “Cluster”: Scaling Down, Not Out
Let’s get this out of the way: you’re not going to train GPT-4. But the goal isn’t to chase SOTA. It’s to achieve sovereignty. Training a 235-million-parameter model from scratch, like the Plasma 1.0 project on GitHub, is an education in the full stack of modern LLM creation that no fine-tuning tutorial can match.
The project, built by a solo developer on an RTX 5080, proves the workflow. It’s a full-stack pipeline: data scraping from FineWeb-Edu, Wikipedia, and code repositories, quality filtering and MinHash deduplication, training a custom SentencePiece tokenizer, a LLaMA-style architecture (GQA, RoPE, SwiGLU), pretraining and instruction tuning with loss masking, all culminating in a model that, while “not competing with Llama 3”, knows its place and its craft.
Pretraining for Plasma 1.0 took about five days. Instruction tuning was a matter of hours. This isn’t a weekend project, but it’s within the realm of a dedicated hobbyist.
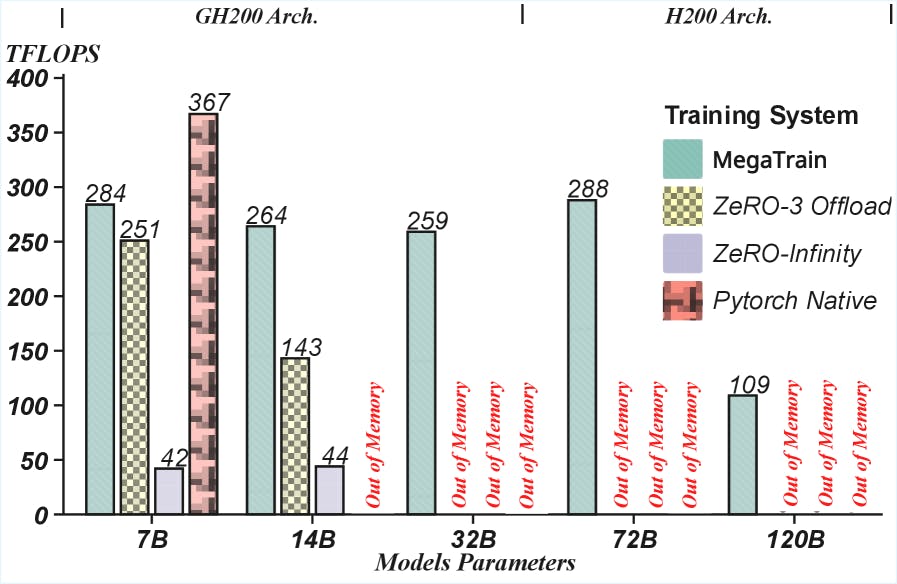
The hardware itself is getting good enough. While not designed for data centers, the GeForce RTX 4090, with its 16,384 CUDA cores, 512 Tensor Cores, and 24 GB of GDDR6X memory, packs a punch for deep learning tasks. The key is managing memory. A 100B-parameter model in float32 would need ~400GB just for weights, impossible on this hardware. The breakthrough isn’t in buying more VRAM, it’s in rethinking the relationship between GPU and CPU memory.
Inverting the Problem: From GPU Memory to Streaming Parameters
The traditional approach treats GPU memory as sacred storage and the CPU as a slow, distant relative. Modern research, like the MegaTrain paradigm discussed on HackerNoon, flips this script. Why store everything on the GPU if you can’t fit it? Instead, MegaTrain uses the CPU as the primary parameter store, streaming layers to the GPU for computation as needed.
The math is brutal but illustrative. A 100B-parameter model in FP32 needs ~400GB just for weights. Add optimizer states (like Adam’s momentum and variance, often two more copies), and you’re nearing 1.2TB before storing a single activation. An RTX 4090? 24GB. An H200 with 141GB of HBM? Still off by an order of magnitude.
The MegaTrain insight is deceptively simple: never try to hold the whole model in GPU memory at once. Instead, treat the GPU as a high-speed computational scratchpad. Store the entire model, all parameters and optimizer states, in plentiful, cheap CPU RAM (1.5TB is feasible on a high-end desktop). Then, for each layer during training:
1. Prefetch its parameters from host (CPU) memory to device (GPU).
2. Compute the forward and backward passes.
3. Compute and send gradients back to the CPU.
4. Clear the GPU for the next layer.
Key Architecture Shift
- • Treat GPU as computational scratchpad
- • Store entire model in CPU RAM
- • Stream layers on demand
- • Overlap prefetch + compute + gradient transfer
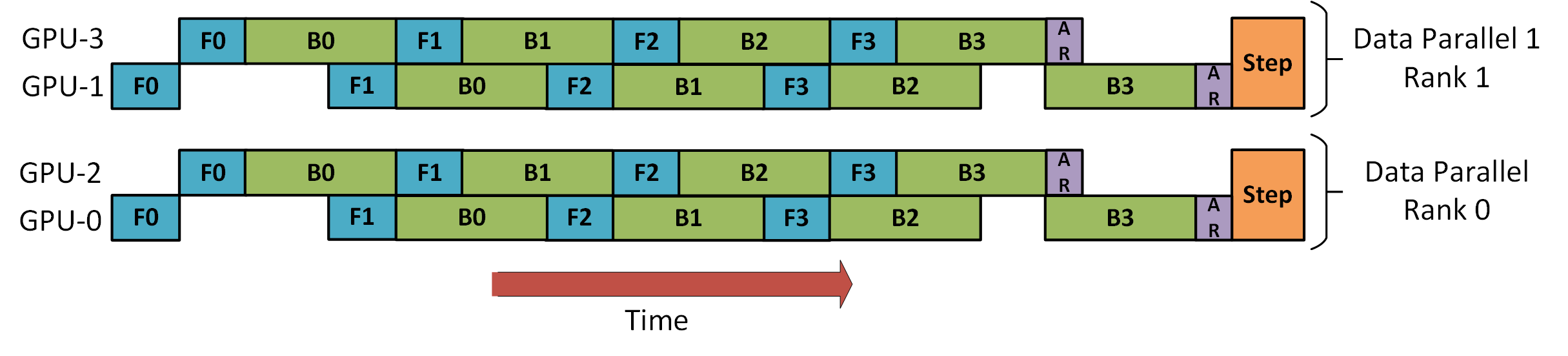
This 3D parallelism in DeepSpeed diagram shows the complex dance of data, model, and pipeline parallelism needed for traditional large-scale training. What if we could avoid most of that complexity by simply rethinking the fundamental memory constraint?
The bottleneck shifts from GPU memory capacity to CPU-GPU bandwidth. Modern systems like PCIe 5.0 offer ~128GB/s, which becomes the limiting factor. The trick is overlapping operations: while the GPU is crunching numbers for layer n, you’re asynchronously prefetching layer n+1 and offloading gradients for layer n-1. Done correctly, the GPU stays saturated with compute, not idle waiting for data.
This isn’t just a theory. It enables full-precision (FP32) training of models with over 100 billion parameters on a single GPU, a feat that redefines what’s possible in a diy local ai infrastructure with consumer-grade components.
Forging the Pipeline: From Raw Text to Conversational AI
The architecture is only half the story. The other half is data, the unglamorous, grind-it-out work that determines whether your model speaks like a scholar or a spam bot.
Looking at projects like Plasma 1.1 reveals a 12-stage pipeline, a blueprint for the solo practitioner:
- Data Collection: Multi-source crawling (FineWeb-Edu, Wikipedia, StackExchange, ArXiv, code from StarCoder).
- Cleaning: Quality scoring using fasttext classifiers trained on curated data, toxicity filtering, and MinHash deduplication across the entire corpus.
- Tokenization: Training a custom SentencePiece BPE tokenizer on a diverse sample with byte-level fallback.
- Mixing: Domain-weighted sampling (e.g., 45% web, 15% wiki, 15% code) to balance the model’s knowledge.
- Pretraining: The long haul on billions of tokens.
- Instruction Tuning: Using loss masking so the model only learns from assistant response tokens, a critical detail for aligning behavior.
This process teaches more than any pre-fab course. There’s no substitute for wrestling with tokenization quirks, discovering the impact of data mixture ratios, or debugging a loss curve that won’t descend. It’s the difference between knowing how to drive a car and knowing how to build one.
For those starting out, foundational resources abound. DataCamp’s PyTorch Transformer course offers a solid starting point for understanding the architecture. But the real learning often happens in projects like OpenMythos, an open-source, PyTorch-based reconstruction of a speculative architecture that uses a recurrent-depth transformer (RDT) to get more computational depth from fewer parameters. These community-driven efforts provide the blueprints and the proof.
The Psychological Liberation of Consumer-Grade AI
This movement isn’t just about cost savings. It’s about agency. When you fine-tune Llama 3, you’re renting a room in Meta’s mansion. When you train Plasma from raw text on your own curated corpus, you own the foundation.
It changes the questions you can ask. What happens if you train primarily on technical documentation and code? What about a model trained exclusively on dialogue from a specific genre of fiction? The cost of experimentation collapses from hundreds of thousands of cloud dollars to the electricity bill for a week of your GPU running at home.
This agency extends to privacy and control. No data leaves your machine. No API call logs. No risk of a service being discontinued. The model is yours, permanently.
Adjacent Innovations
State-of-the-art model performance with low vram requirements
CPU-only voice cloning demonstrating hardware minimization
Real-time applications solving constraints with commodity hardware
The Trade-Offs: What You Gain and What You Sacrifice
Democratization is not magic. It comes with hard trade-offs.
What You Lose
- Speed: Training a 235M-parameter model for five days on a 5080 is slow compared to a multi-GPU cluster scaling linearly. Batch sizes are constrained by VRAM.
- Scale: You will hit a ceiling. There’s a reason trillion-parameter models live in data centers.
- Maintenance: You are now the systems administrator, the ML engineer, and the data janitor. Pipelines fail, disks fill, tokenizers misbehave.
What You Gain
- Deep Understanding: You will learn the entire pipeline, from data sharding to loss curves, in a way that abstracted cloud services can never teach.
- Iteration Speed (for ideas): Changing your data mix, tweaking your architecture, or adjusting your training schedule doesn’t require a budget approval or a queued job. It’s a
git commitand arun.pycommand away. - True Ownership: Your model, your weights, your everything. No licenses, no usage caps, no external dependencies.
The New Frontier: What Comes Next?
The tools are getting better. Libraries like Unsloth are making optimization techniques like LoRA and Using unsloth and pytorch for fp8 efficiency on consumer gpus](/blog/fp8-reinforcement-learning-comes-to-consumer-gpus-with-unslotted-efficiency-gains) more accessible. The community is sharing not just code, but pain points and solutions.
The next wave won’t just be about replicating what big labs do with fewer resources. It will be about exploring niches they ignore. A model perfectly attuned to a specific scientific domain, trained on a corpus no large corporation would ever bother with. A hyper-specialized coding assistant for a legacy programming language. A storytelling AI that understands the specific rhythm of your favorite author.
The era of the basement-built LLM is here. The hardware is on your desk. The software is open-source. The only missing ingredient is the audacity to start. The dirty secret? The hardest part isn’t the math or the code, it’s believing you can do it in the first place. Once you start, the path from raw text to a model that answers your questions, even if those answers are sometimes silly, is a path of pure, unmediated creation. And that’s a feeling no API call can provide.