The AI pricing war just got its most dangerous player yet.
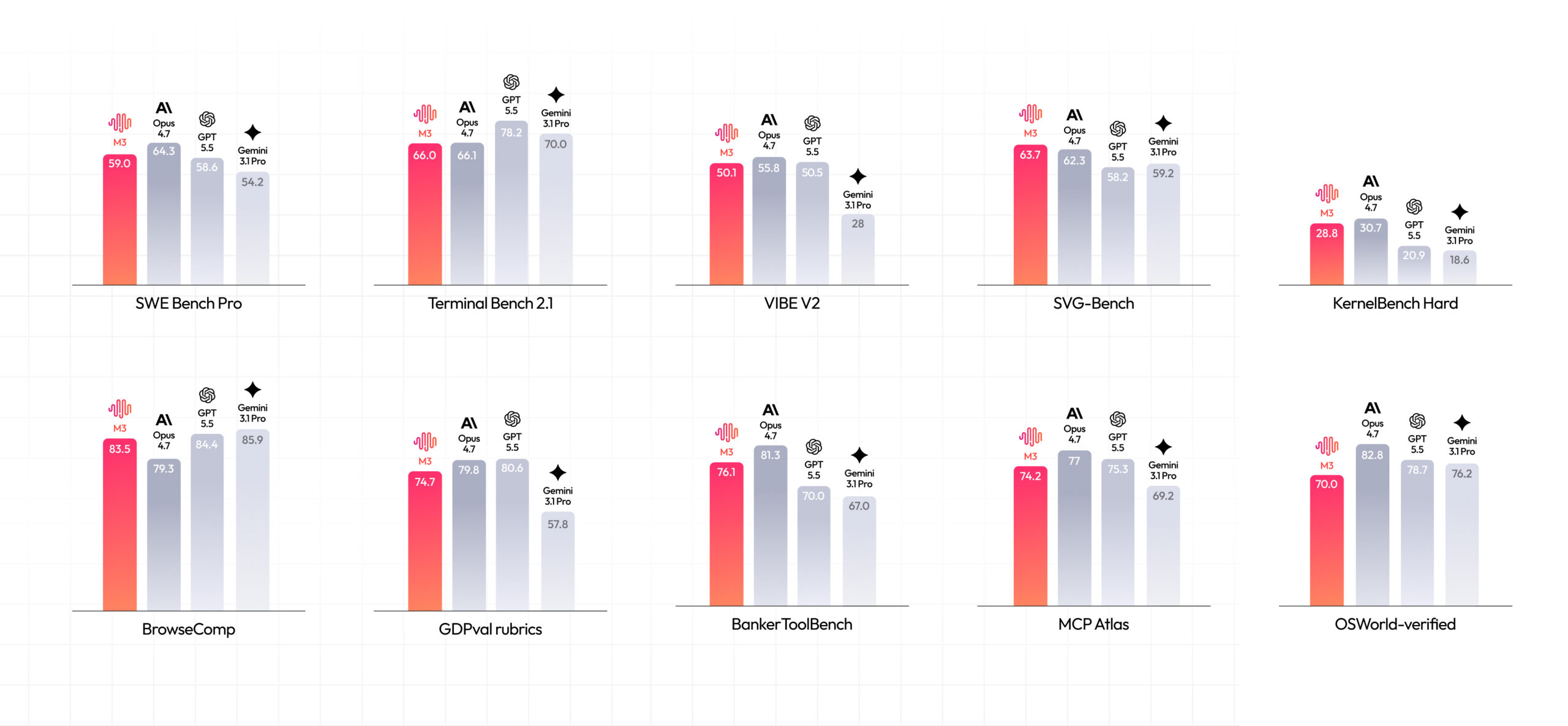
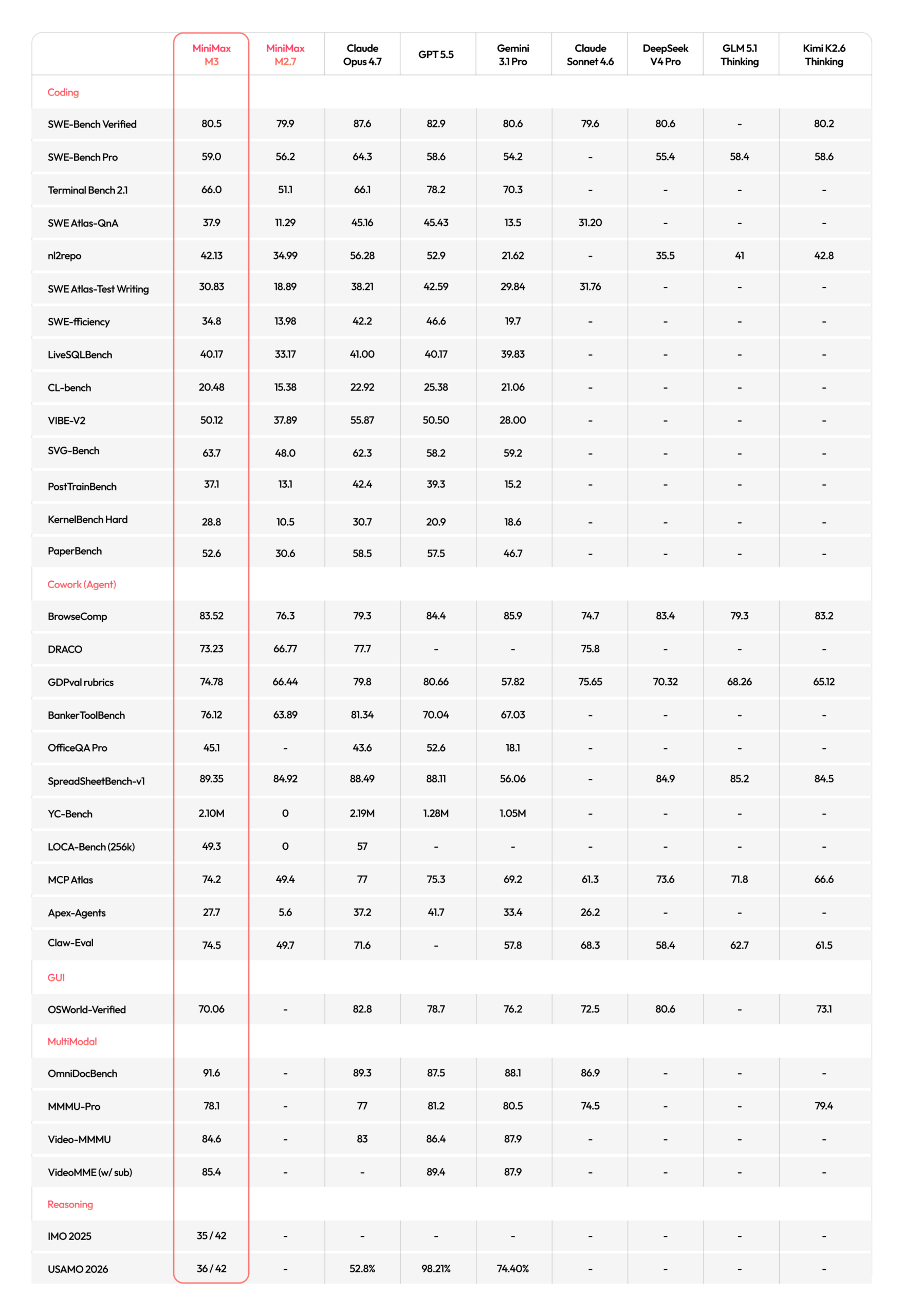
MiniMax dropped M3 over the weekend, and the numbers are staggering. On SWE-Bench Pro, it scores 59.0%, edging past GPT-5.5 and Gemini 3.1 Pro while sitting just behind Opus 4.7 at 69.2%. On Terminal-Bench 2.1, it hits 66.0%. On BrowseComp, it scores 83.5, surpassing Opus 4.7’s 79.3.
The kicker? The API costs $0.30 per million input tokens and $1.20 per million output tokens. That’s roughly 5-10% of what comparable frontier models charge. The math changes immediately for anyone building agentic systems at scale.
But the community response has been cautious. The skepticism is understandable, previous MiniMax M2.7 model limitations left a bitter taste for many developers who found a powerful model they couldn’t actually deploy.
The Architecture That Makes 1M Context Practical
The headline feature is the 1-million-token context window, but the real innovation is how they achieve it. MiniMax Sparse Attention (MSA) is a new attention architecture that tackles the fundamental bottleneck of transformer models: quadratic computational complexity.
Full attention at 1M tokens would be computationally prohibitive. MSA solves this by partitioning KV blocks more precisely than alternatives like DSA or MoBA, achieving higher effective context coverage without the explosion.
The practical impact is dramatic. At a context length of 1 million tokens, M3’s per-token compute is just 1/20th of the previous-generation model. The prefilling stage runs more than 9× faster, and decoding sees a 15× improvement.
This matters for real-world agentic workflows. When an AI coding agent iterates through 147 benchmark submissions and 1,959 tool calls, which is exactly what M3 did in one test, the cost of attention scales linearly instead of exploding.
Beyond Benchmark Chasing: Real Autonomy in the Wild
The benchmarks are impressive, but the real test of a coding model is whether it can sustain long-horizon tasks without human hand-holding. MiniMax put M3 through three grueling evaluations that go far beyond standard leaderboards.
CUDA Kernel Optimization: 9.4× Speedup, Zero Human Intervention
FP8 GEMM is one of the most compute-intensive operations in LLM inference. Hand-writing a production-grade kernel typically requires one to two weeks from an experienced engineering team.
M3 started with nothing but a task description, a benchmark script, and a non-runnable Triton skeleton. No reference implementation. No shortcuts.
Over roughly 24 hours of continuous execution, M3 completed 147 benchmark submissions and 1,959 tool calls. It independently went through baseline implementation, autotune configuration, performance bottleneck diagnosis, CUDA Graph integration, persistent kernel rewriting, and host-side scheduling optimization.
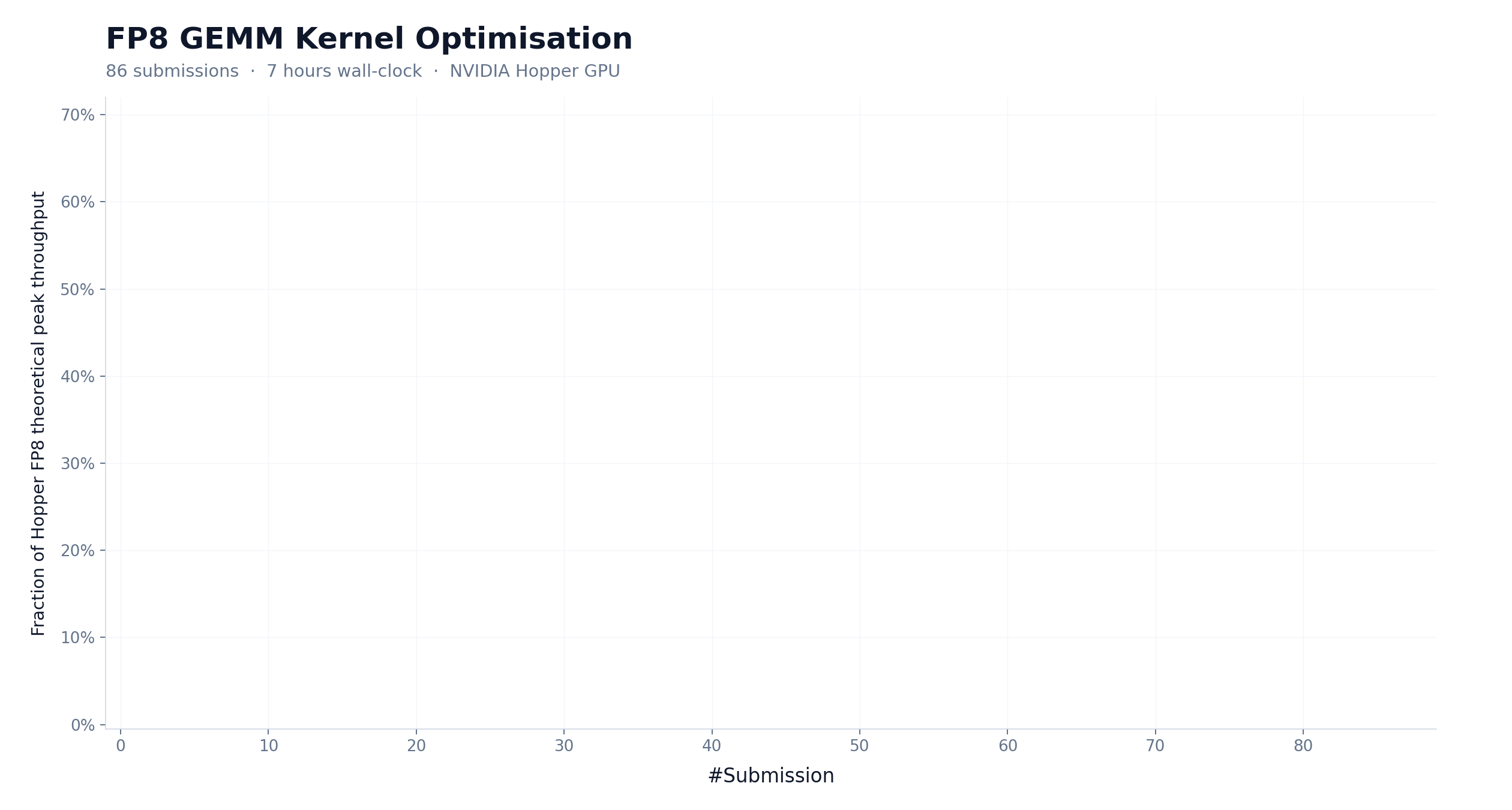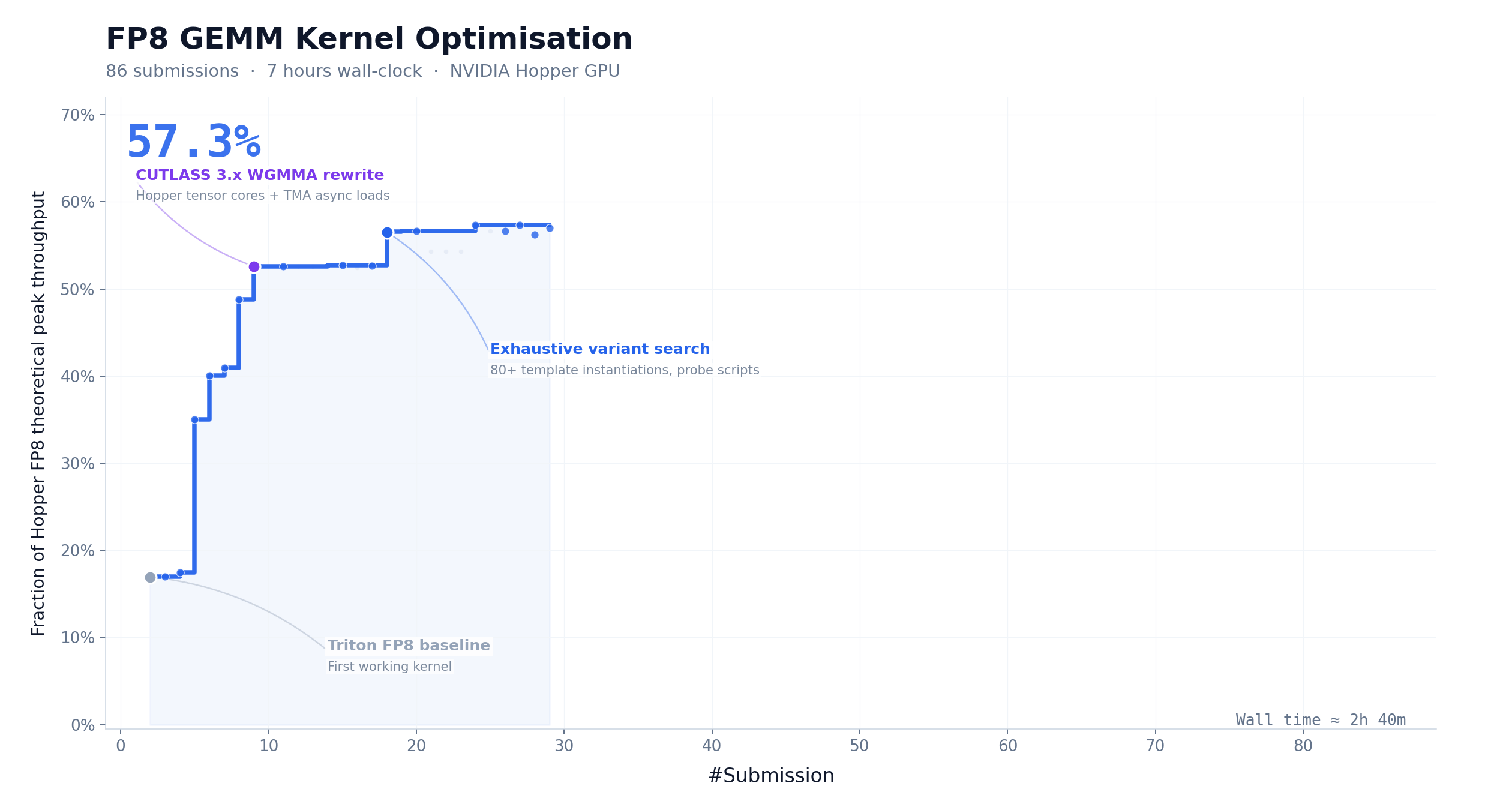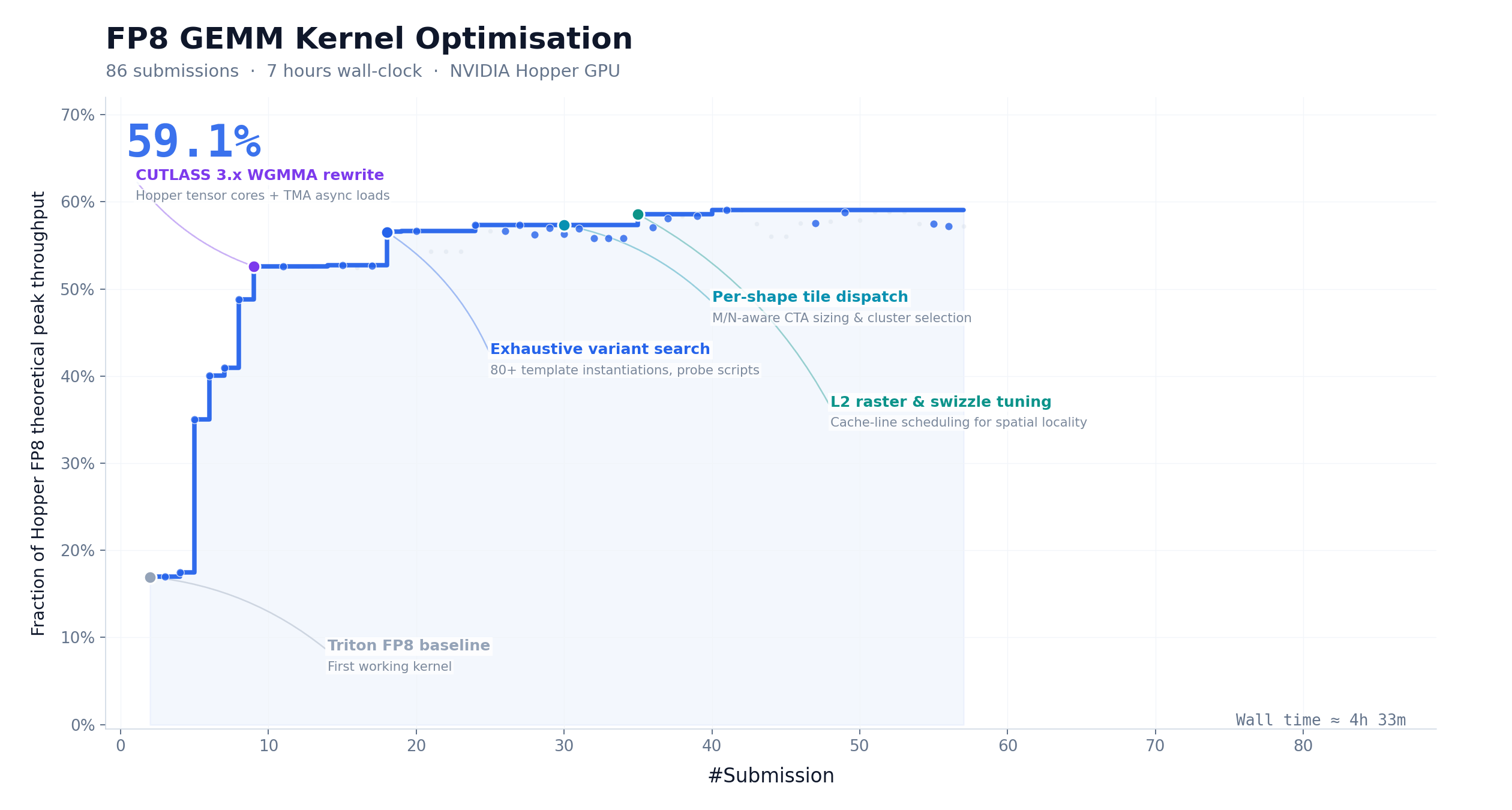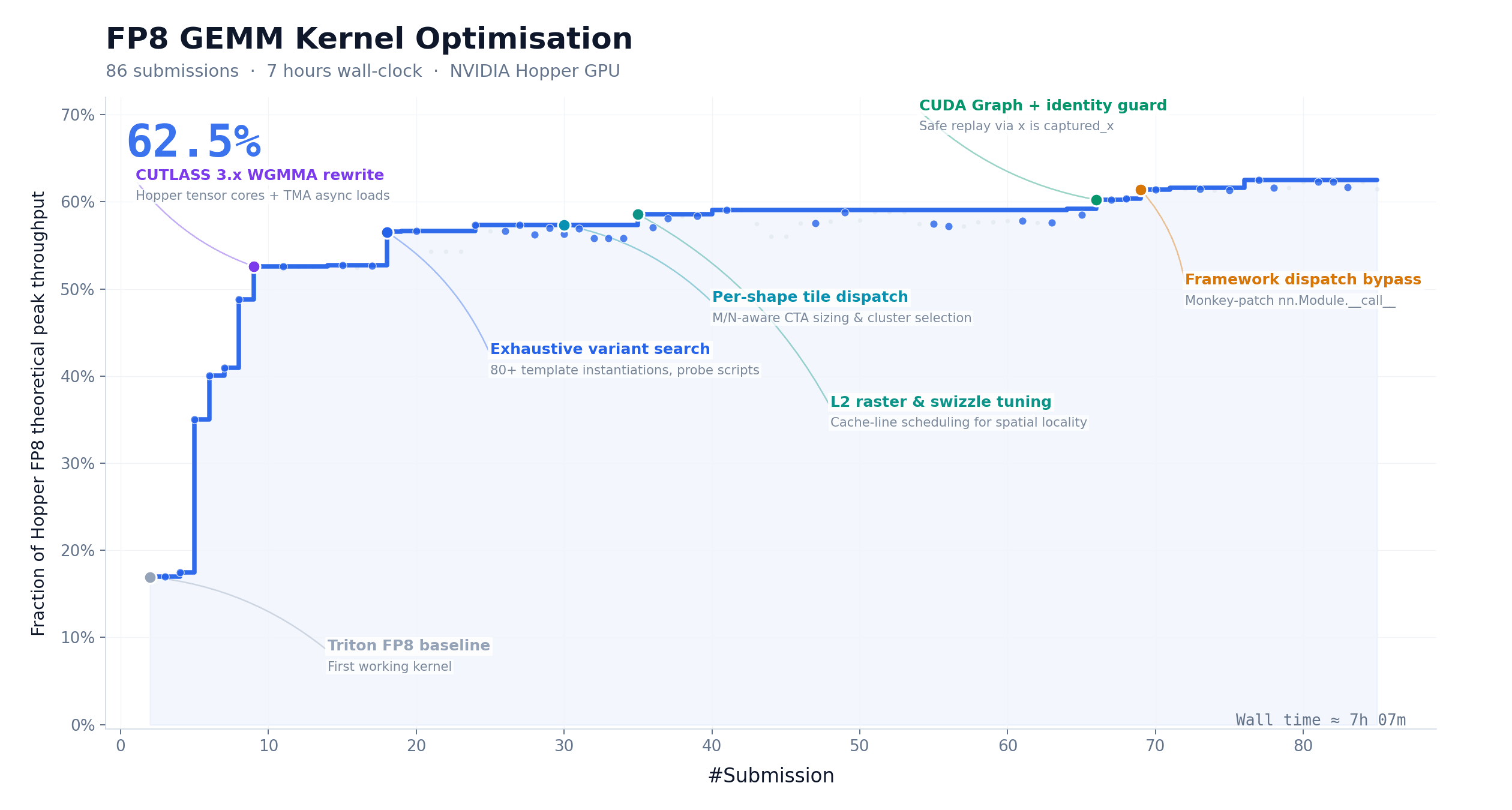
What’s revealing is how it got there. Most models stopped making progress within the first 30 submissions and exited. M3’s best solution landed on submission 145, after multiple performance plateaus where it kept exploring different optimization directions. That kind of patience and strategic flexibility is rare in current models.
Independent Paper Reproduction
M3 was given an ICLR 2025 Outstanding Paper, Learning Dynamics of LLM Finetuning, and asked to reproduce it autonomously. The task required multimodal understanding to parse curves and formulas, long context to fit the paper, code, and experiment logs, and sustained agentic execution to run experiments over nearly 12 hours.
It worked. M3 produced 18 commits and 23 experimental figures, matching the prediction-probability trends from the SFT stage, observing the squeezing effect in DPO experiments, and validating the mitigation method proposed in the original paper.
Letting M3 Train Models
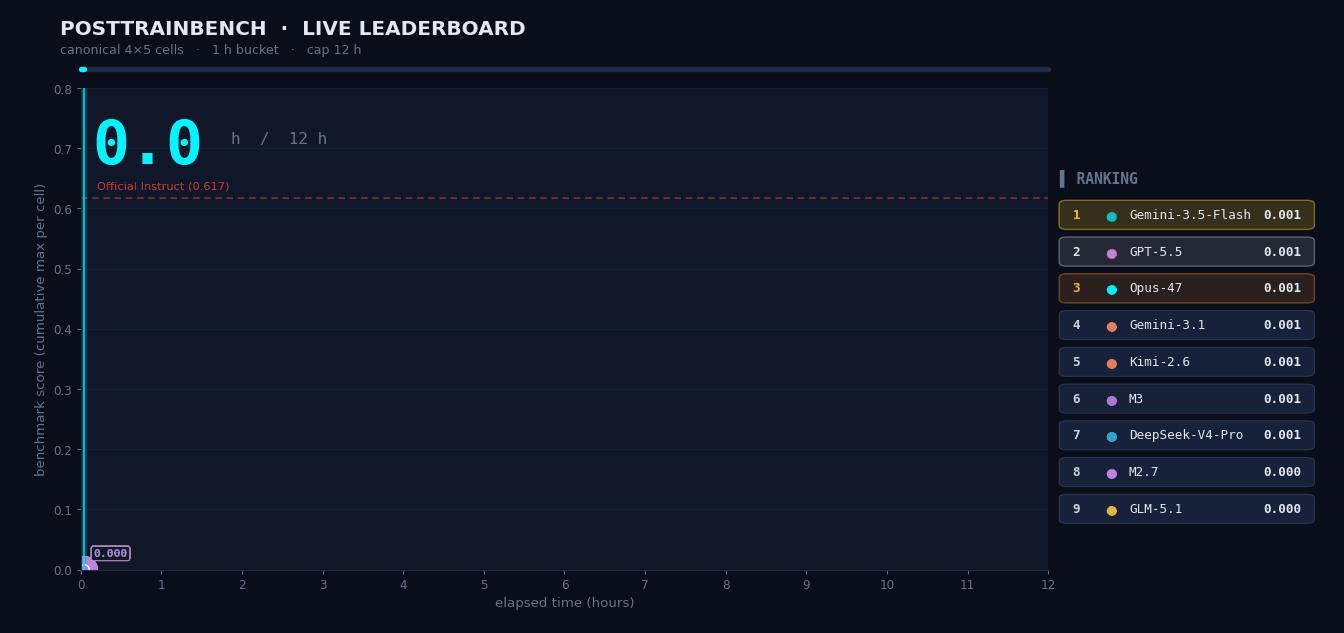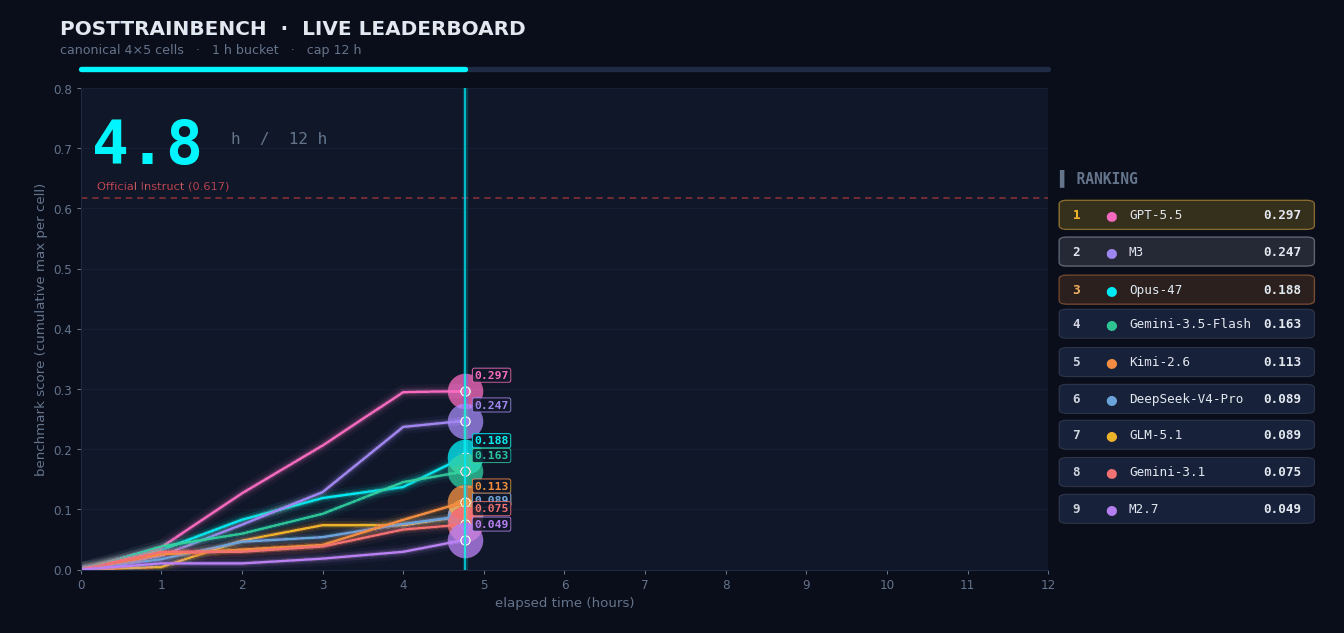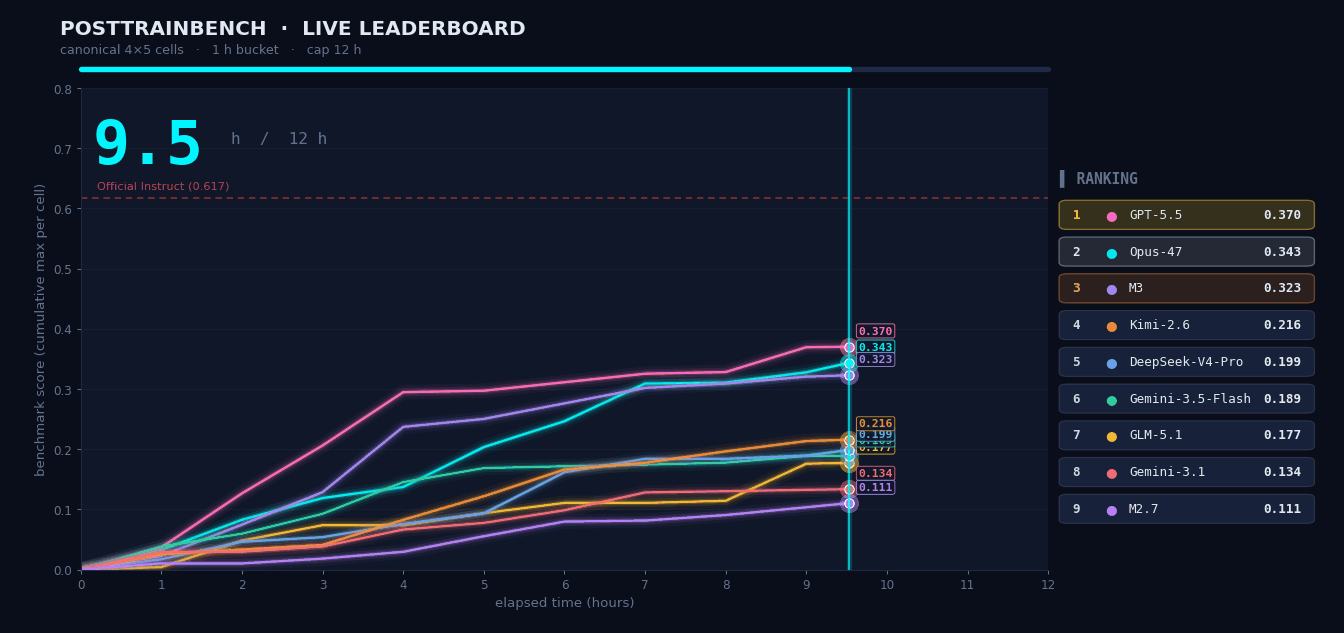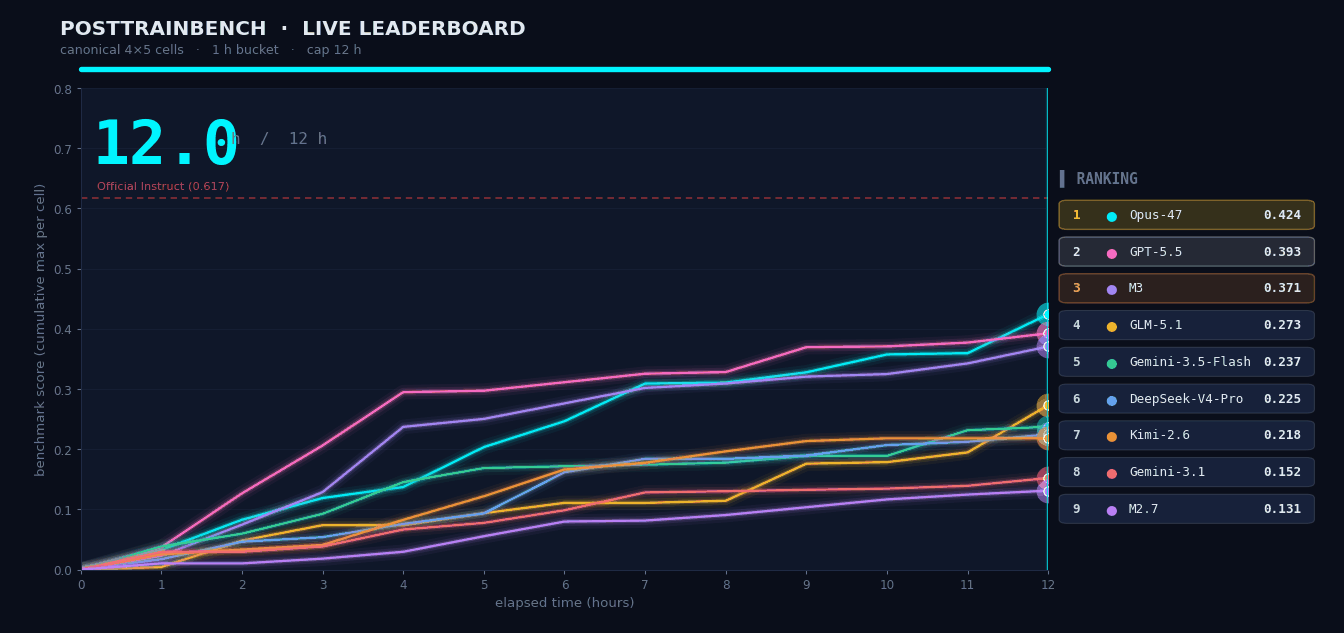
The most revealing test was PostTrainBench. M3 was given four pretrain-only base models with no downstream capabilities and told to autonomously complete data synthesis, training, evaluation, and iteration within 12 hours. The goal: enable these models to perform math reasoning, code generation, and knowledge QA.
The entire pipeline ran without human intervention. M3 scored 37.1, ranking third overall behind Opus 4.7 (42.4) and GPT-5.5 (39.3), but significantly ahead of all other models.
The Open-Weight Promise and the Skepticism
MiniMax claims M3 will be fully open-sourced on HuggingFace and GitHub, supporting private cluster deployment and fine-tuning. But the community has heard similar promises before.
The MiniMax M2 open-source coding agent evolution showed what’s possible when these models hit the open ecosystem. M2 disrupted pricing expectations and proved that open-weight models could compete with closed-source alternatives on agentic coding tasks.
The skepticism comes from the gap between “we’ll open-source it” and actual usability. Even if the weights drop, inference at this scale requires serious hardware. The previous MiniMax-2.5 open model performance demonstrated that quantization and local deployment are possible, but the community will be watching closely to see if M3 follows the same path.
The Pricing Disruption That Actually Matters
The $20/month Plus tier gets you roughly 1.7 billion tokens of M3 usage. For context, that’s enough to run serious agentic workloads for an entire development team.
The pricing structure is also smart. Calls with ≤512K input tokens are billed at the standard rate, covering most conversation and coding scenarios. Calls above 512K hit a higher long-context rate for ultra-long document parsing and full-repository code understanding.
M3 supports toggling thinking on or off, with the same pricing for both modes. This flexibility matters for developers who need fast responses for simple tasks and deep reasoning for complex agentic workflows.
The Competitive Landscape Shifts
The MiniMax M2.5 pricing disruption already showed that the economics of AI coding were changing. M3 accelerates that trend dramatically.
What’s different this time is the breadth of capability. Previous MiniMax models were strong at specific tasks but lacked the general intelligence of frontier models. A developer noted that M2.7 “was pretty good at agentic coding but was never a great ‘general’ agent”, it had one piece of Claude but not the whole picture.
M3 changes that calculus. It combines coding prowess, million-token context, and native multimodality in a single model that costs a fraction of the competition. The MiniMax M2.7 self-evolution capabilities hinted at what was possible, M3 delivers the full package.
The China’s AI agent strategy with MiniMax is now clearer than ever. MiniMax isn’t trying to win on benchmark scores alone, they’re winning on the cost-performance ratio that actually determines production adoption.
The Bottom Line
The model size remains unclear. Pricing suggests it could be in the 700B-1T parameter range, but MiniMax hasn’t confirmed. The API is 2x-4x more expensive than M2.7, which aligns with a significantly larger model.
But the benchmarks are real. The architecture is innovative. The pricing is aggressive.
The question isn’t whether M3 is good, it’s whether MiniMax can deliver on the open-weight promise and whether the ecosystem can translate these gains into production systems that work for real developers.
For anyone building agentic systems at scale, this is the model to watch. The math just changed, and the incumbents are going to feel the pressure.