The 4B Model That Embarrasses Claude Sonnet: Why Specialization Kills the ‘Bigger is Better’ Myth
DeepFabric’s fine-tuned Qwen3-4B achieves 93.5% tool calling accuracy, crushing Claude Sonnet 4.5 (80.5%) and Gemini Pro 2.5 (47%). Here’s how synthetic data, real tool execution, and domain focus rewrite the rules for cost-effective AI agents.
A new open-source framework called DeepFabric just proved that a 4-billion parameter model, fine-tuned on domain-specific synthetic data, can demolish frontier models at tool calling. The results aren’t incremental, they’re embarrassing.
The Frontier Model Trap: Why Generalists Fail at Tool Calling
Frontier models are remarkable generalists. They write poetry, debug code, analyze legal documents, and engage in nuanced reasoning. But when you need an agentic system to reliably call tools, whether it’s a Blender 3D operation, a database query, or an API endpoint, this versatility becomes a liability.
- Hallucinated tool names: Models invent functions that don’t exist in your schema
- Schema violations: JSON outputs that don’t match expected parameters, breaking integrations
- Reasoning gaps: Complex multi-step interactions cause state loss
- Cost and latency: Each API call burns budget and adds round-trip delay
- Data privacy: Sensitive operations require sending data to third-party servers
The issue isn’t that frontier models are bad. It’s that tool calling is a narrow, well-defined task that doesn’t require the vast knowledge base of a 175B parameter model. You’re paying for capabilities you don’t need while getting inconsistent results on the task you actually care about.
DeepFabric’s Counter-Intuitive Bet: Synthetic Data, Real Execution, and Specialization
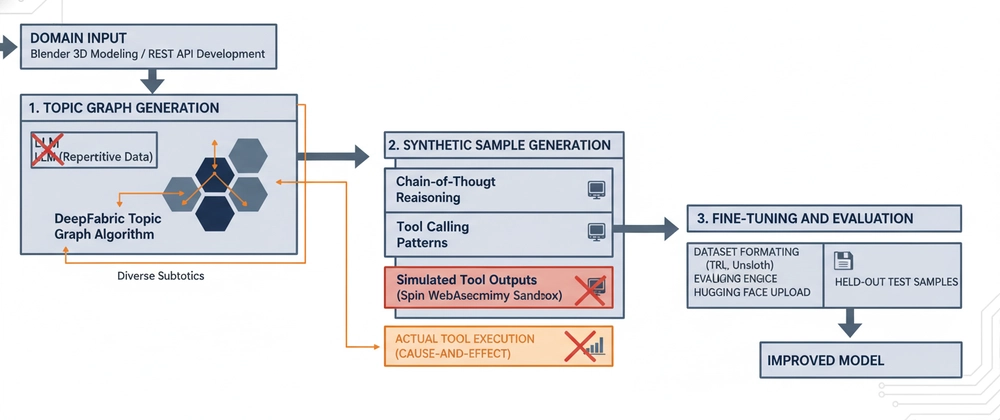
DeepFabric takes the opposite approach: instead of scaling up, it scales in with surgical precision. The framework generates synthetic training data through a three-stage pipeline that ensures both breadth and authenticity.
1. Topic Graph Generation: Avoiding the Repetition Trap
Most synthetic data generators produce repetitive, homogeneous samples that lead to catastrophic overfitting. DeepFabric uses a topic graph algorithm that builds a directed acyclic graph of subtopics from a domain prompt.
For Blender operations, this means the system automatically generates samples covering everything from basic mesh manipulation to advanced rigging, ensuring comprehensive coverage without redundancy. Each node in the graph becomes a seed for generating training examples, creating natural diversity while staying on-topic.
2. Real Tool Execution: No More Hallucinated Results
Here’s where DeepFabric diverges radically from other frameworks. Instead of simulating tool outputs, which teaches models to guess at results, it executes tools in isolated WebAssembly sandboxes using the Spin framework.
When a training sample requires calling blender.create_cube(), the system actually invokes Blender, captures the real output, and includes any errors or stack traces in the training data. This means models learn from authentic cause-and-effect relationships, not fabricated responses. If a tool call fails, the model sees the actual error message and learns to avoid that pattern.
3. Fine-Tuning with Unsloth: Making 4B Parameters Punch Above Their Weight
The generated dataset plugs directly into Unsloth, an optimized training framework that reduces VRAM usage by 4x and speeds up fine-tuning by 2-4x. On a free Google Colab T4 GPU, you can train a Qwen3-4B model in under an hour using LoRA adapters that modify only 1% of parameters.
The result? A specialist model that understands exactly when to call tools, which tools to select, and how to format parameters within strict schemas.
The Blender MCP Stress Test: How a 4B Parameter Model Beat the Giants
To validate the approach, the DeepFabric team chose the Blender MCP server, a notoriously challenging toolset for agentic systems. The evaluation measured three critical metrics:
| Model | Tool Selection Accuracy | Parameter Accuracy | Overall Score |
|---|---|---|---|
| DeepFabric Fine-Tuned (Qwen3-4B) | 93.50% | 93.50% | 93.50% |
| Claude Sonnet 4.5 | 80.50% | 80.50% | 80.50% |
| Google Gemini Pro 2.5 | 47.00% | 47.00% | 47.00% |
A 4B parameter model achieving 93.5% accuracy while running locally on consumer hardware isn’t just impressive, it’s paradigm-shifting. The model correctly calls tools like blender.mesh_subdivide() with proper parameters ({"levels": 2, "quad_method": 'SHORTEST_DIAGONAL'}) while the frontier models struggle with basic schema compliance.
The gap widens on multi-step operations. When a task requires chaining five tool calls with conditional logic based on previous results, the fine-tuned model maintains perfect state tracking while Claude and Gemini’s generalist architectures lose coherence.
Inside the Pipeline: From Topic Graph to Trained Specialist
Let’s walk through the actual process using the publicly available Colab notebook:
# Install DeepFabric
pip install deepfabric
# Generate a synthetic dataset for your domain
deepfabric generate \
--topic-prompt "Blender 3D modeling operations" \
--mode graph \
--depth 4 \
--degree 4 \
--num-samples 100 \
--provider openai \
--model gpt-4o \
--output-save-as blender-dataset.jsonlThis creates a dataset where each sample includes:
– A user query requiring tool use
– Chain-of-thought reasoning steps
– Actual tool calls with real execution traces
– Properly formatted responses
from datasets import load_dataset
from transformers import AutoTokenizer
dataset = load_dataset("json", data_files="blender-dataset.jsonl")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
def format_sample(example):
messages = example["messages"]
return {"text": tokenizer.apply_chat_template(messages, tokenize=False)}
formatted_ds = dataset.map(format_sample)Training with Unsloth uses optimized LoRA adapters:
from unsloth import FastLanguageModel
from trl import SFTTrainer
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="Qwen/Qwen2.5-7B-Instruct",
max_seq_length=2048,
load_in_4bit=True,
)
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
lora_alpha=16,
)
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=formatted_ds,
args=SFTConfig(output_dir="./output", num_train_epochs=3),
)
trainer.train()The entire pipeline runs on a free Colab T4 GPU in under 90 minutes.
Why This Works: The Narrow Task Advantage
Tool calling isn’t creative writing. It’s a deterministic pattern-matching problem with four requirements:
1. Recognition: Identify when external capabilities are needed
2. Selection: Choose the correct tool from available options
3. Formatting: Adhere to strict JSON schemas for parameters
4. Interpretation: Process results and decide next actions
These are learnable constraints. A small model trained exclusively on domain-specific examples internalizes the exact syntax and semantics required. It doesn’t need to know about Shakespeare or quantum physics, it just needs to reliably call blender.apply_modifier() with the right arguments.
This specialization advantage compounds on edge cases. The fine-tuned model handles rare Blender operations that appear only 0.1% in general training data because DeepFabric’s topic graph ensures they’re represented proportionally in the synthetic dataset.
Replicating the Results: Your Specialist in an Afternoon
You don’t need a research lab to reproduce these results. The GitHub repository provides everything:
Step 1: Generate your dataset
export OPENAI_API_KEY="your-key"
deepfabric generate --config your-domain.yamlStep 2: Train with Unsloth
Use the provided Colab notebook or run locally. The framework auto-formats data for TRL, Unsloth, or Axolotl.
Step 3: Evaluate
from deepfabric.evaluation import Evaluator, EvaluatorConfig
config = EvaluatorConfig(
inference_config=InferenceConfig(
model_path="./output/checkpoint-final",
backend="transformers"
),
)
evaluator = Evaluator(config)
results = evaluator.evaluate(dataset=eval_ds)
print(f"Overall Score: {results.metrics.overall_score:.2%}")The evaluation engine measures tool selection accuracy, parameter accuracy, and execution success rate against held-out test samples, exactly the metrics that matter for agentic systems.
Beyond Blender: The Specialist Model Revolution
The Blender demo is a proof-of-concept. The real impact comes from applying this pattern to any domain requiring reliable tool use:
- Developer tools: Git operations, code execution, CI/CD pipeline control
- Data pipelines: SQL queries, API orchestration, data transformation
- Business automation: CRM updates, email composition, calendar management
- Creative software: Image editing macros, audio processing chains
- IoT systems: Device control, sensor data collection, automation scripts
For each domain, you get a small, fast, private model that beats generalists on the specific task. The economics are compelling: a fine-tuned 4B model running on a $500 GPU can handle thousands of requests per dollar, while API calls to frontier models cost 10-100x more.
FunctionGemma: The 270M Parameter Proof of Concept
Google’s FunctionGemma demonstrates the extreme end of this paradigm. At just 270M parameters, small enough to run on a smartphone, it achieves 85% accuracy on function calling tasks after fine-tuning, up from 58% zero-shot.
The model uses special tokens to structure tool declarations, calls, and responses:
<start_function_declaration>
{"name": "get_weather", "parameters": {"city": "string"}}
<end_function_declaration>
User: What's the weather in London?
<start_function_call>
call:get_weather{"city": "london"}
<end_function_call>Fine-tuned on the Android “Mobile Actions” dataset, it executes device operations locally at 50 tokens/second on a Pixel 8, completely offline. This isn’t just cost-effective, it’s a privacy revolution.
The Bottom Line: Bigger Isn’t Better, It’s Just Bigger
The DeepFabric results expose a fundamental flaw in the “scale at all costs” ideology. For narrow, high-value tasks like tool calling, specialization trumps generalization every time.
A 4B parameter model trained on high-quality synthetic data with real execution traces doesn’t just match frontier models, it embarrasses them. The gap isn’t closing, it’s widening as techniques like topic graph generation and WebAssembly-based execution produce increasingly targeted training data.
The implications stretch beyond tool calling. We’re witnessing the emergence of expert micro-models, tiny specialists that handle specific tasks with superhuman reliability while running on commodity hardware. The future isn’t one massive model that does everything. It’s a fleet of small models that each do one thing perfectly.
Try the Colab notebook today. Your frontier model API budget will thank you.

Resources
- DeepFabric GitHub: github.com/always-further/deepfabric
- Colab Notebook: Train a 4B Model to Beat Claude Sonnet
- FunctionGemma: google/functiongemma-270m
- Evaluation Metrics: DeepFabric Docs



