Welcome to Alibaba’s open-source gambit, a high-stakes strategy where the models keep getting better even as the talent pool evaporates, and where Qwen3.5’s technical dominance runs headlong into the brutal economics of keeping the lights on.
The Quantization Miracle Nobody Saw Coming
While the corporate drama unfolded, Unsloth dropped what they jokingly called their “final” GGUF update for Qwen3.5 (the community immediately noted this had qwen3.5_gguf_final_final_v2 vibes). The results are staggering enough to make you question why anyone is still paying API fees for closed models.
Unsloth’s latest benchmarks for Qwen3.5-122B-A10B and Qwen3.5-35B-A3B hit 99.9% KL divergence, a metric measuring how closely quantized models track their full-precision parents. But the real magic is in the Maximum KLD reduction. By directly optimizing for outlier suppression in their Mixture-of-Experts quantization, Unsloth achieved something that shouldn’t be possible: UD-Q4_K_XL is only 8% larger than previous iterations but cuts maximum KLD by 51%.
| Quant | Old GB | New GB | Max KLD Old | Max KLD New |
|---|---|---|---|---|
| UD-Q2_K_XL | 12.0 | 11.3 (-6%) | 8.237 | 8.155 (-1%) |
| UD-Q3_K_XL | 16.1 | 15.5 (-4%) | 5.505 | 5.146 (-6.5%) |
| UD-Q4_K_XL | 19.2 | 20.7 (+8%) | 5.894 | 2.877 (-51%) |
| UD-Q5_K_XL | 23.2 | 24.6 (+6%) | 5.536 | 3.210 (-42%) |
What this means practically: you can now run Qwen3.5-35B-A3B on a 22GB MacBook with near-native performance, or squeeze the 397B-A17B behemoth onto a single 24GB GPU with MoE offloading, hitting 25+ tokens per second. The “intelligence density”, a term that actually means something when you’re comparing a 4B parameter model that outperforms 480B-parameter behemoths on coding benchmarks, is now accessible to anyone with consumer hardware.
The Performance Gap That Isn’t
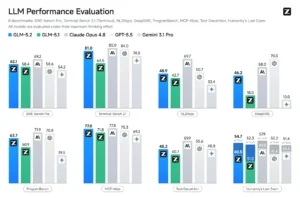
Artificial Analysis benchmarks place Qwen3.5-397B-A17B firmly in the tier of Gemini 3 Pro, Claude Opus 4.5, and GPT-5.2, a remarkable achievement for a model you can download and run locally without asking permission or signing a terms-of-service agreement that reads like a corporate surveillance manifesto.
The smaller models tell an even more interesting story. Qwen3.5-27B in thinking mode sits “almost at the peak” of performance benchmarks, while the 35B-A3B variant delivers 3x the inference speed of the 27B dense model with minimal quality loss. For developers, this creates a bizarre inversion: the “smaller” MoE model is often the better choice than the dense one, provided you have the VRAM to hold the mostly-idle sparse experts.
But here’s where it gets spicy. The community has noticed that Qwen3.5-122B seems to underperform relative to its parameter count, sitting below the 27B in some non-reasoning benchmarks. The counter-argument? It’s 3x faster at the same intelligence level, and in production inference, throughput often beats benchmark bragging rights.
The Open-Source Pressure Cooker
Eddie Wu’s internal memo, translated by Qwen3.5 itself (a nice touch of dogfooding), promised to “further increase R&D investment” and “intensify efforts to attract top talent.” The irony is thick enough to cut with a knife. The talent is leaving precisely because of the tension between open-source ideals and commercial reality.
Lin Junyang wasn’t just a tech lead, he was Alibaba’s youngest P10 executive, the architect of a model family that hit 700 million downloads on Hugging Face and spawned 180,000 derivative models. His departure, along with Binyuan Hui (Qwen Code lead) and others, represents more than resume shuffling. It signals a fundamental conflict: open-source builds community, but it doesn’t directly pay for the compute clusters required to train 397B-parameter models.
The new KPIs tell the story. Old metrics like Hugging Face downloads and community forks don’t cut it anymore. Alibaba needs Qwen to drive commercial success in enterprise markets and consumer apps, a pressure that sits uneasily with a research team optimized for publication and open release. When your model is given away under Apache 2.0, the path to ROI becomes circuitous: cloud compute, API services, and ecosystem lock-in rather than licensing fees.
The DeepSeek Variable
If Alibaba represents the tension between open-source and commercialization, DeepSeek represents the existential threat that keeps the former honest. As one observer noted, DeepSeek’s continued release of open-weight models creates a “check against a broader retreat from openness.” When a well-funded competitor gives away models that match or exceed your own, the cost of closing your weights becomes market share suicide.
This dynamic explains why Wu is doubling down publicly even as the talent walks. Qwen’s open-source strategy isn’t charity, it’s a calculated bet that ecosystem dominance and developer mindshare translate eventually into cloud revenue and enterprise contracts. But the compute math is brutal. Training runs for frontier models cost millions, and every open release is a gift to competitors who didn’t pay for the training.
The Unsloth optimizations make this calculus even more complex. When the community can run your 397B model on local hardware with 4-bit quantization losing less than 1% accuracy (Benjamin Marie’s benchmarks show UD-Q4_K_XL at 80.5% vs original 81.3% on a 750-prompt mixed suite), the value of your API service diminishes. You’re no longer selling access to the model, you’re selling convenience and infrastructure.
The Technical Debt of Openness
There’s a technical cost to this strategy that doesn’t get enough attention. The Unsloth team noted they had to stay up “all night and not sleep” to get GGUFs ready for release day. The Qwen team itself has been burning midnight oil to maintain the release cadence that keeps them competitive with closed labs.
The new imatrix calibration datasets, chat template fixes for tool-calling, and the retirement of MXFP4 layers in favor of more robust quantization schemes, these aren’t trivial engineering efforts. They represent a continuous tax on the open-source strategy, a requirement to maintain parity with closed models that can simply ship a binary and call it done.
And yet, the benchmarks suggest it’s working. Qwen3.5-397B-A17B as an open-source challenger to GPT-5 and Claude Opus isn’t just marketing fluff, it’s a measurable reality on standard eval suites. The model supports 256K context across 201 languages, handles multimodal inputs, and offers hybrid reasoning modes that can be toggled on the fly.
What Happens Next
The community sentiment is clear: losing Lin and the founding team is “the end of an era.” But the infrastructure they’ve built, the model architectures, the training pipelines, the optimization techniques, remains. The question is whether Alibaba can maintain the velocity without the architects.
For practitioners, the immediate takeaway is clear: download the GGUFs while they’re hot. Unsloth’s “final” (for real this time, probably) update delivers local inference gains that were impossible six months ago. The Qwen3.5 family runs on hardware you probably already own, with performance that would have required API calls to San Francisco last year.
But the strategic takeaway is murkier. Alibaba is attempting to thread a needle no one’s successfully threaded before: maintaining frontier-model performance with open-source distribution while generating enough revenue to fund the next training run. The departures suggest the needle is getting sharper, or the thread is getting thinner.
The CEO can promise commitment to open-source. The benchmarks can prove the models work. But if the talent that bridges those two realities keeps walking out the door, Alibaba’s gambit becomes a question of whether open-source AI can survive its own success, or whether the economics of the closed model era will eventually swallow even the most committed holdouts.
For now, the GGUFs are on Hugging Face, the benchmarks are public, and the models run locally. Enjoy it while it lasts.