Qwen-AgentWorld: The 3B-Active Model That Simulates Entire Operating Systems
Here’s the thing about building AI agents: every single one of them needs an environment to interact with. You want to test a tool-calling agent? You need a live MCP server. A terminal agent? You’re spinning up containers. A web agent? Hope you enjoy watching a browser automation pipeline crash at 3 AM.
The infrastructure tax on agent development is massive. And until now, there hasn’t been a great alternative to “just run the damn thing.”
What the Hell Is a “Language World Model”?
The positioning here is worth unpacking because it’s easy to misunderstand. This isn’t a general-purpose assistant. It’s not even really an “agent” in the traditional sense. Qwen-AgentWorld is built to sit on the environment side of the agent loop.
You give it the action history and a new action, say, a bash command or a GUI click, and it predicts the next observation. The terminal output. The screen state. The API response.
This matters because most work on AI agents has focused on the agent, the thing that decides what to do. The environment side has been treated as a fixed cost: you need a real terminal, a real browser, a real Android emulator. That’s expensive, slow, and hard to scale.
Three-Stage Training Pipeline
- Continual Pre-Training (CPT): Injects general-purpose world modeling capabilities from state transition dynamics and augmented professional corpora.
- Supervised Fine-Tuning (SFT): Activates next-state-prediction reasoning.
- Reinforcement Learning (RL): Sharpens simulation fidelity through a hybrid rubric-and-rule reward framework.
The model was trained on more than 10 million real-world interaction trajectories across seven domains. And crucially, it’s a native world model — environment modeling is the training objective from the CPT stage onward, not a post-hoc adaptation on a general-purpose LLM.
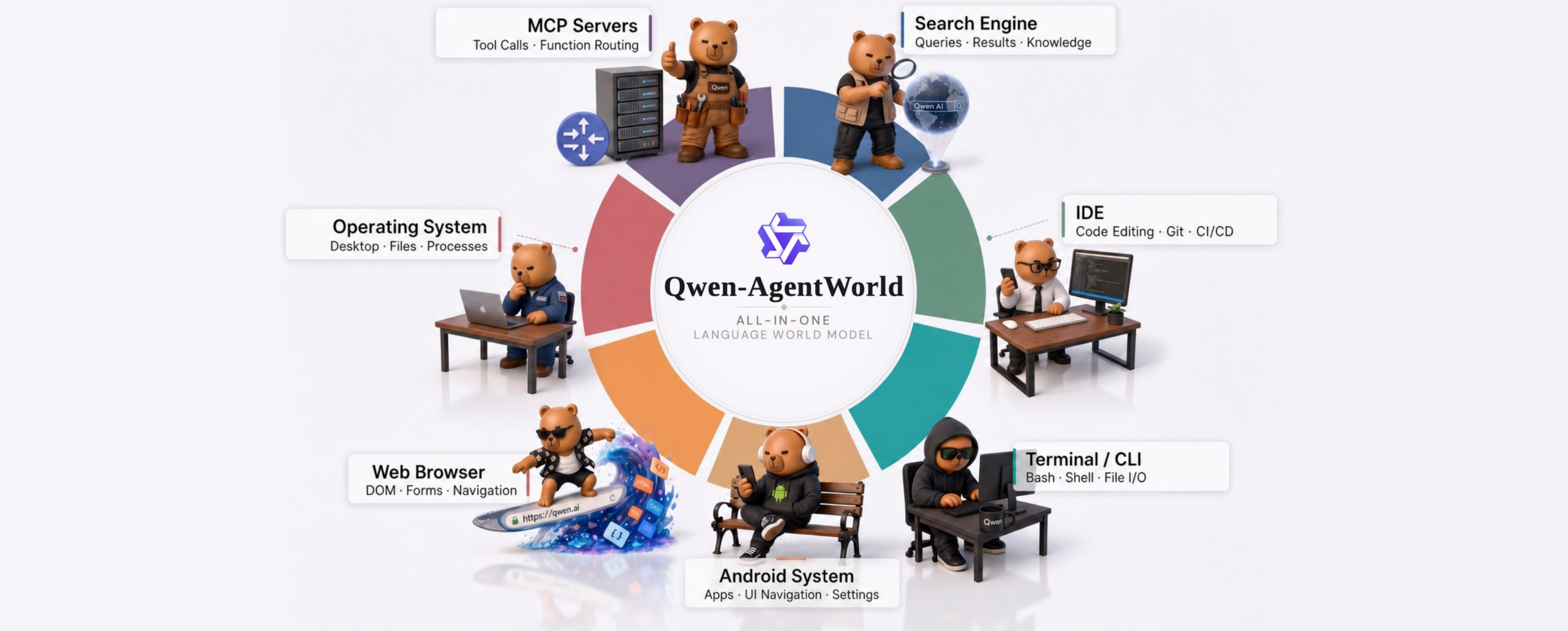
Seven Domains, One Model
The scope is what makes this interesting. Previous attempts at environment simulation have been narrow — a terminal emulator here, a toy web environment there. Qwen-AgentWorld covers:
| Domain | What It Simulates |
|---|---|
| MCP / Tool Calling | API responses from tool invocations |
| Search | Search engine result pages |
| Terminal | Linux command-line output |
| Software Engineering | Code execution results, build outputs |
| Android | Mobile GUI state after actions |
| Web | Browser DOM and page state |
| Operating System | Desktop GUI interactions |
That’s text-based environments (terminal, search), structured tool outputs (MCP, SWE), and GUI environments (Android, Web, OS) all within a single model.
The architecture is worth noting too. It’s based on Qwen3.5-35B-A3B-Base and uses a hybrid of Gated DeltaNet and Gated Attention layers, with 256 experts (8 routed + 1 shared activated per token). The context length is a generous 262,144 tokens — necessary for simulating long, multi-turn agent trajectories.
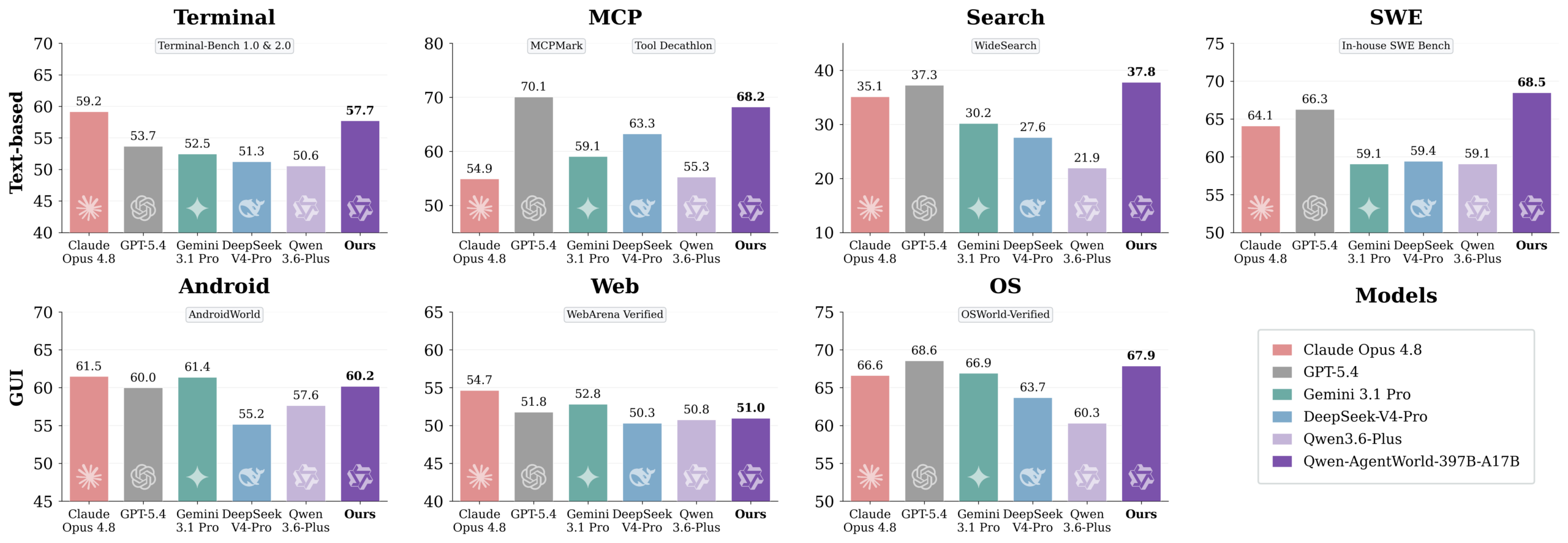
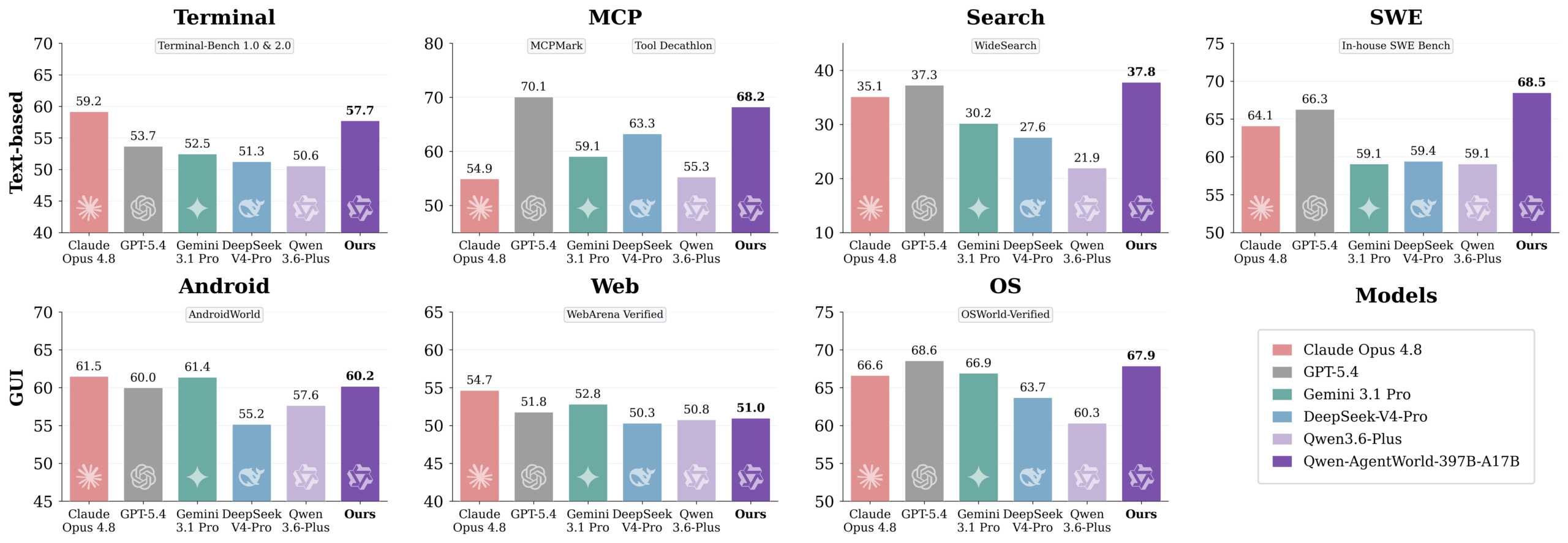
Does It Actually Work?
The benchmark results are… surprising. In an era where frontier model comparisons have become a tired ritual of “my API beats your API”, Qwen-AgentWorld actually brings something new to the table.
AgentWorldBench evaluates language world models across five dimensions: Format, Factuality, Consistency, Realism, and Quality. Here’s how Qwen-AgentWorld-35B-A3B stacks up:
| Model | Overall |
|---|---|
| GPT-5.4 | 58.25 |
| Claude Opus 4.8 | 56.59 |
| Qwen-AgentWorld-35B-A3B | 56.39 |
| Qwen3.5-397B-A17B | 54.74 |
| DeepSeek-V4-Pro | 52.97 |
A 3B-active model matching GPT-5.4 overall is eyebrow-raising. But the domain breakdown tells a more nuanced story. Qwen-AgentWorld-35B-A3B scores an impressive 65.63 on SWE simulation and 65.92 on OS simulation, both near the top. Search simulation at 36.69 is notably strong, second only to the larger Qwen-AgentWorld-397B variant.
The larger Qwen-AgentWorld-397B-A17B actually tops the overall leaderboard at 58.71, edging out GPT-5.4. That’s a 17B-active model beating a frontier proprietary model on environment simulation.
Beyond Benchmarks: What You Can Actually Do With This
The interesting stuff isn’t on the leaderboard — it’s in the applications section of the paper.
Generalizable Environment Scaling
The team used Qwen-AgentWorld-397B-A17B to run Sim RL on 4,000 out-of-distribution OpenClaw environments. The result? Models trained on simulated environments outperformed those trained only on real environments:
| Model | Claw-Eval | QwenClawBench |
|---|---|---|
| Qwen3.5-35B-A3B | 65.4 | 47.9 |
| + Sim RL (w/ AgentWorld) | 69.7 | 55.0 |
| Δ | +4.3 | +7.1 |
Controllable Simulation
This is where it gets wild. The model can inject targeted perturbations into simulated environments. Want to test how your agent handles a filesystem error? A timeout? A malformed API response? You can control the simulation to generate failure cases that would be rare in real environments.
For MCP-based tasks, controlled simulation improved performance from 31.5 to 36.1 on Tool Decathlon and from 24.6 to 33.8 on MCPMark — a 12.3 point gain.
Fictional-World Construction
The team went full Borges. They constructed entirely fictional, self-consistent worlds for training — complete with made-up databases, fake search engines, and synthetic documents. Agents trained on these invented worlds generalized to real search tasks, improving WideSearch F1 Item scores from 34.02 to 50.31.
Agent Foundation Model Warm-Up
World model training acts as a highly effective warm-up for downstream agent tasks. Just training a model to simulate environments — even on single-turn, non-agentic trajectories — transfers to multi-turn, tool-calling tasks:
| Benchmark | Qwen3.5-35B-A3B-SFT | + LWM RL | Δ |
|---|---|---|---|
| Terminal-Bench 2.0 | 33.25 | 39.55 | +6.30 |
| SWE-Bench Verified | 64.47 | 67.86 | +3.39 |
| BFCL v4 | 62.29 | 71.25 | +8.96 |
The out-of-domain gains on Claw-Eval (+11.28) and WideSearch (+12.79) are particularly striking — the world model is learning something genuinely transferable, not just memorizing environment dynamics.
Setting This Up: Not Just Theory
Qwen-AgentWorld-35B-A3B is available under Apache 2.0 license and runs on standard inference frameworks. Here’s the quickstart:
Deploy with vLLM
vllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--trust-remote-codeUse it for terminal simulation
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
messages = [
{
"role": "system",
"content": "You are a language world model simulating a Linux terminal environment. "
"Given the user's command, predict the terminal output."
},
{
"role": "user",
"content": "Action: execute_bash\nCommand: ls -la /home/user/project/"
}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=2048, temperature=0.6)The recommended sampling parameters are temperature=0.6, top_p=0.95, top_k=20, with a generous output length of 32,768 tokens for complex trajectories.
The Catch: Where This Gets Complicated
The honest take: simulator fidelity at 50-60% across domains raises real questions about what kind of RL signal you’re actually feeding your agent. A critical comment on the Hugging Face paper page laid out the issues clearly:
- Problem 1: 50-60% fidelity is noisy for RL. At that fidelity level, agents might learn to exploit the simulator’s hallucination patterns rather than real environment dynamics. The paper doesn’t measure what agents learned wrong.
- Problem 2: Benchmark self-dealing. AgentWorldBench was built by the same team. The rubric design, scoring dimensions, and judge prompts all favor behaviors their model was trained to exhibit. Independent replication would be valuable here.
- Problem 3: No fidelity-vs-performance curve. Without understanding at what simulator accuracy the RL gains disappear, it’s hard to know whether the improvements come from the world model itself or from extra training compute.
- Problem 4: Cost comparison is missing. Running a 35B MoE model with long chain-of-thought per environment step might be more expensive than a real Docker container for most common use cases. The paper doesn’t provide actual cost comparisons.
- Problem 5: GUI domains dodge the hard problems. Representing GUI state as accessibility trees is a principled choice, but real GUI agents deal with pixel-level rendering bugs, dynamic animations, and states that accessibility trees don’t capture.
For a deeper dive into the broader MoE landscape and where this fits, check out Qwen’s previous MoE architecture with similar 3B active parameter design.
What This Means for Agent Development
The skeptic’s view: world models are a solution in search of a problem. Real environments exist. Containers are cheap. Just run the real tools.
The optimist’s view: environment simulation is a bottleneck that the industry hasn’t taken seriously enough. Every agent team I know struggles with scaling evaluation, generating diverse test scenarios, and training models on environments that are expensive or dangerous to run in production. A model that can simulate thousands of environments cheaply — even with imperfect fidelity — unlocks workflows that are currently impractical.
The pragmatist’s take: Qwen-AgentWorld is useful now for specific use cases — generate synthetic training data, run cheap evaluation rollouts, test edge cases that are rare in real environments. For production-grade RL training? Maybe wait for fidelity to improve, or use it as a complement to real environments rather than a replacement.
For context on how this compares to larger models in the ecosystem, see Qwen’s larger MoE model providing context on Alibaba’s MoE strategy.
The Bottom Line
Qwen-AgentWorld-35B-A3B is not a revolution. It’s a genuinely useful tool in a space that’s been underserved. The model architecture is clever, the training methodology is sound, and the results — while not perfect — suggest that language world models are a viable path forward for agent environment simulation.
The MoE design (35B total, 3B active) means it runs on hardware that’s actually accessible. The Apache 2.0 license means nobody’s going to block you from using it. And the evaluation framework means you can actually measure whether it’s working for your use case.
The Qwen team has a pattern here of releasing models that punch above their weight class — Qwen3.5-397B-A17B was a similar exercise in making massive models practical. AgentWorld extends that philosophy to a new domain: not just making models smaller, but making them do things that general-purpose models can’t.
If you’re building agents, this is worth your attention. Not because it’s perfect, but because it solves a problem you’ve been ignoring. And that’s always where the interesting tools come from.
Technical report: arXiv:2606.24597
Model weights: Hugging Face
GitHub repository: QwenLM/Qwen-AgentWorld



